今天來講講要如何拿取我們要的資料 - scraper 服務
首先,我們先來大致規劃一下在這系統應該要紀錄什麼東西:
有了想拿到的目標資料 那我們就可以去實際觀察GU網站有什麼。
我們想拿到網站中的某些資料 並讓他能自動化拿取 那我們就必須先觀察它
實作步驟:
其實從URL可以看到我們要去的類別是 女裝全品類(women_all)
https://www.gu-global.com/tw/zh_TW/c/women_all.html
https://d.gu-global.com/tw/p/search/products/by-category
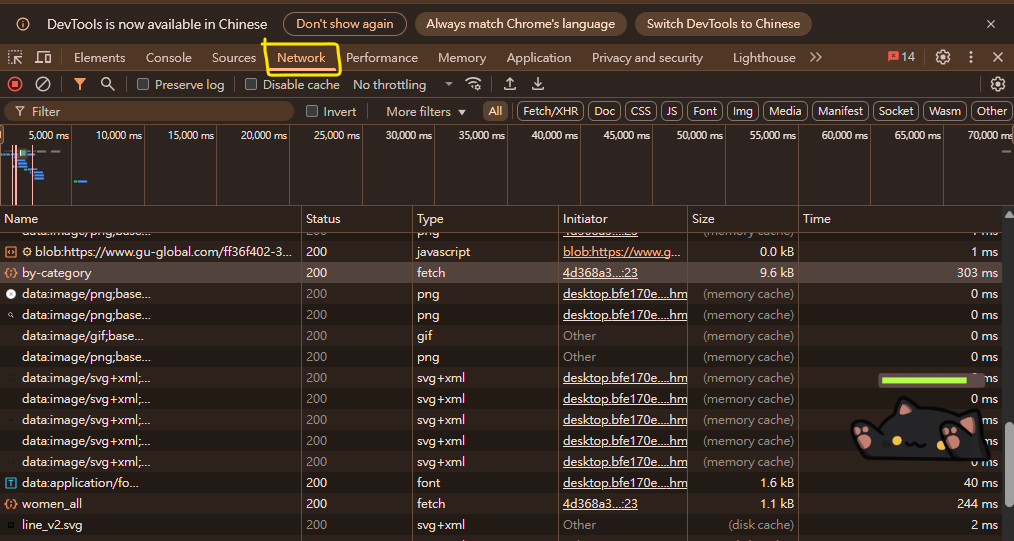
欄位如下:
{
"pageInfo": {
"page": 1,
"pageSize": 24
},
"belongTo": "pc",
"rank": "overall",
"priceRange": {
"low": 0,
"high": 0
},
"color": [],
"size": [],
"identity": [],
"exist": [],
"categoryCode": "women_all",
"searchFlag": false,
"description": "",
"stockFilter": "warehouse"
}
常見是 j["resp"](有時是陣列、有時是物件),主要重點欄位:productList:商品陣列productSum:分類下商品總數(用來算分頁)pageSize:後端實際回傳的每頁數

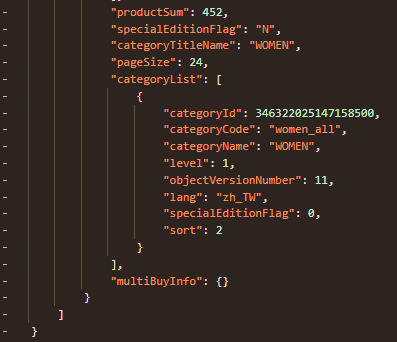
可以看到單件商品所有分類項目,我們要根據這裡的資料記錄到資料庫。
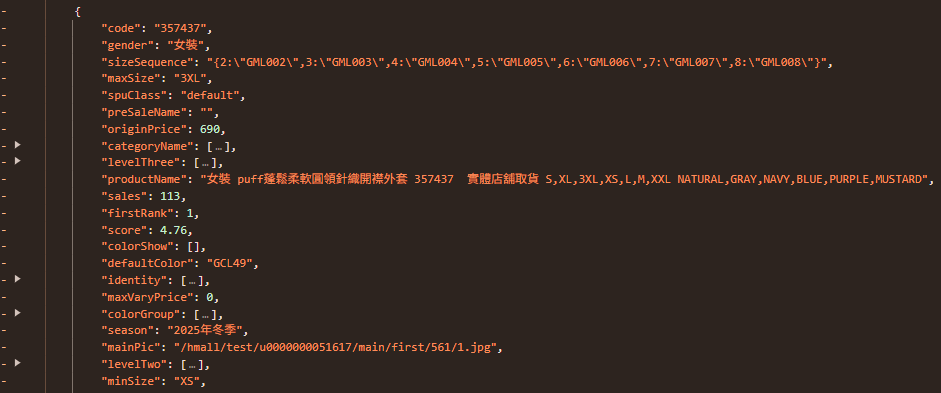
以下應用為學術使用,勿進行非法行為
GU 的 API 在 CDN/反爬層上,通常會期待:
程式做法:
https://www.gu-global.com/tw/zhTW/c/<category>.html
將抓取到的內容存入到CSV中
指令:
python gu_category_to_csv.py --category women_all --csv gu_women_all.csv
預期會看一個 gu_women_all.csv 和 terminal跳出以下訊息

gu_category_to_csv.py
import csv, math, time, requests, argparse, json, random
from datetime import datetime, timezone, timedelta
from urllib.parse import urljoin, urlparse
"""
GU category scraper → CSV / JSON
Notes:
- Respect the site's ToS and throttle responsibly.
- Pipeline: GET category page (set cookies) → POST list API with proper headers.
- Handles resp being list or dict; resilient to minor schema drift.
"""
TZ = timezone(timedelta(hours=8))
BASE_WEB = "https://www.gu-global.com"
BASE_API = "https://d.gu-global.com"
DEFAULT_CATEGORY = "women_all"
LIST_API = f"{BASE_API}/tw/p/search/products/by-category"
# Default headers; Referer is set dynamically per-category
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-TW,zh;q=0.9,en;q=0.8",
"Content-Type": "application/json;charset=UTF-8",
"Origin": BASE_WEB,
"Connection": "keep-alive",
}
def safe_num(x):
try:
return float(x)
except (TypeError, ValueError):
return None
def backoff(attempt, base=0.5, cap=8.0):
"""Exponential backoff with small jitter."""
return min(cap, base * (2 ** attempt)) + random.uniform(0, 0.2)
def fetch_list_page(session, category_code, page, page_size=24, stock_filter="warehouse", retries=3):
payload = {
"pageInfo": {"page": page, "pageSize": page_size},
"belongTo": "pc",
"rank": "overall",
"priceRange": {"low": 0, "high": 0},
"color": [],
"size": [],
"identity": [],
"exist": [],
"categoryCode": category_code,
"searchFlag": False,
"description": "",
"stockFilter": stock_filter,
}
for attempt in range(retries + 1):
try:
r = session.post(LIST_API, json=payload, timeout=20)
r.raise_for_status()
j = r.json()
# Some responses put useful data under j["resp"], which can be list or dict
resp = j.get("resp")
if isinstance(resp, list):
resp = resp[0] if resp else {}
elif not isinstance(resp, dict) or resp is None:
resp = j # fallback to root
products = (
resp.get("productList")
or resp.get("products")
or j.get("data", {}).get("productList")
or []
)
total = (
resp.get("productSum")
or resp.get("total")
or j.get("data", {}).get("pageInfo", {}).get("total")
or len(products)
)
# safer page_size: fall back and avoid 0
page_size_ret_raw = resp.get("pageSize") or page_size
try:
page_size_ret = int(page_size_ret_raw)
except Exception:
page_size_ret = page_size
if page_size_ret <= 0:
page_size_ret = page_size
return products, int(total), int(page_size_ret)
except (requests.RequestException, ValueError, json.JSONDecodeError):
if attempt == retries:
raise
time.sleep(backoff(attempt))
def normalize_row(p, base_url=BASE_WEB):
origin = safe_num(p.get("originPrice"))
minp = safe_num(p.get("minPrice"))
disc_pct = (
round((1 - (minp / origin)) * 100, 2)
if (origin and origin > 0 and minp is not None)
else None
)
cats = p.get("categoryName")
if isinstance(cats, list):
categories = "|".join(map(str, cats))
elif isinstance(cats, str):
categories = cats
else:
categories = ""
main_pic = p.get("mainPic") or ""
if main_pic:
main_img = main_pic if urlparse(main_pic).scheme in ("http", "https") else urljoin(base_url, main_pic)
else:
main_img = ""
return {
"timestamp": datetime.now(TZ).isoformat(timespec="seconds"),
"site": "GU",
"product_code": p.get("productCode"),
"code": p.get("code"),
"name": p.get("name"),
"min_price": minp,
"max_price": safe_num(p.get("maxPrice")),
"origin_price": origin,
"discount_pct": disc_pct,
"categories": categories,
"sex": p.get("gender") or p.get("sex"),
"season": p.get("season"),
"main_img": main_img,
}
def crawl_category(
category_code,
out_csv=None,
page_size=24,
delay=0.4,
json_out=False,
encoding="utf-8-sig", # Excel-friendly by default
):
s = requests.Session()
category_page = f"{BASE_WEB}/tw/zh_TW/c/{category_code}.html" # zh_TW (correct)
s.headers.update({**HEADERS, "Referer": category_page})
# Priming GET to set cookies on CDN/edge
s.get(category_page, timeout=20)
first, total, page_size_server = fetch_list_page(s, category_code, 1, page_size)
# Prefer server-reported page size when valid
effective_page_size = page_size_server if page_size_server and page_size_server > 0 else page_size
pages = max(1, math.ceil((total or 0) / max(1, effective_page_size)))
rows = [normalize_row(p) for p in first]
for page in range(2, pages + 1):
items, _, _ = fetch_list_page(s, category_code, page, effective_page_size)
rows += [normalize_row(p) for p in items]
time.sleep(max(0.2, delay) + random.uniform(0.0, 0.2))
if json_out:
print(
json.dumps(
{"ok": True, "category": category_code, "count": len(rows), "items": rows},
ensure_ascii=False,
)
)
else:
fieldnames = [
"timestamp",
"site",
"product_code",
"code",
"name",
"min_price",
"max_price",
"origin_price",
"discount_pct",
"categories",
"sex",
"season",
"main_img",
]
out_path = out_csv or f"gu_{category_code}.csv"
with open(out_path, "w", newline="", encoding=encoding) as f:
w = csv.DictWriter(f, fieldnames=fieldnames)
w.writeheader()
w.writerows(rows)
print(f"done. items={len(rows)}, pages={pages}, csv={out_path}")
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("--category", default=DEFAULT_CATEGORY, help="GU 類別代碼,如 women_all")
ap.add_argument("--csv", default=None, help="輸出 CSV 路徑;若未指定且未使用 --json,預設為 gu_<category>.csv")
ap.add_argument("--json", action="store_true", help="輸出 JSON 到 stdout(適合 n8n / pipeline)")
ap.add_argument("--page-size", type=int, default=24)
ap.add_argument("--delay", type=float, default=0.4, help="每頁抓取間隔秒數(基礎值,內含隨機抖動)")
ap.add_argument("--encoding", default="utf-8-sig", help="CSV 編碼(Excel 友善建議 utf-8-sig)")
args = ap.parse_args()
crawl_category(
args.category,
out_csv=args.csv or f"gu_{args.category}.csv",
page_size=args.page_size,
delay=args.delay,
json_out=args.json,
encoding=args.encoding,
)

