昨天我們提到了 Chroma 團隊發現的「Context Rot」現象——AI 模型的記憶會隨著輸入文本增長而腐化。今天我們深入這個令人震驚的實驗現場,看看研究人員是如何揭露這個「圖書館」的黑暗秘密。
傳統的「大海撈針」測試太簡單了,就像在字典裡找特定詞彙一樣直接。但現實世界需要的是語意理解,不是詞彙配對。

研究團隊設計了不同相似度的問答對:
高相似度 (容易):
問題:「什麼是最佳的寫作建議?」
針:「最好的寫作技巧是每週寫作。」
低相似度 (困難):
問題:「哪個角色去過赫爾辛基?」
針:「Yuki 住在基亞斯瑪博物館旁邊。」
(需要知道基亞斯瑪博物館在赫爾辛基)
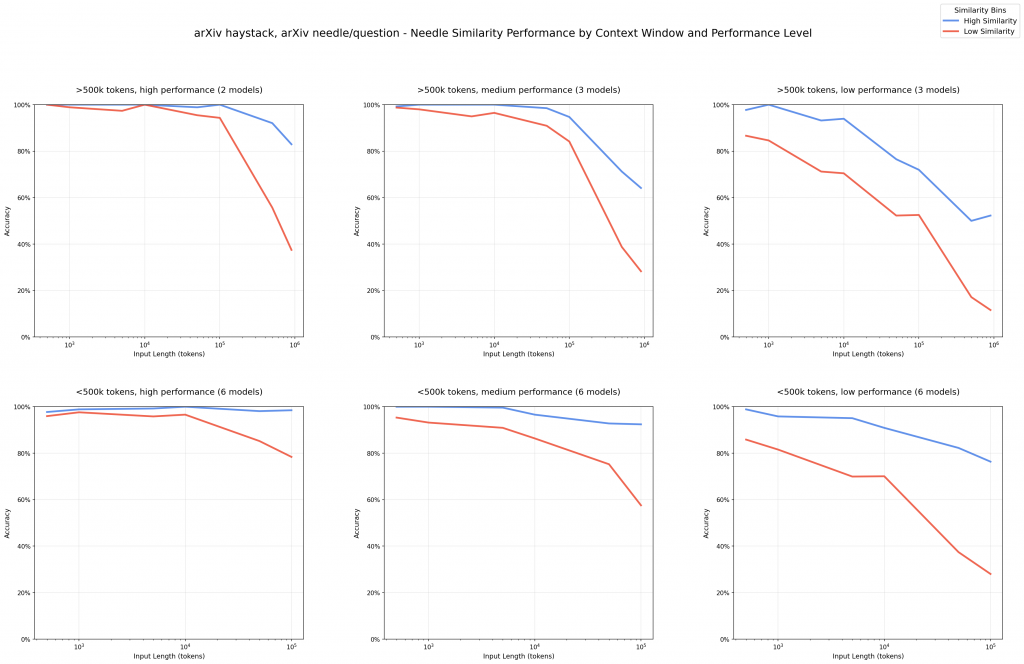
發現:隨著文本越來越長,低相似度問答對的準確率急速下降。AI 不只是在海量資訊中迷路,更在語意理解上徹底翻車。
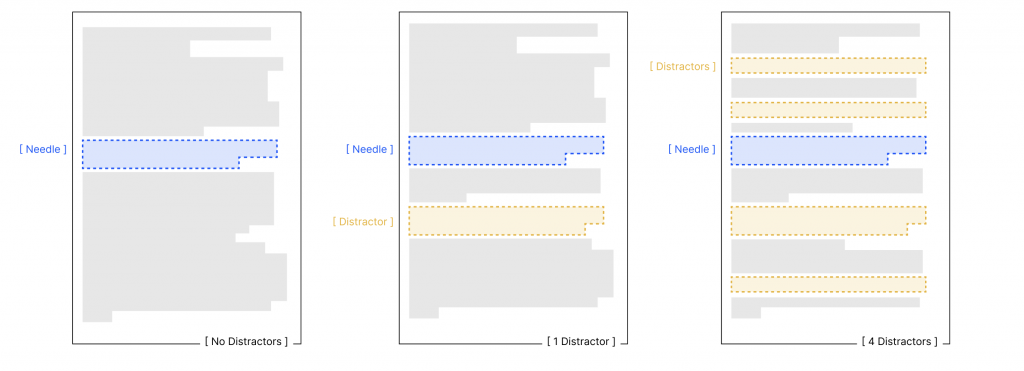
研究人員在正確答案周圍放置了精心設計的「干擾因子」:
問題:「我從大學同學那裡得到的最好寫作建議是什麼?」
正確答案:「每週寫作」
干擾因子們:
「我從大學教授那裡收到的最好建議是每天寫作」
「我從大學同學那裡得到的最差建議是用五種風格寫作」
「我從高中同學那裡得到的建議是用三種風格寫作」
「我以前認為從同學那裡得到的建議是用四種風格寫作」
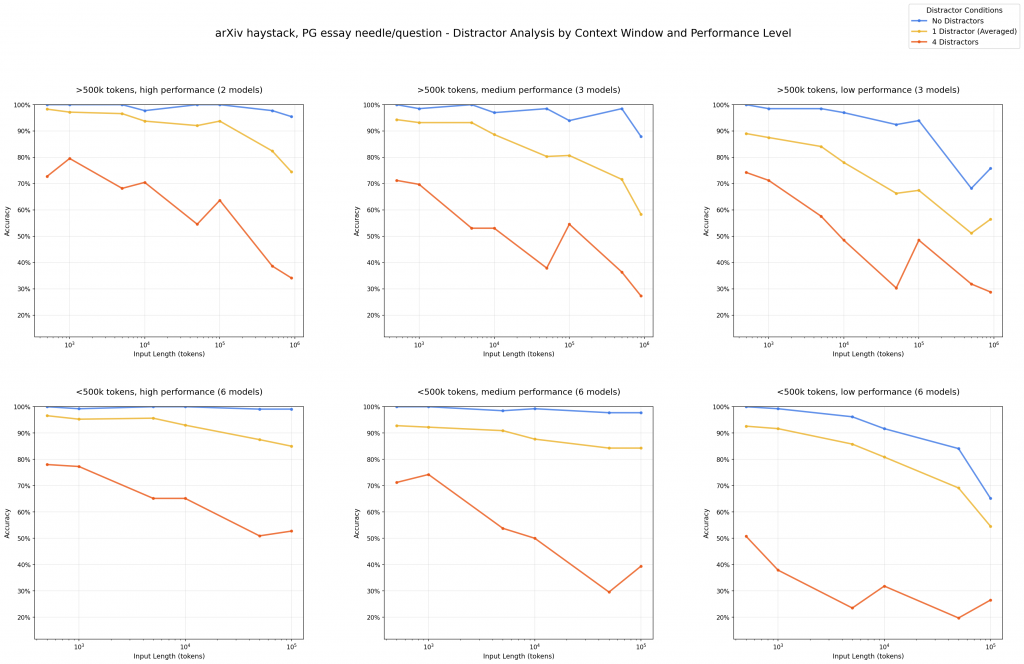
殘酷真相:即使只有一個干擾因子,模型表現就開始下滑。四個干擾因子一起上陣時,連最先進的模型都開始「睜眼說瞎話」,自信滿滿地給出錯誤答案。
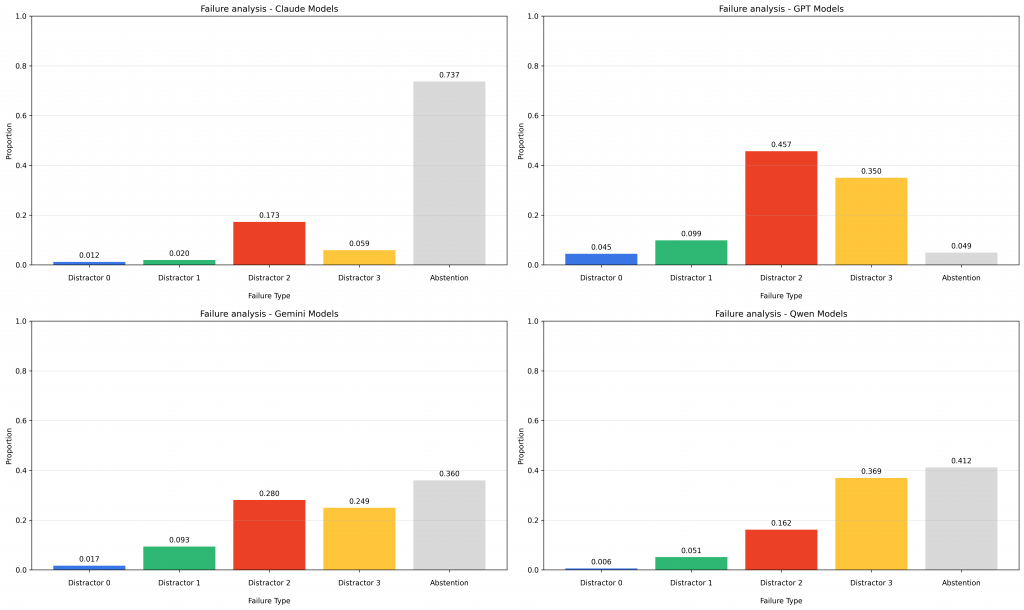
有趣的是,不同模型的「人格缺陷」 開始顯現:
Claude 家族:比較保守,不確定時會坦承「找不到答案」
GPT 家族:最愛幻覺,經常給出自信但完全錯誤的回答

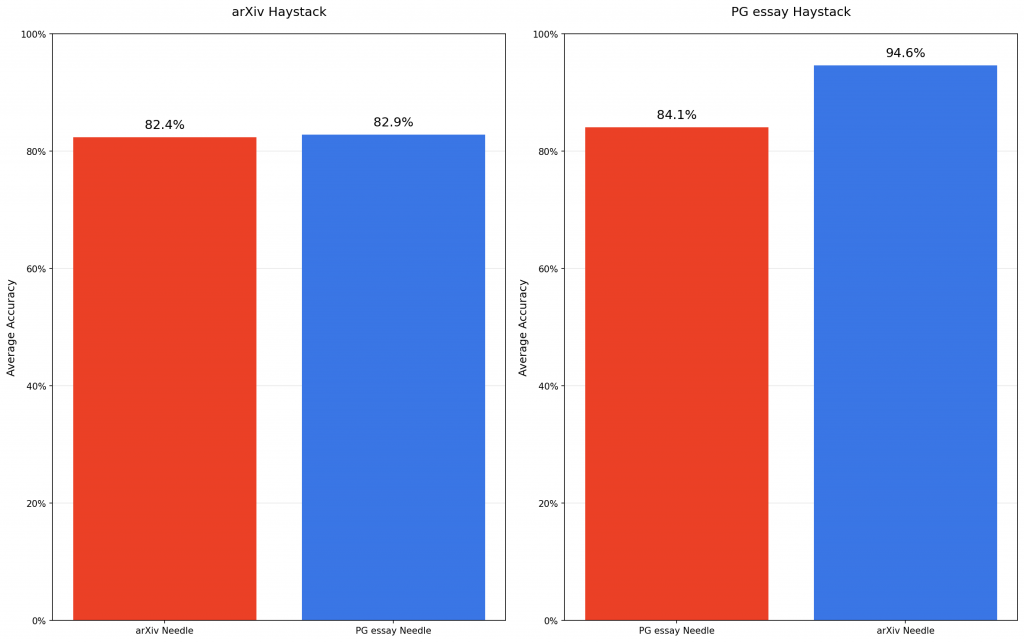
這個實驗測試了一個有趣問題:如果「針」(答案) 和「草堆」(背景文檔) 的主題不搭,會怎麼樣?
研究人員使用了兩種截然不同的背景文檔:
Paul Graham 文章:談創業、寫作、生活哲學
arXiv 學術論文:技術性、學術性內容
然後為每種背景設計對應的問題,測試主題匹配度對表現的影響。
意外發現:背景主題的影響比預期小很多!AI 似乎能夠在不相關的背景中找到答案,不會因為「文不對題」就大幅度翻車。

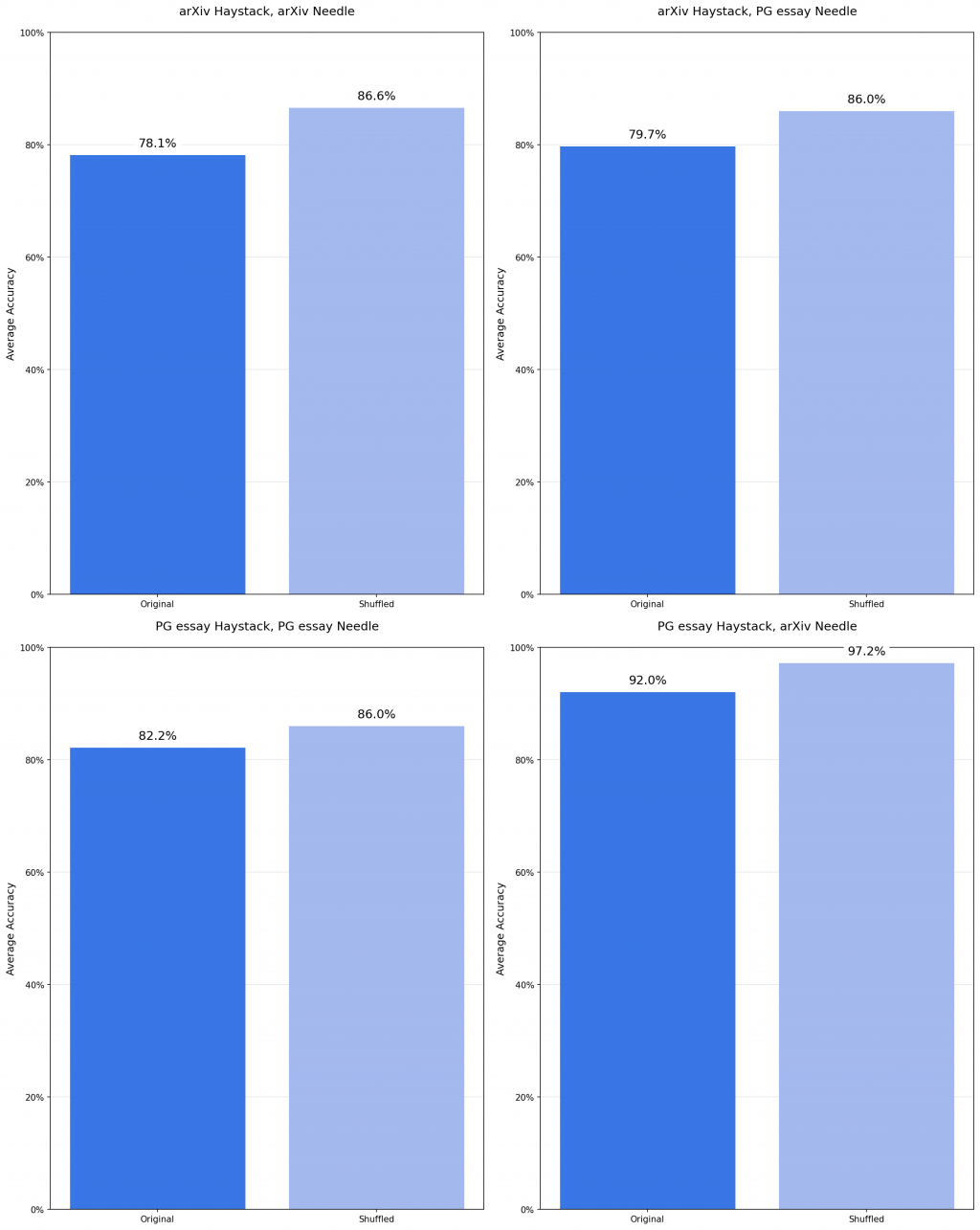
研究人員設計了兩種草堆:
原始結構:保持每篇文章的自然邏輯流,就像整齊排列的圖書館
打亂結構:將所有句子隨機重新排序,內容相同但失去邏輯連續性
驚人發現:打亂結構的文檔表現竟然有時候更好!這完全顛覆了「AI 需要邏輯順序」的直覺。
今天內容有點多了,明天讓我們再繼續看看這篇報告額外的兩個實驗。


 iThome鐵人賽
iThome鐵人賽