今天接續把這篇研究說完
昨天在實驗(一)有提到,團隊認為原本的大海撈針測試太簡單了。
於是有再設計幾個需要思考、推論的方法來測試模型是否能找出正確答案。
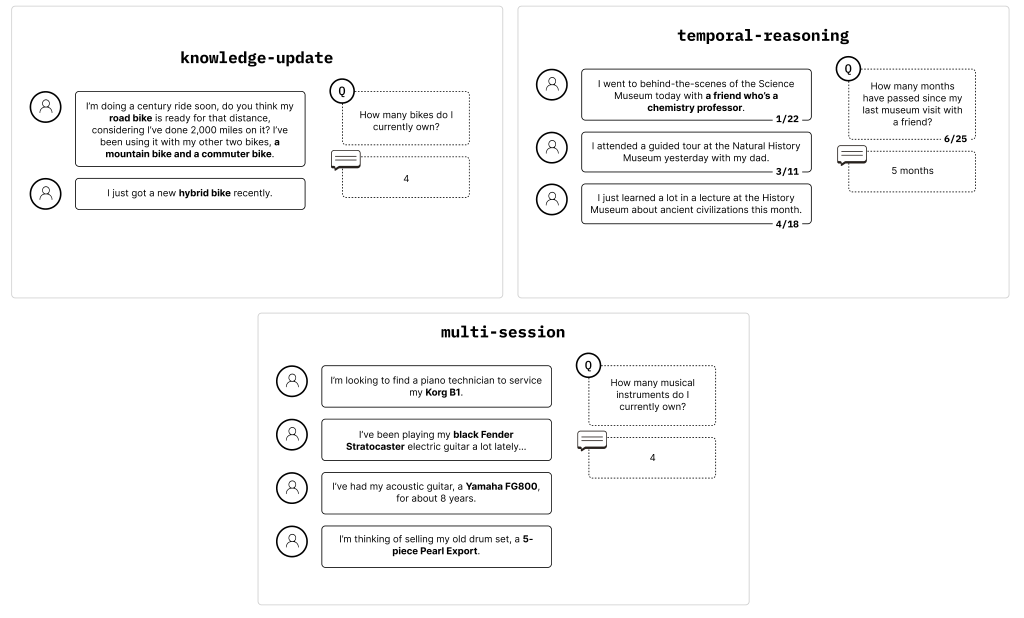
大致可分為:
實驗還分成兩種難度:其一是僅給出關鍵訊息要求推論;另一組是丟一大段文章,要模型從中尋找訊息並推論。
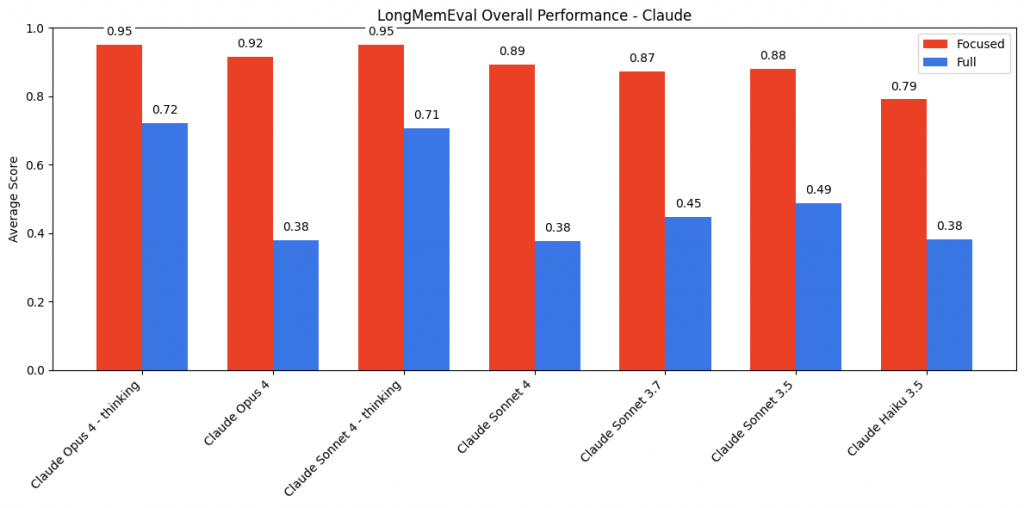
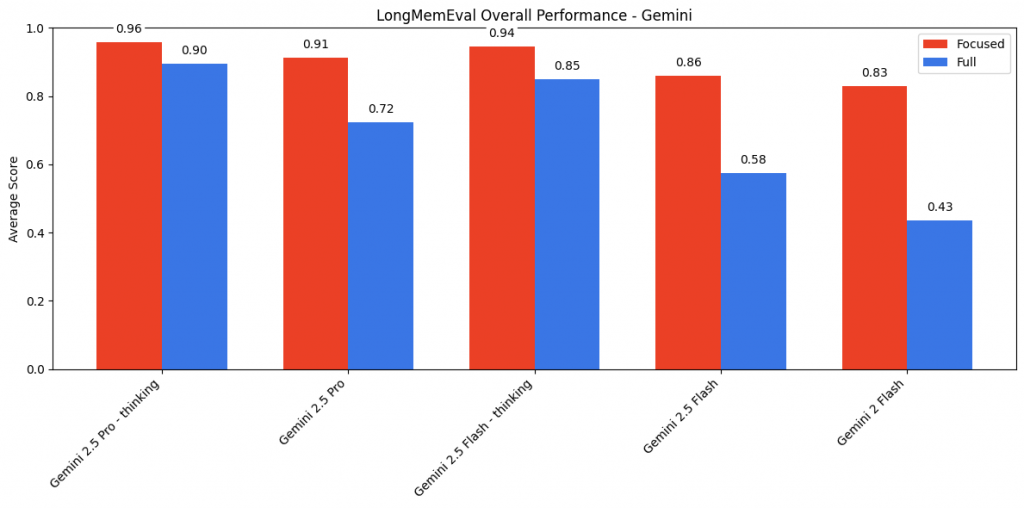
結果發現 think 模型普遍表現較佳,而只給精簡片段也對是否能推論出答案有很大的影響
而 claude 的差異更顯著,體現 claude 家族在回應上較保守。
最後他們測試了一個看起來極其簡單的任務:重複詞語測試。
這個實驗要求模型完全複製一段包含重複詞語的文字,其中只有一個位置插入了不同的詞語。
實驗設計
範例:apple apple apple apple apples apple apple apple...
任務:完全複製這段文字,一字不漏
研究團隊測試了不同長度的序列(25到10,000個詞)和各種詞語組合,包括:
"apple" / "apples"
"golden" / "Golden"
"San Francisco" / "sf"
"Golden Gate Bridge" / "Golden Gate Park"
雖然看起來是連小學生都會的複製貼上,但隨著序列變長,所有模型都出現顯著的效能衰退。
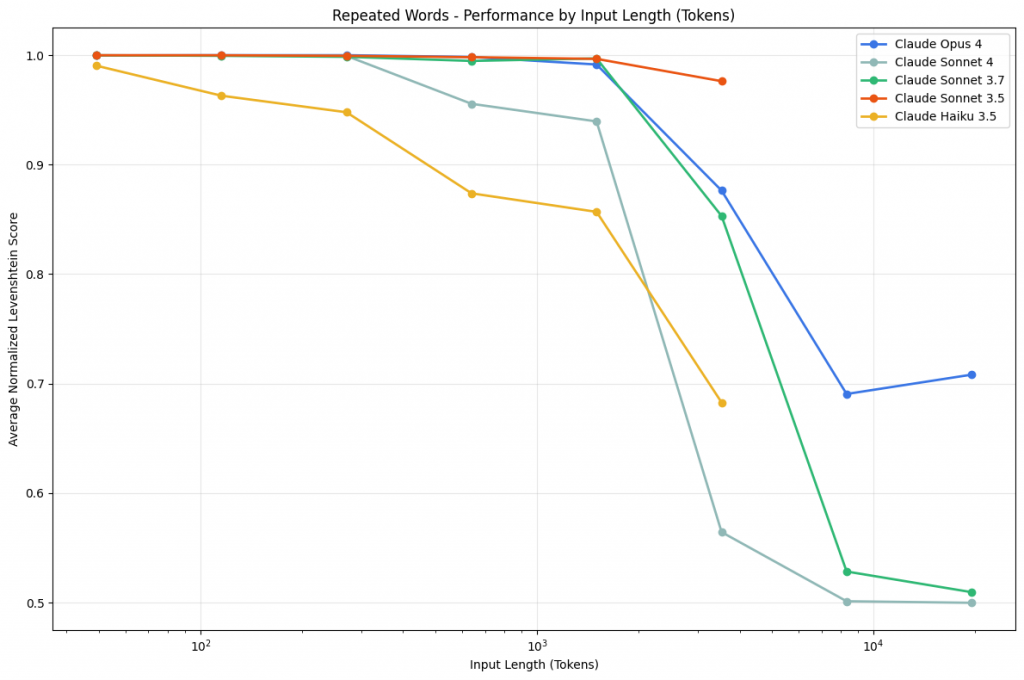
各模型的特殊表現:
Claude Opus 4:會因擔心版權問題而拒絕執行(2.89%拒絕率),有時會先分析文本再決定是否進行
GPT系列:在特定長度出現性能峰值,但也會產生原文中不存在的隨機詞語
Gemini系列:從500-750詞開始出現隨機輸出,如奇怪的符號組合
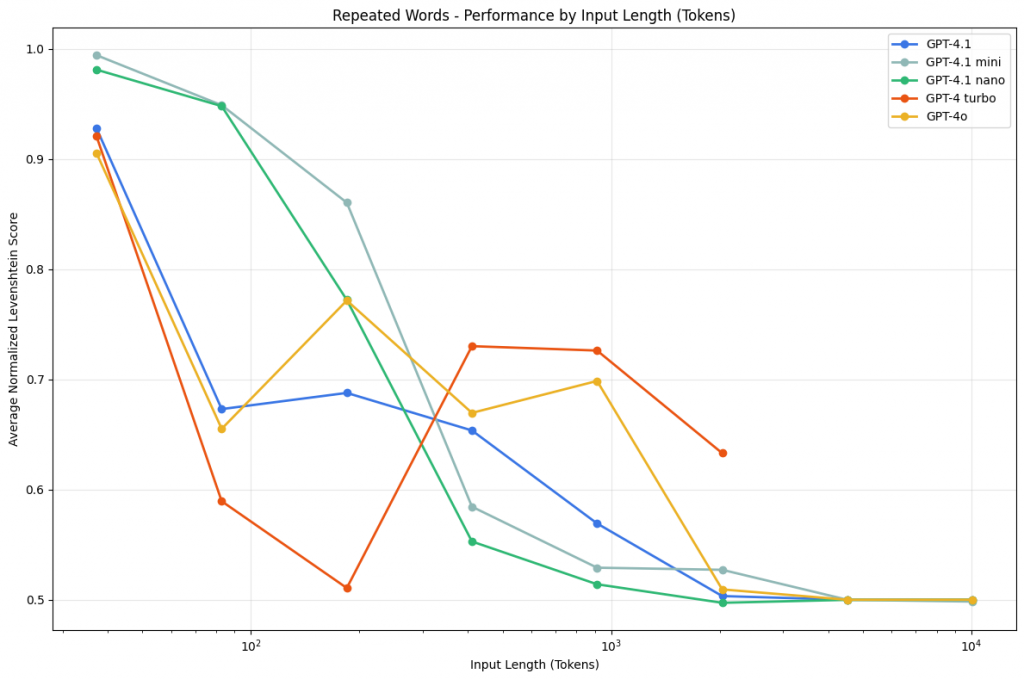
這個實驗揭示了現代大型語言模型的一個根本限制:即使是最先進的模型,在處理長序列的精確複製時也會遭遇困難。這不是智慧或推理能力的問題,而是模型架構本身在處理長序列時的固有限制。
經過這三天深入 Chroma 團隊的研究現場,我們見證了一個令人震撼的事實:那些被吹捧為擁有「無限記憶」的超大上下文窗口 AI,其實都有著致命的阿基里斯腱。
我們發現了什麼?
不是記憶體越大就越強。AI 的記憶就像一個會漏水的容器,放進去的資訊越多,流失的也越多。這不是 bug,是 feature——模型設計的根本限制。
就像人類在嘈雜環境中難以專注,AI 面對相似但錯誤的資訊時,也會被徹底混淆。一個精心設計的假訊息,就能讓最聰明的 AI 開始胡言亂語。
連複製貼上這種小學生都會的事,在長文本面前都變成了不可能任務。這提醒我們:AI 的「智慧」和人類的智慧是截然不同的東西。
這些研究告訴我們,想要成為優秀的 AI 煉金師,不能再有以下幻想:
❌ 「丟更多資料進去就會更準確」
✅ 資訊品質比資訊數量更重要
❌ 「AI 會自動理解所有上下文」
✅ 需要主動引導 AI 的注意力到關鍵資訊上
❌ 「長上下文窗口等於超強記憶」
✅ 設計精簡、結構化的提示比塞滿資料更有效
了解了 AI 記憶的限制後,我們就能開始設計真正有效的煉金配方。明天開始,我們將探討如何在這些限制下,依然能煉製出優質的 AI 輸出。


 iThome鐵人賽
iThome鐵人賽