前幾天已經練習了天氣 API和笑話 API。
今天會換成比較有趣的題材:下載隨機的貓咪圖片並存檔。(誰可以拒絕貓咪呢?)
我將會透過這個練習,來學習如何處理圖片回應、正確存檔,以及加上錯誤處理。
跟之前處理的 JSON 文字資料不一樣,圖片是二進位檔案格式。
練習圖片 API 可以學會如何下載和保存二進位檔案,是個重要且實用的技能。
使用 CATAAS (Cat as a Service)
這個 API 網址是:https://cataas.com/cat
每次呼叫都會獲得一張隨機貓咪圖片。
不需要註冊或金鑰,使用門檻低。
1. 呼叫 API 取得圖片資料
從 API 拿到的資料會包含圖片本身,這些資料是二進位資料,不是文字。
API 回傳時會有 Content-Type 標頭,告訴我們圖片的格式是什麼,例如 image/jpeg、image/png 或 image/webp。
2. 判斷檔案格式
根據 API 回傳的 Content-Type,決定圖片檔案的副檔名是 .jpg、.png 還是其他格式。
3. 把圖片資料存成檔案
用二進位寫入模式打開檔案(例如 cat.jpg),把拿到的圖片資料寫進去,這樣程式就會把圖片保存到本地。
4. 顯示下載完成訊息
圖片成功存檔後,可以印出提示,告訴我們圖片已經下載好了。
建立一個資料夾 day10。
在 day10 資料夾裡,建立程式檔案 day10_cat_download.py。
再建立一個 images 資料夾,用來放下載回來的圖片檔案。
mkdir day10
cd day10
ni day10_cat_download.py
mkdir images
用 requests 套件發送 requests.get(url) 抓取隨機貓咪圖片資料。
開一個新檔案 images/cat.jpg,用二進位寫入模式打開。
再把 API 回來的圖片內容 r.content(二進位資料)寫進去。
這樣就會在 images 資料夾裡存出一張貓咪圖片。
# day10_cat_download.py
import requests
url = "https://cataas.com/cat" # 隨機貓圖,免金鑰
r = requests.get(url, timeout=10)
r.raise_for_status() # 不是 2xx 會丟錯
with open("images/cat.jpg", "wb") as f:
f.write(r.content)
print("已下載:images/cat.jpg")
執行結果:
已下載:images/cat.jpg
可以在day10的資料夾裡,看到images 資料夾,再從中看到隨機生成的貓咪圖片。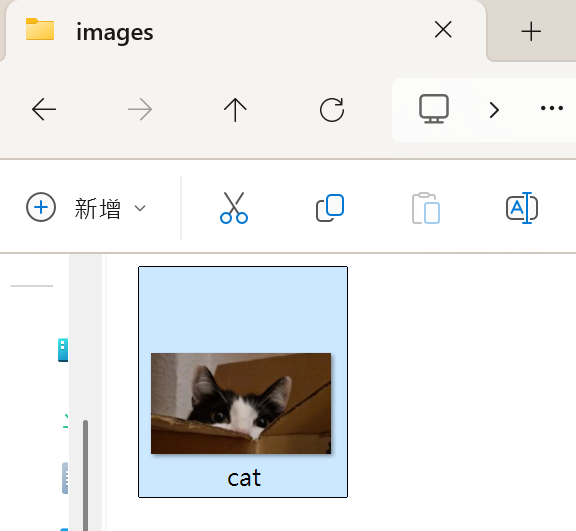
接下來是練習增加自動判斷副檔名、錯誤處理、流式下載等功能。
(流式下載就是把伺服器資料拆成小區塊逐段接收並邊收邊處理,不用一次載入整個檔案。)
import os # 管檔案路徑與資料夾
import time # 處理時間延遲
from datetime import datetime # 拿現在時間、做時間字串
import requests
CAT_URL = "https://cataas.com/cat" # 每次呼叫都會回一張新的貓圖
SAVE_DIR = "images" # 圖片要存到 images 資料夾。
EXT_BY_CONTENT_TYPE = {
"image/jpeg": ".jpg",
"image/jpg": ".jpg",
"image/png": ".png",
"image/gif": ".gif",
"image/webp": ".webp",
}
伺服器會回應「這是什麼格式」;我們就用對應的副檔名來存。
如果沒對應到,就預設用 .jpg。
def pick_ext(resp) -> str:
ct = (resp.headers.get("Content-Type") or "").split(";")[0].lower()
return EXT_BY_CONTENT_TYPE.get(ct, ".jpg") # 不識別就用 .jpg
從回應標頭抓 Content-Type,例如 image/jpeg,拿來查表決定副檔名。
def download_cat(save_dir=SAVE_DIR, url=CAT_URL, timeout=15):
os.makedirs(save_dir, exist_ok=True) # 沒有 images 也沒關係,自動幫忙建立。
try:
# 用 stream=True 邊收邊寫,比一次讀完省記憶體
with requests.get(url, timeout=timeout, stream=True) as r: # 發出請求去抓圖
timeout 防止卡住,stream=True 開啟流式下載(一塊一塊寫檔,省記憶體)。
r.raise_for_status()
ext = pick_ext(r)
# 用時間當檔名,避免覆蓋;加上毫秒防同秒重名
ts = datetime.now().strftime("%Y%m%d_%H%M%S_%f")[:-3]
filename = f"cat_{ts}{ext}"
path = os.path.join(save_dir, filename)
依回應決定副檔名。
用時間當檔名,檔案就不會互相覆蓋,像:cat_20250922_153012_847.jpg。
total = 0 # 準備一個計數器,記錄目前已經寫入了幾個位元組
with open(path, "wb") as f: # 以二進位寫入打開要存的檔案路徑 path。
for chunk in r.iter_content(chunk_size=8192):
# 從網路回應 r 裡一塊一塊拿資料(每塊 8192 bytes ≈ 8KB)。
if chunk: # 有些情況可能拿到空資料塊,這行用來略過空的。
f.write(chunk) # 把拿到的這塊資料寫進檔案。
total += len(chunk)
# 把這塊資料的大小加到 total,累積出整個檔案的總 bytes。
print(f"已下載:{path}({total} bytes)")
return path # 把剛存好的檔案路徑回傳
except requests.exceptions.Timeout:
print("逾時:伺服器回應太慢,稍後再試")
except requests.exceptions.ConnectionError:
print("連線錯誤:請檢查網路或網址")
except requests.exceptions.HTTPError as e:
status = e.response.status_code if e.response else "N/A"
print(f"伺服器錯誤(HTTP {status}):{e}")
except Exception as e:
print(f"其他錯誤:{e}")
return None
if __name__ == "__main__":
直接跑檔案時就下載一張圖。
執行結果:
已下載:images\cat_20250922_220902_278.jpg(202414 bytes)
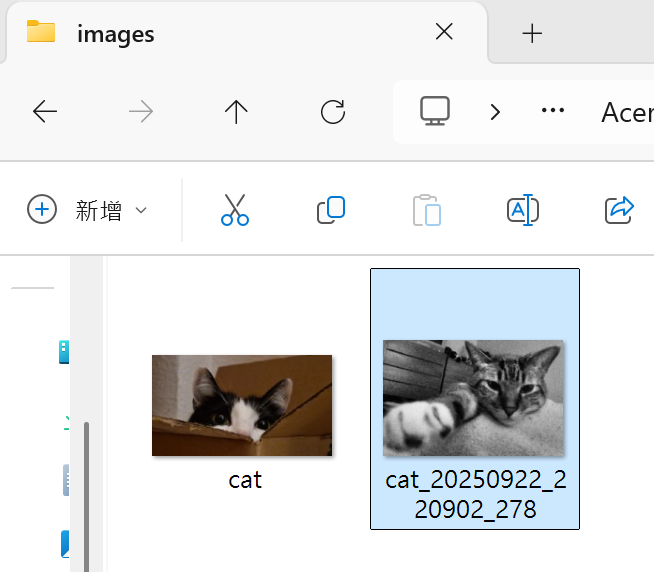
怎麼連續下載多張圖?
if __name__ == "__main__":
for _ in range(3): # 用 for 迴圈一次下載多張圖片
download_cat()
time.sleep(0.5) # 每次下載後加入 time.sleep() 暫停,避免請求太頻繁被伺服器擋掉
這裡是練習連續下載三張圖。
執行結果:
已下載:images\cat_20250922_221914_113.jpg(153131 bytes)
已下載:images\cat_20250922_221919_038.jpg(73846 bytes)
已下載:images\cat_20250922_221924_362.jpg(51733 bytes)
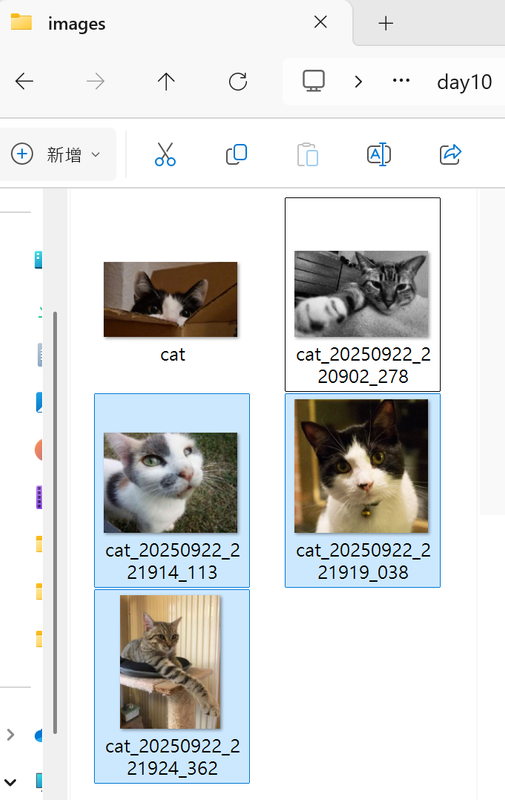
學會處理 API 回傳的圖片
學會存檔到本機並自動命名
學會用 try-except 安全包裝圖片下載

