在 Day 11–18,我們的 PopularTop10 baseline 模型總是固定不變,無法體現「隨時間演化」。
今天我們要:
修改 PopularTop10:
每次 retrain 都會產生不同結果(透過 random_seed 控制隨機性)。
自動化 retrain(用 for loop + sleep 模擬定期 retrain)。
每次 run 都自動:
top10.json artifact,方便比較差異。📂 路徑:/usr/mlflow/src/pipeline/retrain.py
import os
import pandas as pd
import numpy as np
import json
import mlflow
import mlflow.pyfunc
from mlflow.tracking import MlflowClient
# === MLflow Tracking 設定 ===
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-cicd")
client = MlflowClient()
# === 載入資料 ===
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
# === Step 1: 計算平均分數 ===
agg = (
ratings_train.groupby("anime_id")["rating"]
.mean()
.reset_index()
.merge(anime[["anime_id", "name"]], on="anime_id")
)
# === Step 2: 熱門前 7 ===
top7 = agg.sort_values("rating", ascending=False).head(7)
# === Step 3: 隨機選 3 部 ===
random_seed = np.random.randint(0, 100000)
np.random.seed(random_seed)
random3 = agg.sample(3)
# === Step 4: 組合 Top10 ===
top10 = pd.concat([top7, random3]).drop_duplicates("anime_id").head(10)
top10_ids = top10["anime_id"].tolist()
top10_names = top10["name"].tolist()
print(f"Random Seed: {random_seed}")
print("Top 10 Anime:", top10_names)
# === PopularTop10 模型定義 ===
class PopularTop10(mlflow.pyfunc.PythonModel):
def __init__(self, anime_df, top10_ids):
self.anime = anime_df
self.top10_ids = top10_ids
def predict(self, context, model_input):
return [self.anime[self.anime["anime_id"].isin(self.top10_ids)]["name"].tolist()]
# === Step 5: Log + 註冊到 Registry ===
with mlflow.start_run(run_name="popular-top10-cron") as run:
# Log params
mlflow.log_param("model_type", "PopularTop10")
mlflow.log_param("random_seed", random_seed)
# Log artifact (Top10 JSON)
result = {"random_seed": random_seed, "top10": top10_names}
with open("top10.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
mlflow.log_artifact("top10.json")
# 註冊模型
result = mlflow.pyfunc.log_model(
artifact_path="model",
python_model=PopularTop10(anime, top10_ids),
registered_model_name="AnimeRecsysModel"
)
run_id = run.info.run_id
# === Step 6: Transition to Staging ===
latest_versions = client.get_latest_versions("AnimeRecsysModel", stages=["None"])
if latest_versions:
new_version = max([int(v.version) for v in latest_versions])
client.transition_model_version_stage(
name="AnimeRecsysModel",
version=new_version,
stage="Staging",
archive_existing_versions=False
)
print(f"✅ AnimeRecsysModel v{new_version} 已自動設為 Staging")
在容器裡執行以下指令:
for i in $(seq 1 3); do
python /usr/mlflow/src/pipeline/retrain.py
sleep 20
done
效果:
總共約 1 分鐘,你會在 MLflow UI → Models → AnimeRecsysModel 看到 三個不同版本。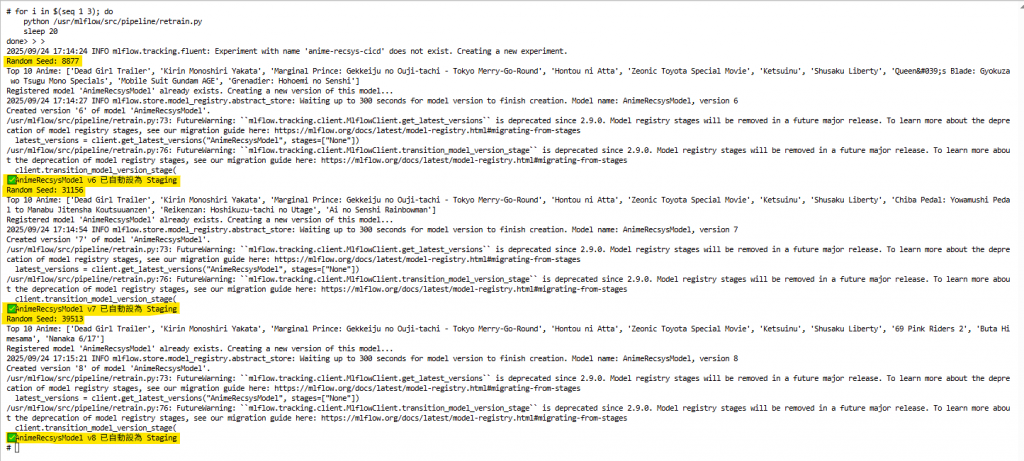
打開 MLflow UI → Models → AnimeRecsysModel:
random_seed。top10.json,就能看到每次推薦清單的差異。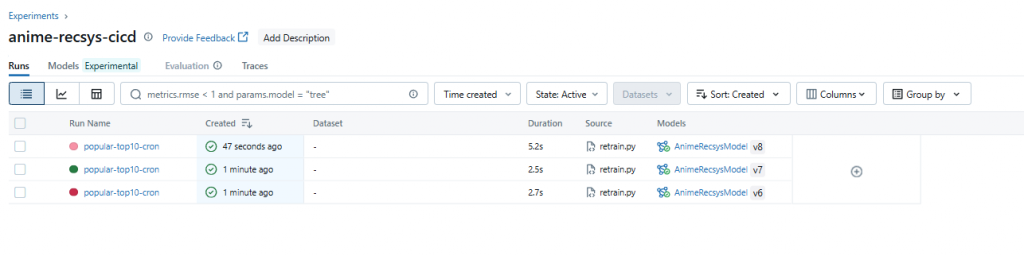
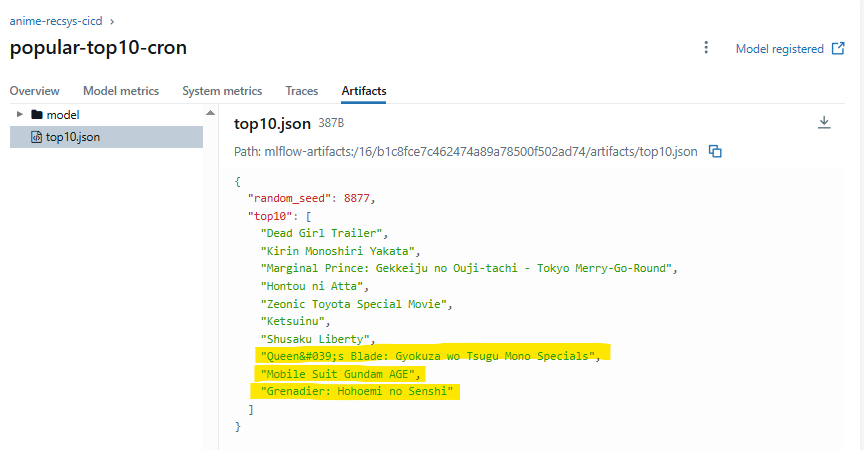
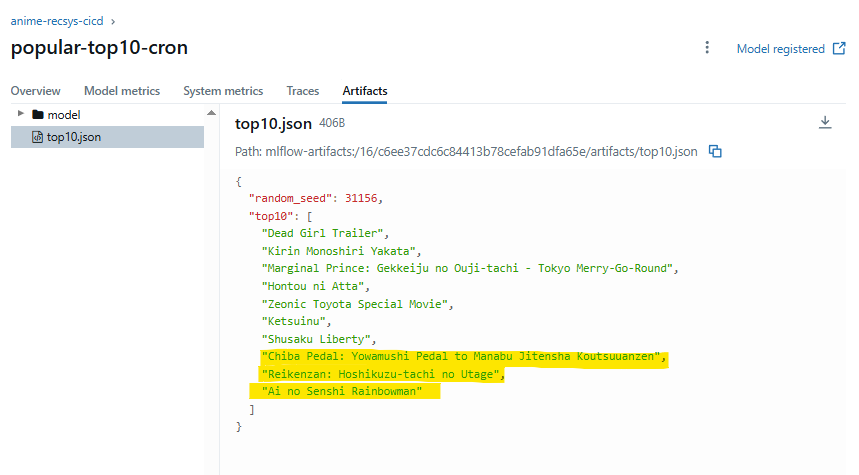
如果要測試推薦 API,可以用 Staging:
mlflow models serve -m "models:/AnimeRecsysModel/Staging" -p 5001 --no-conda
再用 curl 測試:
curl -X POST http://127.0.0.1:5001/invocations \
-H "Content-Type: application/json" \
-d '{"inputs": [["Naruto"]]}'
API 輸出會根據當前 Staging 版本的 top10.json 而變化。
for loop (每20秒)
│
▼
retrain.py
│
├── Top7 (熱門) + Random3 (隨機)
├── MLflow Tracking (params: random_seed)
├── Artifact: top10.json
└── 註冊 → AnimeRecsysModel (Staging)
│
▼
mlflow models serve (Staging)
│
▼
REST API /invocations
Day 19 我們讓 PopularTop10 baseline 變得「隨時間有變化」:
random_seed + top10.json)。用 for loop + sleep → 每 20 秒 retrain 一次,短短 1 分鐘就能在 UI 上看到 v1, v2, v3。
新版本會自動標記為 Staging,方便 serve 測試。
本篇用最簡單的方式(for loop + sleep)模擬自動化 retrain,適合 Demo。
但在企業環境,我們會把這套流程延伸到:
👉 那樣就能實現:
未來有時間,我們可以再深入實作 CI/CD 管線。
但在這 30 天系列裡,我們保持「最簡單可運行」為原則,讓我們快速體驗從 0 開始搭建 MLflow + FastAPI 推薦系統應用。

