昨天我們把 WordPress 跟 MariaDB 成功部署起來,透過 Volumes 保存資料,並讓前端和後端能透過 Service 正常連線。雖然功能上都沒問題,但回頭想想,這些 Pod 到底是「用誰的身份」在跑?又能不能存取 API 或主機上的特定資源?其實我們一路下來都是用 預設的權限與安全設定,這在測試環境沒什麼,但在真實環境裡就會變成一個隱憂。
所以今天要換個角度,來看 Kubernetes 裡的兩個安全基礎:Security Context 和 ServiceAccount。前者決定 Pod / Container 能不能以 root 身份執行、能用哪些 Linux capabilities;後者則是應用在叢集裡的「身份證」,影響它能不能去呼叫 Kubernetes API、能存取什麼資源。
在 Docker 裡,我們可以指定 Container 的使用者 ID、是否允許 root、要增加或刪除哪些 Linux Capabilities。Kubernetes 也提供類似的機制,就被叫做 Security Context。
Security Context 用來定義 Pod 或 Container 的特權與存取控制設定,像是以哪個使用者身分運行、是否允許提權、能否修改核心參數、是否使用特權模式等等。它可以設定在 Pod 層級(影響該 Pod 中所有的容器)或 Container 層級(只影響指定容器,並會覆蓋 Pod 層級的相同設定)。
常見的設定欄位包括:
runAsUser / runAsGroup:指定容器的進程要以哪個使用者 ID (UID) / 群組 ID (GID) 執行。runAsNonRoot:布林值。設為 true 會強制容器必須以非 root 帳號執行,否則 Pod 會無法啟動。privileged:布林值。設為 true 即為「特權模式」,容器將能存取主機上所有的裝置(如 /dev),並繞過許多核心層級的限制。權限極大,應謹慎使用。allowPrivilegeEscalation:布林值。控制容器內的進程是否可以獲得比其父進程更多的權限。例如,透過 setuid 或 setgid 位元的執行檔來提權。為了安全,通常建議設為 false。fsGroup:設定一個特殊的群組 ID,讓 Pod 中所有容器掛載的 Volume 都會屬於這個群組。這對於共享儲存的權限管理非常有用。readOnlyRootFilesystem:布林值。設為 true 會將容器的根目錄檔案系統以「唯讀」方式掛載。這是個極佳的安全實踐,可防止惡意程式修改容器內的系統檔案。應用程式需要寫入的路徑則需額外掛載 Volume。capabilities:細緻化 root 權限,只給容器需要的部分能力。例如只給予網路管理 (NET_ADMIN) 能力,但移除其他危險權限。seccompProfile:限制容器內可以使用的系統呼叫 (System Calls),降低核心被攻擊的風險。appArmorProfile:使用 AppArmor 來限制程式的權限,例如可以讀取、寫入或執行哪些檔案。換句話說,Security Context 是容器級別的「權限管理員」,決定它能夠對作業系統做到什麼程度。
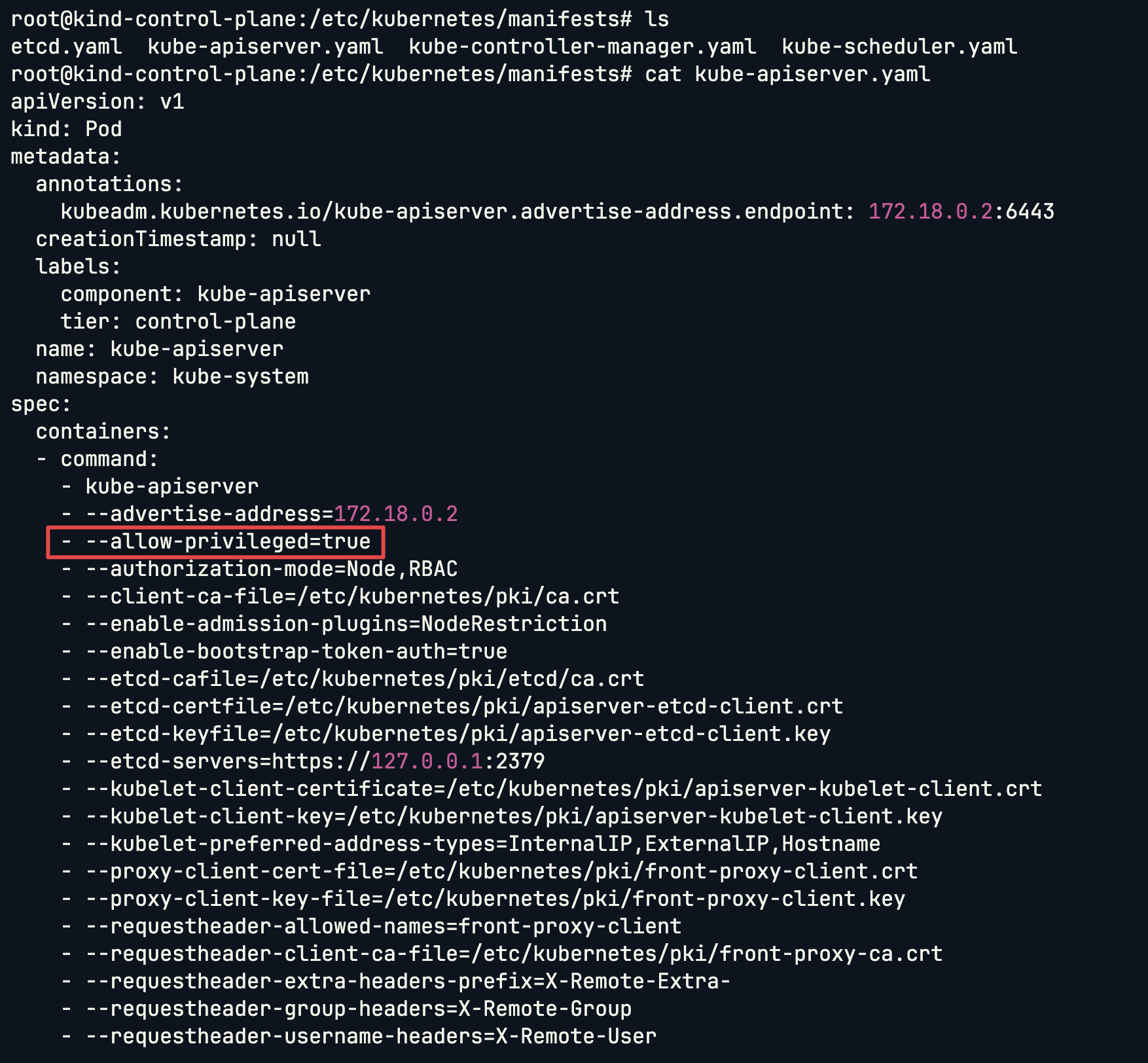
如要開啟容器使用 privileged 權限,需要於
kube-apiserver啟動時加入參數--allow-privileged=true。由於現行的 Kubernetes 版本預設已啟用此功能,故後續只要在 Pod 或 Container 中加入 Security Context 設定即可。
另一個安全關鍵是 ServiceAccount。在 Kubernetes 裡,有兩種帳號:User Account(人類用)和 ServiceAccount(應用程式用)。
這個概念跟雲端服務的 IAM 角色很像。譬如說,我的應用程式需要存取 GCP 的 Vertex AI 服務,我就需要建立一個 Service Account,並賦予這個 Service Account Vertex AI User 的角色,應用程式就能以這個身份去呼叫 Vertex AI 的 API。
在 Kubernetes 的概念也一樣。舉例來說,監控系統 Prometheus 需要讀取 Kubernetes API 來取得叢集的 Metrics,CI/CD 工具 Jenkins 需要權限把應用程式部署到叢集裡,這些場景就需要透過 ServiceAccount 來進行身份驗證與授權。
過去,建立 ServiceAccount 時會自動產生一個「不會過期的 Secret Token」,但這在安全性和可擴展性上都有隱憂。從 Kubernetes 1.22 開始,引入了 TokenRequest API,用來產生具有效期與使用者(audience)綁定的短期 Token,更加安全。到了 1.24,ServiceAccount 預設已不再自動建立 Secret,需要我們手動透過 kubectl create token <service-account-name> 來生成。
我們先看到 Pod Security Context 這邊,那前面介紹一直提到 privileged (特權模式),因此這邊我們來看看有無特權模式差在哪:
建立一個沒有任何 Security Context 設定的標準 Pod。雖然它預設以 root 使用者執行,但並非特權模式。
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: non-priviledged
name: non-priviledged
spec:
containers:
- args:
- /bin/sh
- -c
- sleep 3600;
image: rockylinux:9
name: non-priviledged
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
把 Pod 建立起來以後,我們進入 Container 查看 /dev 目錄下的裝置檔案:

建立一個特權模式的 Pod,只需在 container 層級加上 securityContext
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: priviledged
name: priviledged
spec:
containers:
- args:
- /bin/sh
- -c
- sleep 3600;
image: rockylinux:9
name: priviledged
# 加上 Security Context
securityContext:
privileged: true
procMount: Default
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
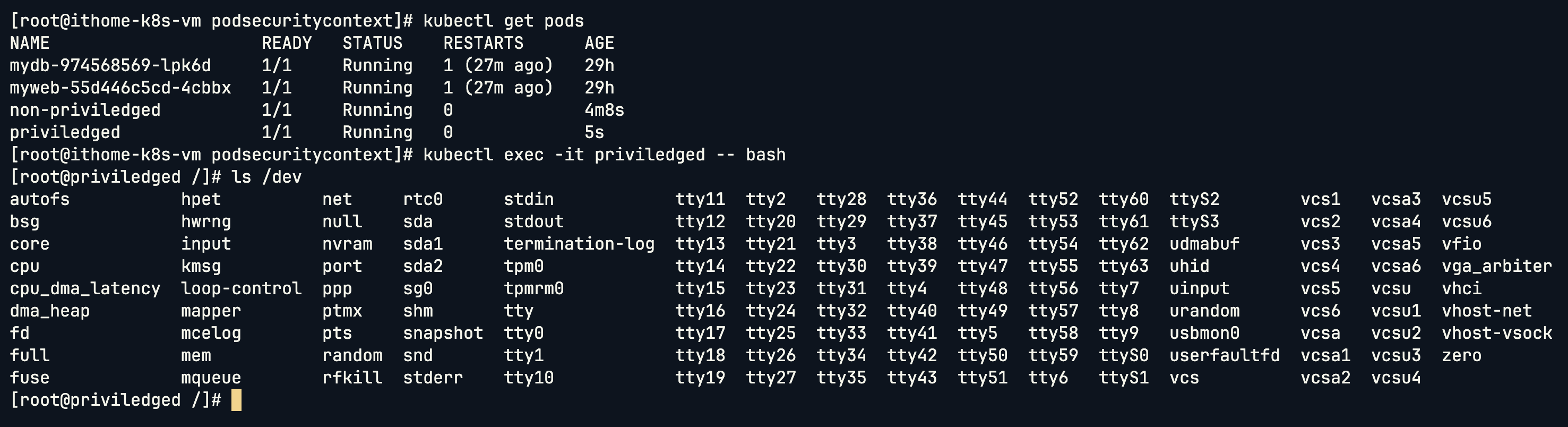
可以看到特權模式的 Pod 能夠看到主機上幾乎所有的系統裝置檔案(如 sda, nvme0 等),而非特權模式的 Pod 只能看到最基本的虛擬裝置。這意味著特權容器幾乎取得了與主機 root 同等的硬體存取能力,風險極高。
runAsUser 與 fsGroup建立一個未指定任何使用者資訊的 Pod。它會掛載一個 emptyDir 的 Volume 到 /data/demo。
apiVersion: v1
kind: Pod
metadata:
name: security-non-context-demo
spec:
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: false
建立另一個 Pod,在 Pod 層級 設定 securityContext,指定所有容器內的進程都必須以 UID 1000 的身份執行,並且掛載的 Volume 檔案系統群組為 GID 2000。透過 Security Context 控制容器的使用者與檔案系統權限。
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
fsGroup: 2000
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: false
從下面的結果可以看到:
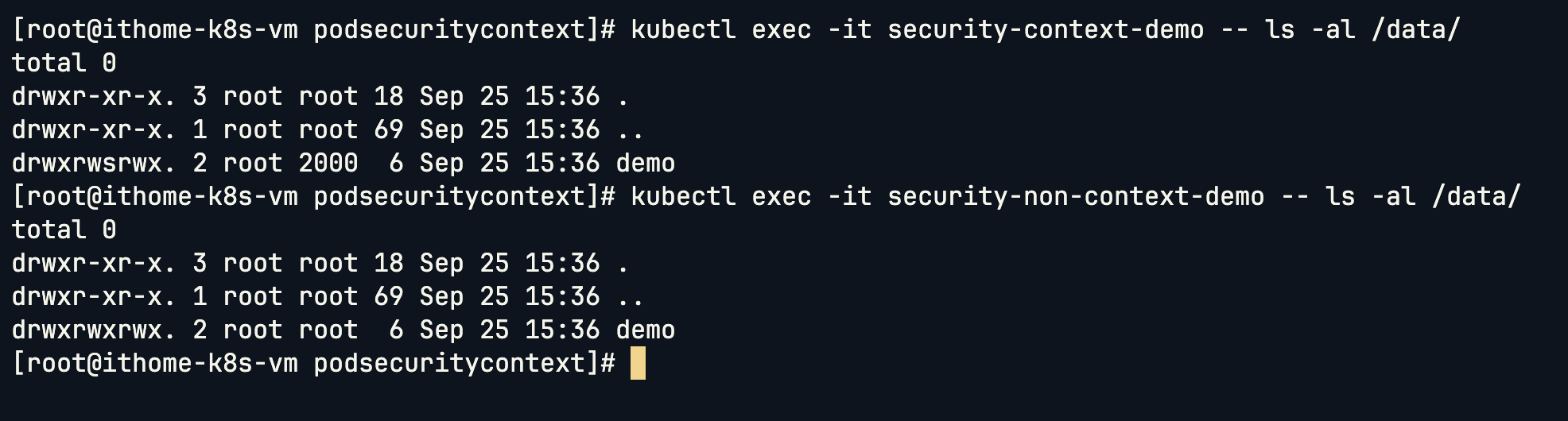
runAsUser: 1000,容器內的進程被強制以 UID 1000 的身份啟動。另一個 fsGroup: 2000 的設定,它讓 Kubernetes 自動將掛載進來的 sec-ctx-vol Volume 的擁有群組設為 2000,並賦予寫入權限。這確保了即使我們的進程 (UID 1000) 不是 root,也能成功地在 /data/demo 目錄下寫入檔案。我們遵循「最小權限原則」,在不使用 root 的情況下,精準地控制檔案系統權限。runAsUser,預設以 root (UID=0) 身份執行,因此建立的檔案擁有者是 root:root。
在某些應用場景(例如 Elasticsearch),需要調整核心參數才能正常運作。Security Context 也允許我們修改被標記為 safe 的核心參數。
建立一個未調整核心參數的 Pod,其核心參數 vm.max_map_count 為預設值:
kubectl run non-sysctl --image=rockylinux:9 --restart=Never --dry-run=client -o yaml -- /bin/sh -c "sleep 3600;" > security_context_non_sysctl.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: non-sysctl
name: non-sysctl
spec:
containers:
- args:
- /bin/sh
- -c
- sleep 3600;
image: rockylinux:9
name: non-sysctl
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
建立另一個 Pod,並透過 initContainers 來修改核心參數。修改核心參數本身需要特權,所以 initContainers 必須設定 privileged: true。
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: sysctl
name: sysctl
spec:
initContainers:
- name: init-sysctl
image: busybox:latest
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- args:
- /bin/sh
- -c
- sleep 36000;
image: rockylinux:9
name: sysctl
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
這邊礙於 kind 的 Container 沒有 sysctl 指令,因此我無法 demo 結果,但是我看大神 demo 的結果會長這樣,做法是分別進入兩個 Container 檢查核心參數,可以看到 sysctl Pod 中的 vm.max_map_count 已被成功修改:
[root@master ~]# kubectl exec -it non-sysctl -- /bin/bash -c "sysctl -a | grep map"
vm.max_map_count = 65530
vm.min_unmapped_ratio = 1
vm.mmap_min_addr = 4096
vm.mmap_rnd_bits = 28
vm.mmap_rnd_compat_bits = 8
[root@master ~]# kubectl exec -it sysctl -- /bin/bash -c "sysctl -a | grep map"
fs.nfs.idmap_cache_timeout = 0
vm.max_map_count = 262144
vm.min_unmapped_ratio = 1
vm.mmap_min_addr = 4096
vm.mmap_rnd_bits = 28
vm.mmap_rnd_compat_bits = 8
如果不想要給予完整的 privileged 權限,但又需要部分 root 能力時,capabilities 就是最好的選擇。它允許你「精準地」賦予容器所需的最小權限。
例如,有個應用程式需要修改系統時間 (SYS_TIME) 和設定網路介面 (NET_ADMIN),但不需要其他 root 權限。我們可以這樣設定:
apiVersion: v1
kind: Pod
metadata:
name: ubuntu-sleeper
namespace: default
spec:
containers:
- command:
- sleep
- "4800"
image: ubuntu
name: ubuntu-sleeper
securityContext:
capabilities:
add: ["SYS_TIME", "NET_ADMIN"]
接下來的實戰,我們要讓一個 Dashboard Pod 能成功呼叫 Kubernetes API。使用的映像檔 gcr.io/kodekloud/customimage/my-kubernetes-dashboard 已經封裝好了與 API 互動的底層邏輯。
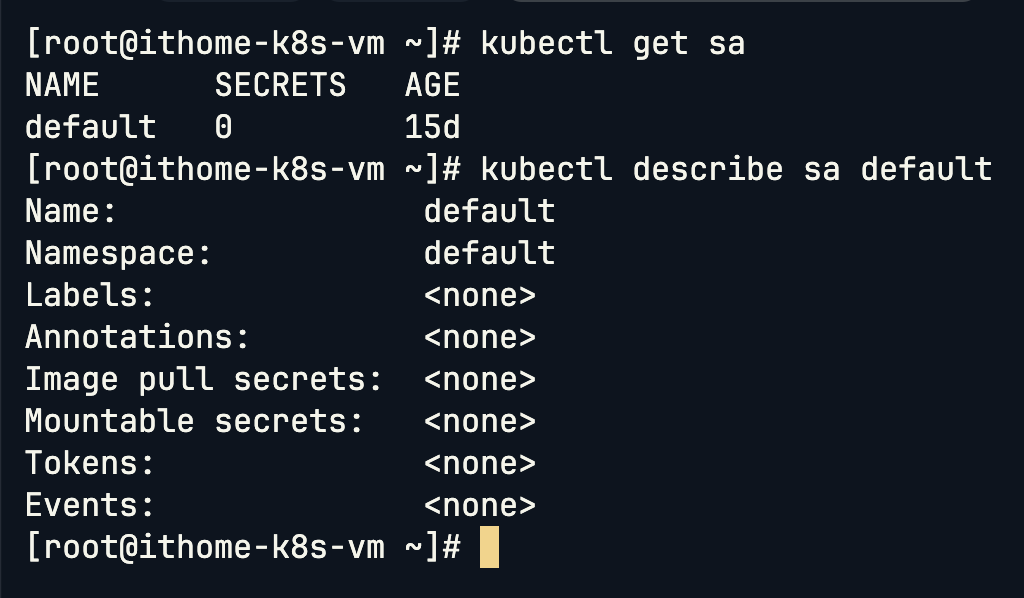
首先,查看預設的 default Service Account,可以看到 Token 欄位是空的,這呼應我們前面提到了新版 Kubernetes 不再自動為 ServiceAccount 建立 Secret Token 的機制。
kubectl describe sa default
建立 Dashboard 的 Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
name: web-dashboard
namespace: default
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
name: web-dashboard
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
name: web-dashboard
spec:
containers:
- env:
- name: PYTHONUNBUFFERED
value: "1"
image: gcr.io/kodekloud/customimage/my-kubernetes-dashboard
imagePullPolicy: Always
name: web-dashboard
ports:
- containerPort: 8080
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
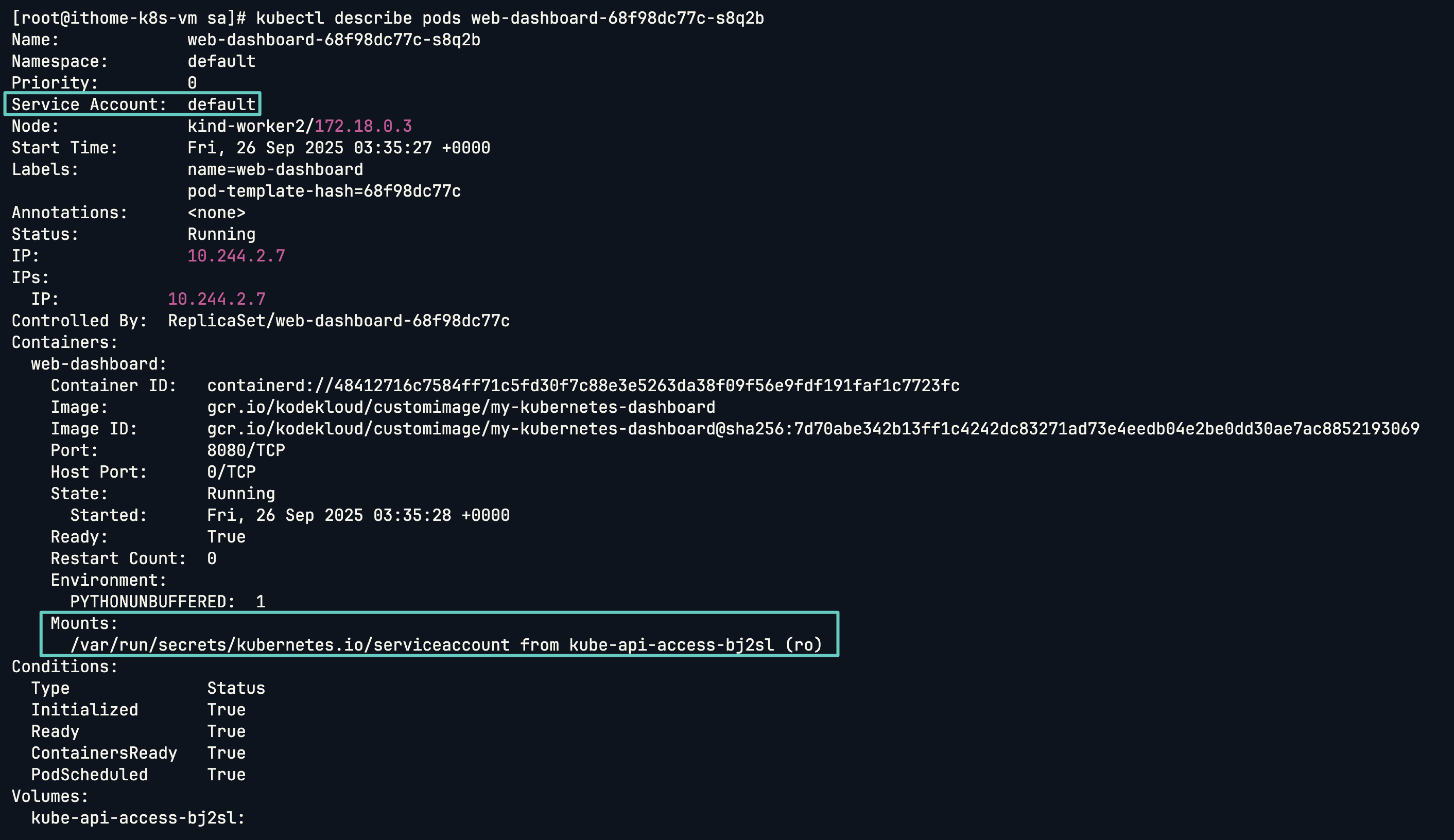
建立後,可以看到 Pod 使用了預設的 default Service Account,如果有 Token 也會被掛載到 Pod 內的 /var/run/secret 資料夾。
kubectl describe pods web-dashboard-68f98dc77c-s8q2b
建立 Dashboard 的 Service:
apiVersion: v1
kind: Service
metadata:
name: dashboard-service
namespace: default
spec:
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- nodePort: 30080
port: 8080
protocol: TCP
targetPort: 8080
selector:
name: web-dashboard
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
建立完成之後,我們存取 Dashboard 頁面時,看到了 Forbidden 錯誤,因為 default Service Account 預設沒有任何存取 API 的權限。
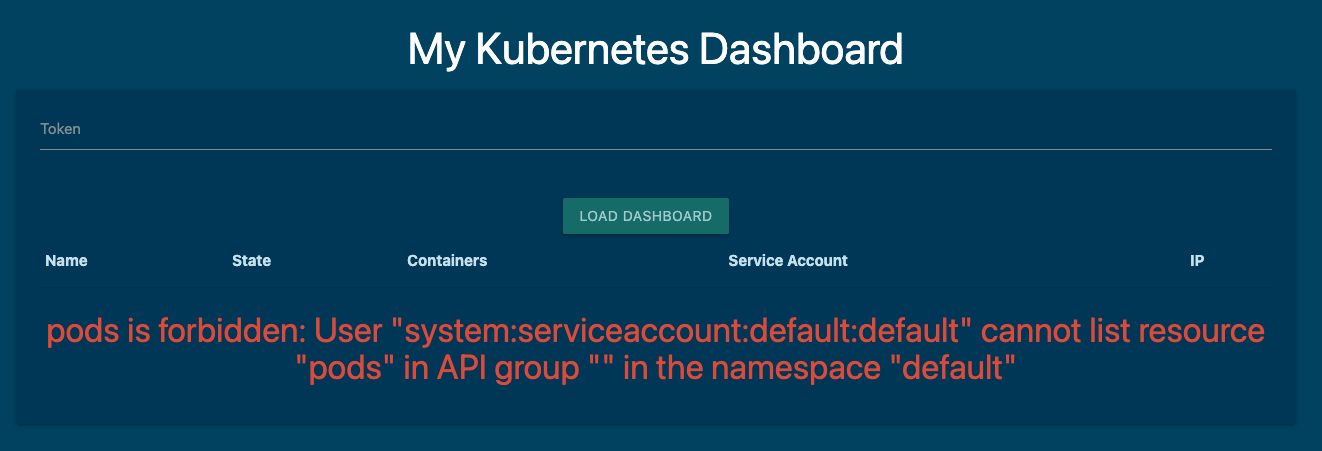
直接賦予 default Service Account 權限是不安全的做法,因為 default 的 Service Account 是所有應用程式預設使用。因此我們應該建立一個專屬的 Service Account dashboard-sa。
kubectl create sa dashboard-sa
建立好 Service Account 後,還需要賦予它權限。這部分屬於 RBAC 的範疇,明天再來深入探討,今天先直接使用。我們將建立一個能讀取 Pod 資訊的 Role,並透過 RoleBinding 將它與 dashboard-sa 綁定。
建立 pod-reader Role:
kubectl create -f pod-reader-role.yaml
# pod-reader-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups:
- ''
resources:
- pods
verbs:
- get
- watch
- list
建立 Role Binding:
kubectl create -f dashboard-sa-role-binding.yaml
# dashboard-sa-role-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: ServiceAccount
name: dashboard-sa
namespace: default
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io

權限綁定後,我們手動為 dashboard-sa 生成一個 Token:
kubectl create token dashboard-sa
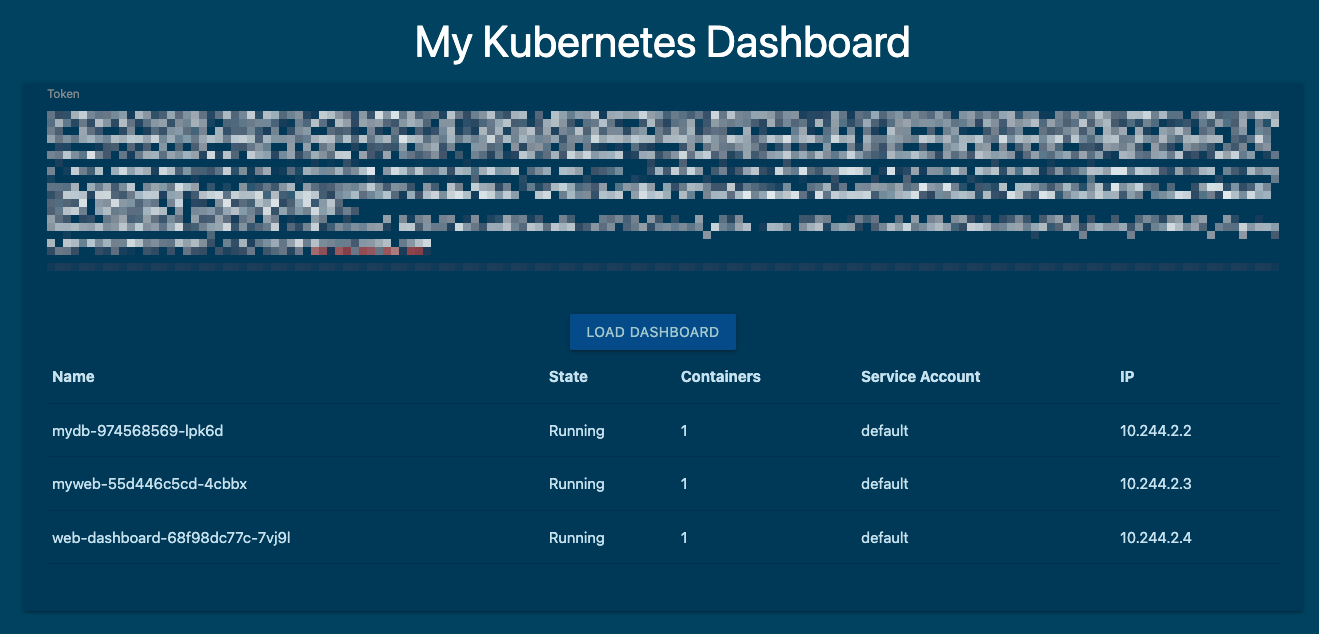
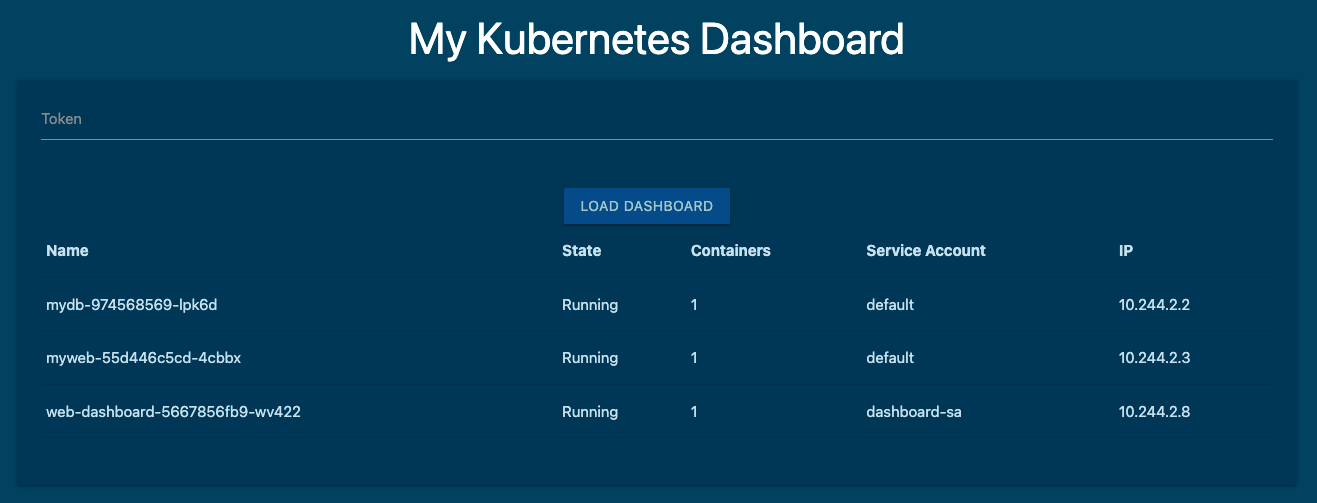
將 Token 複製下來貼到網頁中 Token 輸入框,就能成功看到 Pod 列表。以我的來看的話:一個是這個 Dashboard 的 Pod,另外兩個是 【Day17】Kubernetes 實戰演練:打造 WordPress + MariaDB 部署 建立的 Wordpress 和 MariaDB 的 Pod。
更理想的做法是直接修改 Deployment,指定它使用我們建立好的 Service Account。
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
generation: 1
name: web-dashboard
namespace: default
resourceVersion: "942"
uid: 823a7a95-f2d2-4c24-b638-bf9c075419ff
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
name: web-dashboard
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
name: web-dashboard
spec:
# 加入 Service Account
serviceAccountName: dashboard-sa
containers:
- env:
- name: PYTHONUNBUFFERED
value: "1"
image: gcr.io/kodekloud/customimage/my-kubernetes-dashboard
imagePullPolicy: Always
name: web-dashboard
ports:
- containerPort: 8080
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
更新 Deployment 後,回到 Dashboard 頁面,無需手動輸入 Token 即可成功顯示 Pod 資訊,並且可以看到 Pod 正確地使用了 dashboard-sa。
我們的實戰從對比 privileged 模式開始,直接驗證了特權容器的高度風險。接著,runAsUser 與 fsGroup 的實戰則展示了具體的最小權限實踐方式,達成了安全與功能的平衡。對於需要部分特權的場景,capabilities 也提供了更精細的控制。
然而,單純依賴開發者自律來設定 Security Context 顯然存在風險。為了解決這個問題,Kubernetes 提供了 Pod Security Admission (PSA)。這是一個在 Namespace 層級運作的內建安全控制器,管理者可以為不同環境設定預先定義好的安全等級(如 baseline 或 restricted),並自動校驗 Security Context。這種叢集級別的策略管理偏向 CKS 的範疇,因此就先不深入。
而在 ServiceAccount 的實戰中,我們也看到了權限控管的重要性。預設的 default Service Account 因為不具備任何權限,導致 Dashboard 應用程式被 API 拒絕。直到我們建立專屬的 dashboard-sa,並搭配 RBAC 賦予權限,才成功地讓應用程式獲得了它所需的最小 API 存取權限。
總結來說,Security Context 與 ServiceAccount 分別處理了不同層面的安全問題:
在設定 ServiceAccount 的過程中,我們已經初步接觸了 Role 和 RoleBinding,這正是 Kubernetes 的 RBAC 機制。明天,我們將深入探討 RBAC,看看如何精準地為不同的「身份」分配對應的叢集資源權限。