我們的系統依賴外部的公共 RPC 節點,而這些外部服務並非 100% 可靠。它們可能會因為網路波動、暫時性過載、或我們的請求頻率過高 (Rate Limiting) 而短暫地無法回應。
如果我們不做任何處理,一次 RPC 的失敗就可能導致整個工作流中斷,我們也將錯過那一次的監控數據。一個健壯的系統,必須能夠優雅地處理這些預期內的「意外」。
n8n 提供了一個非常強大的內建功能,讓節點在執行失敗時可以自動重試幾次。這對於處理暫時性的網路問題特別有效。
找到核心節點:
在我們的錢包監控工作流中,最容易出錯的環節就是向外部發送請求的 HTTP Request 節點。請點擊它。
進入節點設定 (Settings):
在節點的設定面板中,除了我們常用的 Parameters 分頁外,旁邊還有一個 Settings 分頁。請點擊它。
啟用重試 (Retry On Fail):
在 Settings 分頁中,你會看到一個名為「Retry On Fail」的選項。
2 或 3。這代表如果節點第一次執行失敗,它會再嘗試 2 或 3 次。2000 (即 2 秒) 或 5000 (即 5 秒) 都是不錯的選擇,這給了遠端服務一個緩衝的時間。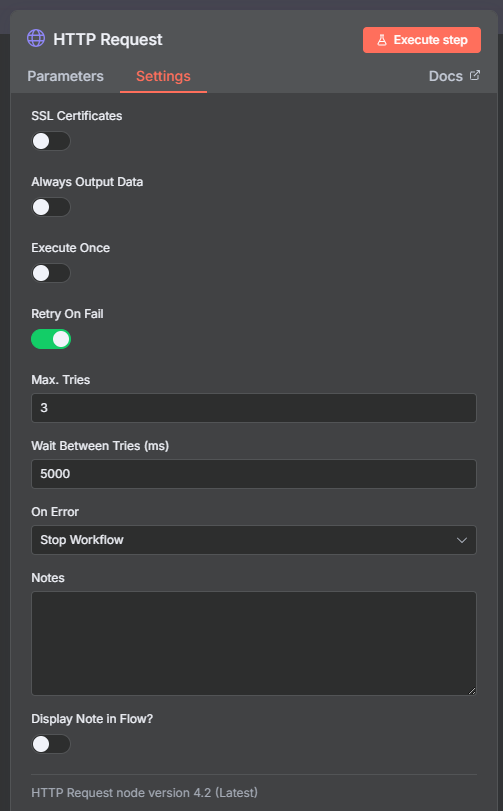
但如果重試了 3 次之後,節點依然失敗呢?這可能代表 RPC 服務徹底掛了,或者我們的請求被永久封鎖了。在這種情況下,我們需要立刻知道「系統出事了!」。
n8n 提供了一個非常優雅的機制來處理這種「最終錯誤」——Error Workflow。我們可以設定一個專門的「錯誤處理工作流」,當主工作流發生無法恢復的錯誤時,n8n 會自動觸發這個錯誤處理流程。
Error Trigger在這個新的「錯誤處理工作流」中,我們需要設定它的觸發器。
Start 節點。+ 按鈕,在搜尋框中輸入 Error,然後選擇 Error Trigger 這個節點。
現在,你可以像我們在 Day 7 教學中提到的那樣,在這個 Error Trigger 後面接上你的告警流程。
在 Error Trigger 後方新增一個 Discord 節點。
設定好你的 Webhook 憑證。
在 Message 欄位中,填入你想收到的告警訊息,你可以使用表達式來獲取詳細的錯誤資訊:
`text🚨 【緊急告警】 🚨
工作流執行失敗!
工作流名稱: {{ $workflow.name }}
錯誤節點: {{ $json.error.node.name }}
錯誤訊息: {{ $json.error.message }}
請立即檢查 n8n 系統!`
最重要的一步:將這個「系統錯誤告警處理」工作流設定為 Active 並儲存。(如果無法切成Active ,先在主作流右上角設定裡找到 Error Worlflow下拉式選單裡選擇 系統錯誤處理得工作流,再回來系統錯誤處理工作查查看,應該就可以切換成Active模式了)
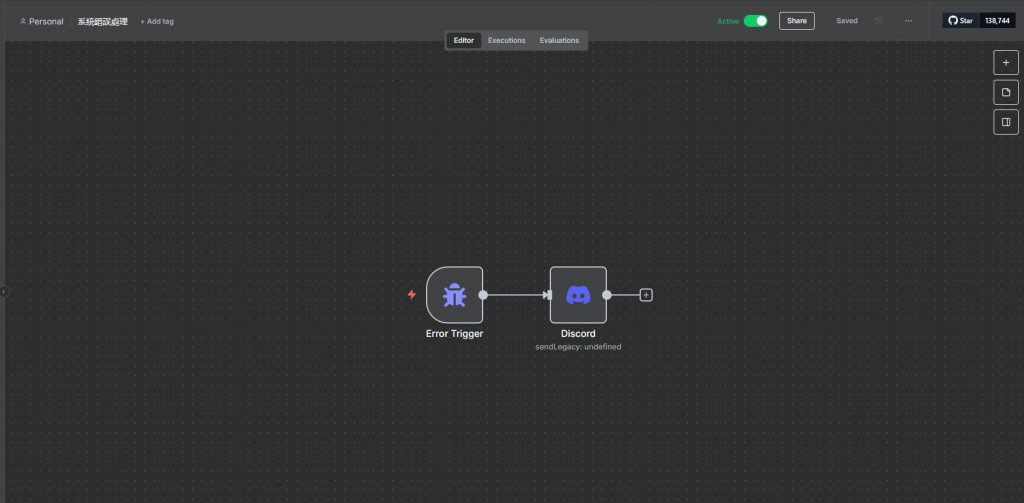
現在,我們已經有了一個待命的「錯誤處理專家」,接下來就是告訴我們的主工作流:「嘿,如果出事了,就去找他!」
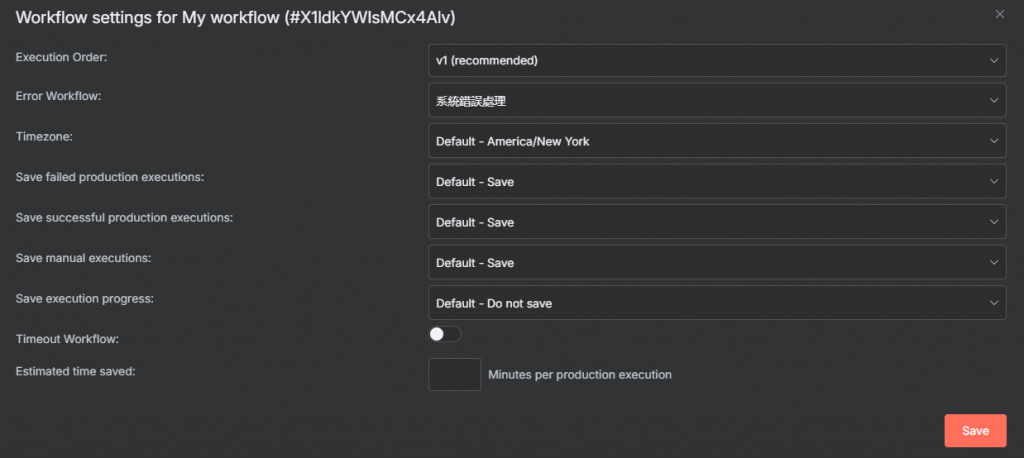
現在,你的主工作流就擁有了一個「安全網」。一旦它發生任何無法自行恢復的錯誤,你就會在第一時間收到詳細的告警通知。
恭喜你完成了第一週的挑戰!在這 7 天裡,我們:
你已經從零開始,打造出了一個雖然簡單、但五臟俱全的自動化監控系統。你掌握了 n8n 中最重要的幾個核心概念,為接下來更進階的挑戰打下了堅實的基礎。
下週預告 (Week 2):從下週一(Day 8)開始,我們將進入更有趣的「資料監控實戰」階段。我們將不再滿足於查詢餘額,而是要開始監控交易紀錄,並實作一個類似「Whale Alert (巨鯨告警)」的功能!


 iThome鐵人賽
iThome鐵人賽