今天,我們將讓推薦系統的 A/B 測試更貼近實際產品:
除了雙模型比較與隨機分流外,
還要讓 CTR 不再永遠是 100%,能真實反映使用者行為。
透過本日內容,你將學會:
random.choice() 讓分流機制成為真正隨機clicked=False)在 FastAPI 的 /recommend_ab 分流函式中,
我們改用 random.choice() 讓每次推薦隨機分派模型:
import random
def choose_model_by_time():
"""改為真正隨機分流,模擬真實 A/B Test"""
return random.choice(["AnimeRecsysModel", "AnimeRecsysTFIDF"])
✅ 這樣每位使用者、每次推薦都可能落在不同模型,
讓 A/B 測試分佈更自然、更具統計代表性。
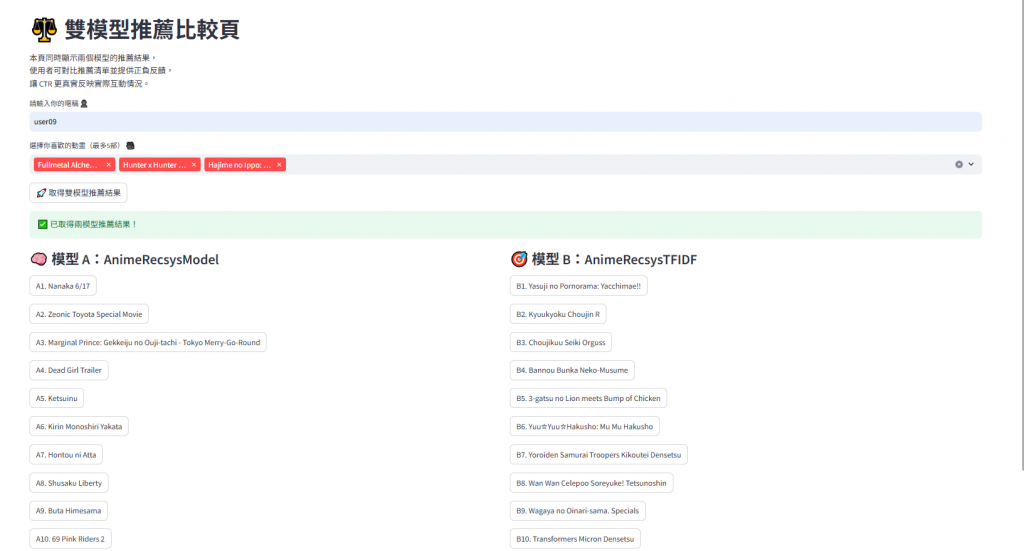
/src/api/pages/ab_multiple.py這個頁面同時顯示兩個模型的推薦清單,
並新增「😐 我都不喜歡」按鈕,用來記錄使用者不感興趣的情況。
# ⚖️ 雙模型推薦比較頁(/src/api/pages/ab_multiple.py)
import os
import pandas as pd
import requests
import streamlit as st
from datetime import datetime
FASTAPI_URL = os.getenv("FASTAPI_URL", "http://localhost:8000")
ANIME_CSV_PATH = "/src/api/notebooks/data/anime_clean.csv"
st.set_page_config(page_title="⚖️ 雙模型推薦比較", layout="wide")
st.title("⚖️ 雙模型推薦比較頁")
st.markdown("""
本頁同時顯示兩個模型的推薦結果,
使用者可對比推薦清單並提供正負反饋,
讓 CTR 更真實反映實際互動情況。
""")
nickname = st.text_input("請輸入你的暱稱 👤", placeholder="例如:Josh、Mina、Ken")
if not nickname:
st.info("請輸入暱稱後再繼續。")
@st.cache_data
def load_anime_list():
if not os.path.exists(ANIME_CSV_PATH):
st.error(f"❌ 找不到資料檔案:{ANIME_CSV_PATH}")
return []
df = pd.read_csv(ANIME_CSV_PATH)
return df["name"].dropna().unique().tolist()
anime_list = load_anime_list()
selected_anime = st.multiselect("選擇你喜歡的動畫(最多5部) 🎥", anime_list, max_selections=5)
def get_recommendations(model_name, user_id, anime_titles):
payload = {"user_id": user_id, "anime_titles": anime_titles}
params = {"model_name": model_name}
res = requests.post(f"{FASTAPI_URL}/recommend", json=payload, params=params)
if res.status_code == 200:
return res.json()
else:
st.error(f"❌ {model_name} 取得推薦失敗:{res.text}")
return None
def log_click_event(user_id, model_name, model_version, title, page, clicked=True):
event = {
"user_id": user_id,
"model_name": model_name,
"model_version": model_version,
"recommended_title": title if title else None,
"clicked": clicked,
"timestamp": datetime.utcnow().isoformat(),
"page": page
}
try:
r = requests.post(f"{FASTAPI_URL}/log-ab-event", json=event)
if r.status_code != 200:
st.warning(f"⚠️ 記錄失敗:{r.text}")
except requests.exceptions.RequestException:
st.warning("⚠️ 無法連線至 FastAPI")
if st.button("🚀 取得雙模型推薦結果"):
if not nickname:
st.warning("請先輸入暱稱。")
elif not selected_anime:
st.warning("請至少選擇一部動畫。")
else:
model_a, model_b = "AnimeRecsysModel", "AnimeRecsysTFIDF"
res_a = get_recommendations(model_a, nickname, selected_anime)
res_b = get_recommendations(model_b, nickname, selected_anime)
if res_a and res_b:
st.session_state["rec_a"], st.session_state["rec_b"] = res_a["recommendations"], res_b["recommendations"]
st.session_state["model_a"], st.session_state["model_b"] = model_a, model_b
st.success("✅ 已取得兩模型推薦結果!")
if "rec_a" in st.session_state and "rec_b" in st.session_state:
col1, col2 = st.columns(2)
with col1:
st.subheader(f"🧠 模型 A:{st.session_state['model_a']}")
for i, title in enumerate(st.session_state["rec_a"][:10], 1):
if st.button(f"A{i}. {title}", key=f"a_{i}"):
log_click_event(nickname, st.session_state["model_a"], 1, title, page="ab_multiple", clicked=True)
if st.button("😐 我都不喜歡模型 A 的推薦", key="dislike_a"):
log_click_event(nickname, st.session_state["model_a"], 1, None, page="ab_multiple", clicked=False)
st.info("已記錄:使用者對模型 A 的推薦不感興趣。")
with col2:
st.subheader(f"🎯 模型 B:{st.session_state['model_b']}")
for i, title in enumerate(st.session_state["rec_b"][:10], 1):
if st.button(f"B{i}. {title}", key=f"b_{i}"):
log_click_event(nickname, st.session_state["model_b"], 1, title, page="ab_multiple", clicked=True)
if st.button("😐 我都不喜歡模型 B 的推薦", key="dislike_b"):
log_click_event(nickname, st.session_state["model_b"], 1, None, page="ab_multiple", clicked=False)
st.info("已記錄:使用者對模型 B 的推薦不感興趣。")
/src/api/pages/ab_random.py新增「我都不喜歡」按鈕,並讓後端每次隨機選擇模型。
# 🎲 隨機分流推薦頁(/src/api/pages/ab_random.py)
import os
import pandas as pd
import requests
import streamlit as st
from datetime import datetime
FASTAPI_URL = os.getenv("FASTAPI_URL", "http://localhost:8000")
ANIME_CSV_PATH = "/src/api/notebooks/data/anime_clean.csv"
st.set_page_config(page_title="🎲 隨機分流推薦", layout="wide")
st.title("🎲 A/B Test 隨機分流頁")
st.markdown("""
本頁使用 FastAPI `/recommend_ab` 隨機分流至不同模型,
並新增「我都不喜歡」按鈕記錄負樣本,使 CTR 統計更真實。
""")
nickname = st.text_input("請輸入你的暱稱 👤", placeholder="例如:Josh、Mina、Ken")
if not nickname:
st.info("請輸入暱稱後再繼續。")
@st.cache_data
def load_anime_list():
if not os.path.exists(ANIME_CSV_PATH):
st.error(f"❌ 找不到資料檔案:{ANIME_CSV_PATH}")
return []
df = pd.read_csv(ANIME_CSV_PATH)
return df["name"].dropna().unique().tolist()
anime_list = load_anime_list()
selected_anime = st.multiselect("選擇你喜歡的動畫(最多5部) 🎥", anime_list, max_selections=5)
def get_random_recommend(user_id, anime_titles):
payload = {"user_id": user_id, "anime_titles": anime_titles}
res = requests.post(f"{FASTAPI_URL}/recommend_ab", json=payload)
if res.status_code == 200:
return res.json()
else:
st.error(f"❌ recommend_ab 取得推薦失敗:{res.text}")
return None
def log_click_event(user_id, model_name, model_version, title, page, clicked=True):
event = {
"user_id": user_id,
"model_name": model_name,
"model_version": model_version,
"recommended_title": title if title else None,
"clicked": clicked,
"timestamp": datetime.utcnow().isoformat(),
"page": page
}
try:
requests.post(f"{FASTAPI_URL}/log-ab-event", json=event)
except requests.exceptions.RequestException:
st.warning("⚠️ 無法記錄事件")
if st.button("🚀 取得隨機推薦結果"):
if not nickname:
st.warning("請先輸入暱稱。")
elif not selected_anime:
st.warning("請至少選擇一部動畫。")
else:
res = get_random_recommend(nickname, selected_anime)
if res:
st.session_state["random_recs"] = res["recommendations"]
st.session_state["model_name"] = res["model_name"]
st.success(f"✅ 本次使用模型:{st.session_state['model_name']}")
if "random_recs" in st.session_state:
model_name = st.session_state["model_name"]
recs = st.session_state["random_recs"]
st.markdown("---")
st.subheader(f"✨ 模型:{model_name}")
for i, title in enumerate(recs[:10], 1):
if st.button(f"{i}. {title}", key=f"r_{i}"):
log_click_event(nickname, model_name, 1, title, page="ab_random", clicked=True)
if st.button("😐 我都不喜歡以上推薦"):
log_click_event(nickname, model_name, 1, None, page="ab_random", clicked=False)
st.info("已記錄:使用者對本輪推薦沒有興趣。")

使用 st.rerun() 清除快取並重新讀取最新紀錄,
讓報表更新更即時。
st.sidebar.markdown("### 🔄 重新整理報表")
if st.sidebar.button("重新載入資料"):
st.cache_data.clear()
st.rerun()
@st.cache_data(ttl=5.0)
def load_logs():
if not os.path.exists(LOG_PATH):
st.warning("⚠️ 找不到 ab_events.csv")
return pd.DataFrame()
df = pd.read_csv(LOG_PATH, on_bad_lines="skip")
df["timestamp"] = pd.to_datetime(df["timestamp"], errors="coerce")
return df
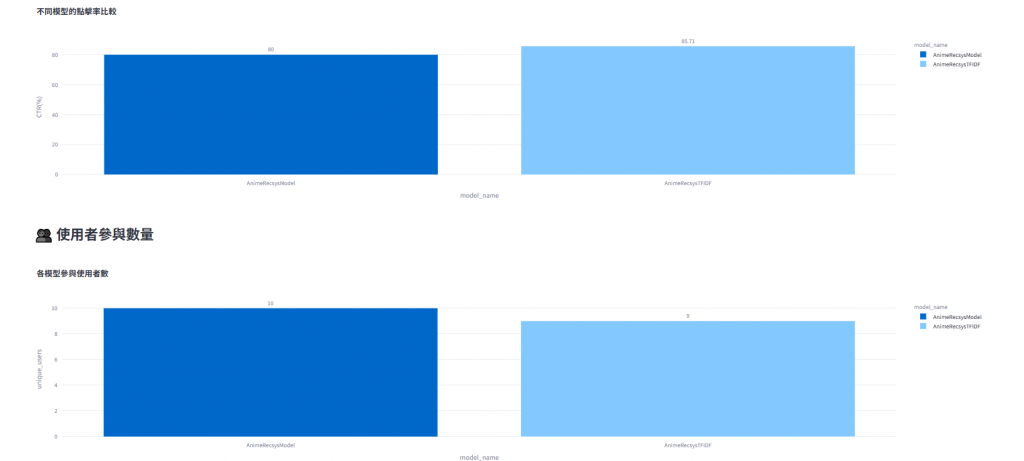
✅ 使用者也可以隨時點擊「重新載入」按鈕,
即時看到最新互動資料與 CTR 變化。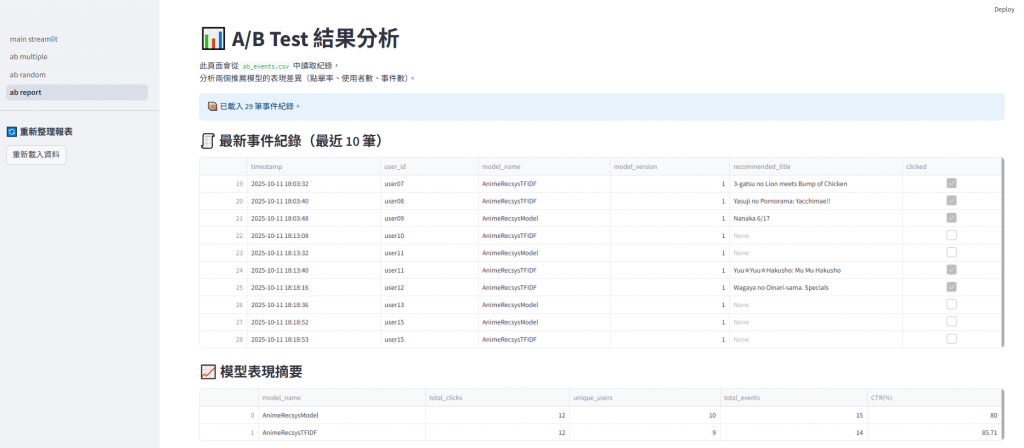
| 方法 | 說明 |
|---|---|
| 👍 / 👎 按鈕 | 在推薦結果旁加上「喜歡 / 不喜歡」按鈕,記錄二元樣本。 |
| ⭐ 評分機制 | 讓使用者給 1–5 分,分析模型平均滿意度。 |
| 🕒 停留時間 | 若整合前端事件(瀏覽時間或滑動距離),可作為隱性正樣本。 |
| 💬 文字回饋 | 收集使用者留言理由,可進行語意分析強化模型。 |
| 功能 | 成果 |
|---|---|
| 🔁 真隨機分流 | 使用 random.choice(),每次推薦獨立隨機分派 |
| ⚖️ 雙模型比較 | 同頁對比推薦結果並記錄正負樣本 |
| 🎲 分流推薦頁 | 加入「我都不喜歡」記錄 clicked=False |
| 📊 報表頁 | 可即時重新整理顯示最新 CTR |
🎉 Day 29 完成!
你現在的推薦系統不僅能做 A/B 測試,
還能同時蒐集正、負樣本數據,
CTR 分析將真實反映使用者對不同模型的接受度。
明天(Day 30),我們將總結整個 MLflow + FastAPI + Streamlit 流程,
完整回顧如何從開發到部署打造企業級模型應用。

