在做情緒人臉辨識(Landmark detection)這塊,現有的人臉識別API有分成Dlib、FaceNet或DeepFace。
在這裡想用可以載入多種預訓練模型的DeepFace嘗試,當然預訓練模型不如從頭構建的模型靈活,但是可以更敏捷的套用。這篇文章引用了DeepFace的經典《 DeepFace:縮小人臉驗證與人類水平表現的差距》2014,有興趣的人可以去看原文。
PS.
這三種API的優缺點比較可見邦友文章:30天AI人臉辨識技術全攻略:從零開始到實戰應用 DAY12
另外,想見FaceNet的人可以在人臉辨識(Face recognition) 解析與實作見到高品質的檢測結果。
DeepFace 是一個由 Facebook AI Research 和特拉維夫大學於 2014 年提出的深度學習系統,旨在縮小人臉驗證(Face Verification)性能與人類水平之間的差距。
DeepFace和其他人臉識別API都是多階段方法,主要特色在於結合了精確的 3D 臉部對齊和DNN來學習人臉特徵。
(引用自《 DeepFace:縮小人臉驗證與人類水平表現的差距》2014)
• 訓練數據:DeepFace 在當時最大的帶標籤人臉數據集 SFC(Social Face Classification)上進行訓練,該數據集包含來自 4,030 個身份的 440 萬張帶標籤人臉圖像。大規模數據集是支撐其複雜網路架構的關鍵。
• 損失函數:網路是針對多類人臉識別任務進行訓練,使用 K 路 Softmax 作為輸出層,並使用交叉熵損失(Cross-entropy loss)進行最小化。
• 驗證性能:DeepFace 在 LFW(Labeled Faces in the Wild)資料集上取得了 97.35% 的準確度(使用多模型集成和非限制協議),將當時最優方法的錯誤率降低了超過 27%,接近人類水平的性能。
• 計算效率:DeepFace 系統在單核 Intel 2.2GHz CPU 上運行,整體處理一張圖像約需 0.33 秒,其中特徵提取(前饋網路)耗時 0.18 秒,3D 對齊耗時 0.05 秒。
以下要介紹
• DeepFace特色:對齊機制
• 網路架構(Siamese network)
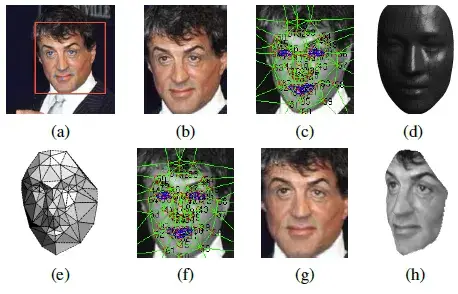
DeepFace 系統採用了多階段且複雜的對齊方式,特別強調使用顯式 3D 臉部建模來處理非受限環境下的人臉變異。
DeepFace 的對齊管道(Alignment Pipeline)包括以下步驟:
2D 對齊 (2D Alignment)
對齊過程從檢測到的臉部開始,透過以下步驟進行初始對齊:
(a) 初始特徵點檢測: 系統首先在檢測到的臉部上定位 6 個初始特徵點(fiducial points),這些點集中在眼睛中心、鼻尖和嘴巴位置 [71(a), 75, 129(a)]。
(b)相似度變換: 使用這些點來計算一個相似度變換矩陣 $T_{2d}$,用於將圖像近似地進行縮放 (scale)、旋轉 (rotate) 和平移 (translate),留下一個 2D 對齊的剪裁(Bounding Box)。
(c) 2D 對齊裁剪上的67 個基準點及其對應的 Delaunay Triangulation,也就是把點連接封閉的區域切割成大小均勻分配的三角形。
(d)一個理想的 3D 臉部模型,根據圖像中人臉的實際角度和位置,繪製或投影到 2D 平面上的結果。
3D 對齊(Frontalization,正面化)
(e)為了解決平面外旋轉和姿態(pose)問題,DeepFace 引入了基於 3D 模型的方法:
◦ 更多特徵點檢測: 在 2D 對齊後的圖像上,定位額外的 67 個特徵點 [76, 129(c)]。
◦ 3D 模型擬合: 系統使用一個通用 3D 形狀模型(generic 3D shape model)(來自 USF Human-ID 資料庫的平均 3D 掃描結果)。透過這 67 個檢測到的 2D 特徵點,系統擬合一個仿射 3D-to-2D 攝影機 $P$。
◦ 利用擬合的攝影機 $P$ 和 3D 參考點,對 2D 圖像進行扭曲(warp)。
◦ 分段仿射變換(piece-wise affine transformation)$T$ 被用來將 2D 特徵點(源)扭曲到到3D 模型引導的目標點(target)。
(f) 這種扭曲是透過 Delaunay Triangulation 導引的,它基於 67 個特徵點 [78, 129(c), 129(f)]。
(g) 最終結果是**「最終正面化裁剪」 (final frontalized crop)** [71(g), 129(g)],它將人臉扭曲到一個 3D 正面模式。
(h)生成3D 正面模式
對齊的重要性
• 準確的基於模型的對齊(model-based alignment)。
• 減少變異: 對齊步驟旨在將人臉圖像正規化,補償姿態和非剛性表情帶來的變化。
• 定制網路架構: 網路架構(特別是局部連接層 L4、L5、L6)是基於輸入圖像已高度對齊的事實進行定制的。DeepFace 相信一旦對齊完成,人臉每個區域的位置在像素級別上是固定的。
• 性能影響: 實驗證明了 3D 對齊的重要性:僅使用 2D 對齊時,準確度為 $94.3%$;而加入 3D 正面化後,DeepFace 的單模型(DeepFace-single)準確度顯著提升至 $95.92%$(無監督)到 $97.00%$(受限協議)。
DeepFace 模型架構是一個九層深度神經網路(DNN),專為處理經過 3D 對齊的臉部圖像而客製化設計。該架構包含了超過 1.2 億個參數,其中超過 95% 的參數來自於局部連接層和全連接層。
該架構可以分為三個主要部分:低級特徵提取(C1-C3)、客製化局部連接(L4-L6)和高層全連接(F7-F8)。
以下是 DeepFace 網路架構的詳細描述:

實作目標: 實作Deepface專案初始和資料集準備
人臉訓練模型:參考自Real-time-Face-recognition
測試圖片:
Einstein_Angry.png
Einstein_laughing.png
(來源:gemini生成)
下載流程: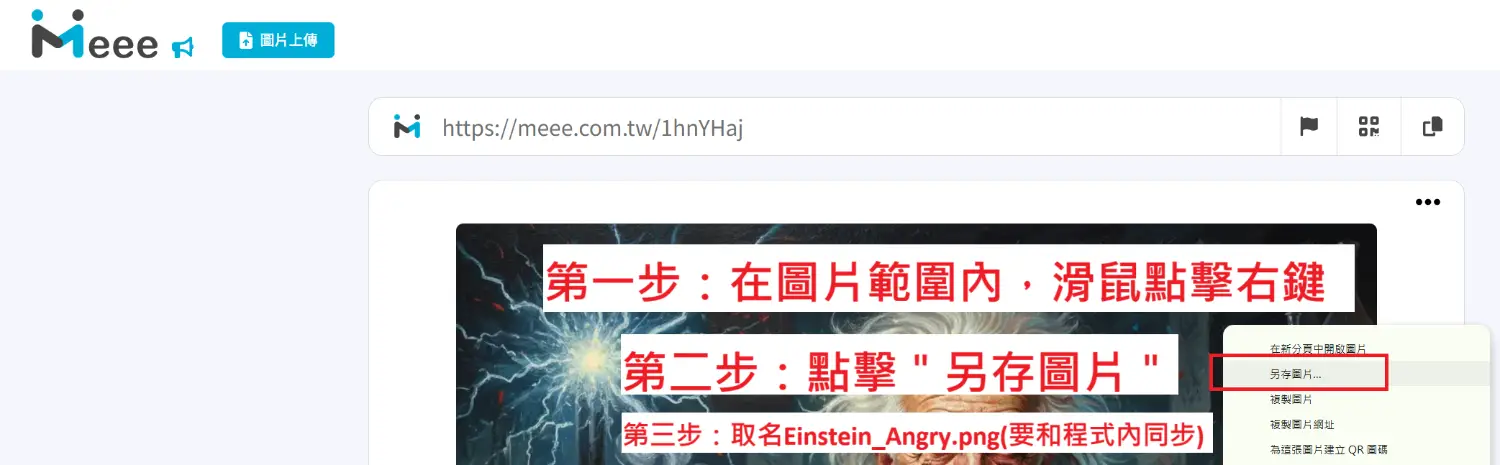
實作放在colab


 iThome鐵人賽
iThome鐵人賽