在 App 評論、商品心得、或客服工單裡,「情緒」往往比字面資訊更能預測留存、轉換與滿意度。本篇用最實務的方式,一次帶你完成兩條常見路線:
最後我們還會給一個混合決策策略,讓詞典當快速外圍,模型主攻邊界與難例;並示範如何輸出可用於 HCI 的信心分數與關鍵詞貢獻。
| 方法 | 優點 | 缺點 | 何時用 |
|---|---|---|---|
| 情緒詞典(VADER、NRC、NTUSD…) | 免訓練、即時、可解釋(可輸出貢獻字詞) | 對語境與反諷不敏感、需補領域詞 | 原型、規則引擎、低延遲需求 |
| 情感分類器(TF-IDF+LR、BiLSTM、BERT…) | 語境理解佳、可遷移與持續學習 | 需資料/訓練、成本較高 | 追求準確率、處理複雜語境 |
詞典快且可解釋;模型準且可學習。實務常用「混合」:詞典先做低成本判斷/過濾,邊界樣本交給模型。
於終端機輸入:
pip install -U "transformers==4.41.*" "torch>=2.2" "datasets>=2.20" \
"vaderSentiment>=3.3" "scikit-learn>=1.4" "jieba>=0.42"
# 若在 Jupyter 看不到 tqdm 進度列,可安裝:
# pip install ipywidgets && jupyter nbextension enable --py widgetsnbextension
重要:本文所有程式碼都只走 PyTorch。若你同時裝了 TensorFlow/Keras 3,務必在 import transformers 之前加上:
import os
os.environ["TRANSFORMERS_NO_TF"] = "1"
VADER 會輸出 compound ∈ [-1,1],絕對值越大代表情感越強。
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
texts_en = [
"I love the new design!",
"It keeps crashing, terrible UX.",
"Kinda okay, a bit cluttered."
]
analyzer = SentimentIntensityAnalyzer()
print("=== Lexicon (VADER) ===")
for t in texts_en:
s = analyzer.polarity_scores(t) # compound ∈ [-1, 1]
print(f"{t} -> compound={s['compound']:.3f}")
輸出結果:
用 Hugging Face 上現成的已微調情緒模型,直接拿來推論。
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 自動選裝置(MPS > CUDA > CPU)
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
print("Device:", device)
英文 DistilBERT (SST-2):
en_model = "distilbert-base-uncased-finetuned-sst-2-english"
tok_en = AutoTokenizer.from_pretrained(en_model)
mdl_en = AutoModelForSequenceClassification.from_pretrained(en_model).to(device)
def predict_en(texts, max_len=128):
enc = tok_en(texts, truncation=True, max_length=max_len, padding=True, return_tensors="pt")
enc = {k: v.to(device) for k, v in enc.items()}
with torch.no_grad():
probs = torch.softmax(mdl_en(**enc).logits, dim=-1).cpu().numpy()
return probs # [:,1] = P(positive), [:,0] = P(negative)
print("\n=== Model (DistilBERT) ===")
for t, p in zip(texts_en, predict_en(texts_en)):
print(f"{t} -> pos={p[1]:.3f} neg={p[0]:.3f}")
中文 RoBERTa (JD 二分類):
zh_model = "uer/roberta-base-finetuned-jd-binary-chinese"
tok_zh = AutoTokenizer.from_pretrained(zh_model)
mdl_zh = AutoModelForSequenceClassification.from_pretrained(zh_model).to(device)
print("id2label (ZH):", mdl_zh.config.id2label) # 確認 0/1 對應情緒
def predict_zh(texts, max_len=128):
enc = tok_zh(texts, truncation=True, max_length=max_len, padding=True, return_tensors="pt")
enc = {k: v.to(device) for k, v in enc.items()}
with torch.no_grad():
probs = torch.softmax(mdl_zh(**enc).logits, dim=-1).cpu().numpy()
return probs
texts_zh = ["介面很漂亮", "常常閃退", "不太好用,但也不是最糟"]
print("\n=== Model (Chinese RoBERTa) ===")
for t, p in zip(texts_zh, predict_zh(texts_zh)):
print(f"{t} -> probs={p}")
輸出結果: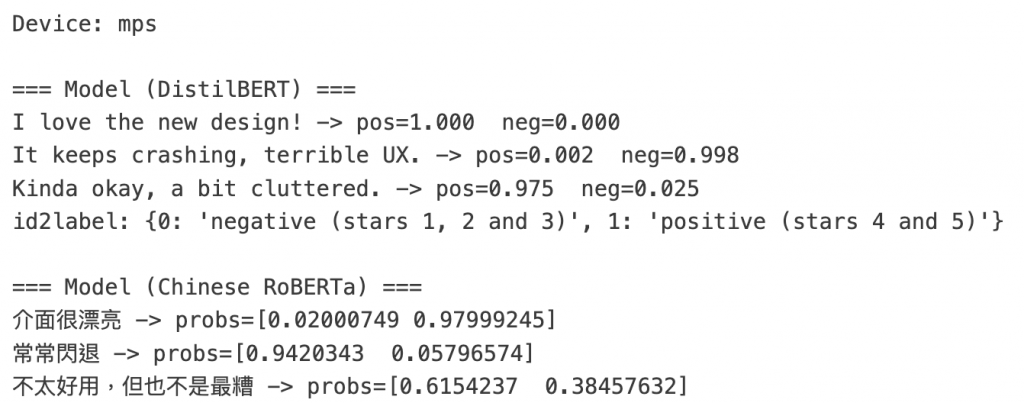
規則:
|compound| ≥ 0.70)→ 直接採用(快又可解釋)P(pos) ≥ 0.70 或 ≤ 0.30)→ 直接採用uncertain,可提示使用者補充或丟人工複核def hybrid_decision(lex_compound, model_pos, hi=0.70, lo=0.30):
if abs(lex_compound) >= hi:
return ("positive" if lex_compound > 0 else "negative", 0.90, "lexicon-strong")
if model_pos >= (1-lo) or model_pos <= lo:
conf = max(model_pos, 1 - model_pos)
return ("positive" if model_pos >= 0.5 else "negative", float(conf), "model-strong")
return ("uncertain", 0.55, "need-more-evidence")
print("\n=== Hybrid (VADER + DistilBERT) ===")
probs_en = predict_en(texts_en)
for t, p in zip(texts_en, probs_en):
lex = analyzer.polarity_scores(t)["compound"]
label, conf, source = hybrid_decision(lex, p[1])
print(f"{t} -> {label} (conf={conf:.2f}, source={source}, lex={lex:.3f}, pos={p[1]:.3f})")
輸出結果:
示範用 jieba + 小型自定詞庫,回傳關鍵詞及貢獻分數,便於 HCI 顯示。
import jieba
POS = {"順暢":1.2, "好用":1.5, "穩定":1.0, "流暢":1.2, "漂亮":1.2, "不卡":1.2}
NEG = {"卡頓":-1.5, "閃退":-2.0, "慢":-1.0, "糟":-1.2, "醜":-1.2, "當機":-1.8}
NEGATORS = {"不","沒","無","別","不是","不太","沒有"}
BOOSTERS = {"非常":1.5,"超級":1.6,"有點":0.7,"有些":0.8,"有點兒":0.7}
def lexicon_score_zh(text, return_contrib=False):
toks = list(jieba.cut(text))
score, contribs = 0.0, []
for i, w in enumerate(toks):
base = POS.get(w,0) + NEG.get(w,0)
if base == 0:
continue
if i > 0 and toks[i-1] in BOOSTERS:
base *= BOOSTERS[toks[i-1]]
window = toks[max(0,i-3):i]
if any(n in window for n in NEGATORS):
base *= -0.8
score += base
contribs.append((w, round(base,2)))
score = max(-1.0, min(1.0, score/5.0)) # 縮放到 [-1,1]
return (score, contribs) if return_contrib else score
print("\n=== 中文詞典(可解釋) ===")
for s in ["這次更新很順暢", "不太好用,常常卡頓", "UI有點亂但還能接受"]:
sc, ks = lexicon_score_zh(s, return_contrib=True)
print(s, "=>", sc, "| keywords:", ks)
輸出結果:


 iThome鐵人賽
iThome鐵人賽