昨天,我們剛打開爬蟲的魔法書,學會了爬蟲的基本禮儀與原則。
今天,冒險正式進入實戰舞台—— 我們直接帶著鍬子去挖掘第一批金礦。
第一個礦場: 易遊網(ezTravel)
它提供了相對清晰的 sitemap(網站地圖),就像勇者進入迷宮前,幸運拿到一張路線圖。這樣我們能循序漸進、不至於一開始就迷失在龐大的資訊森林。
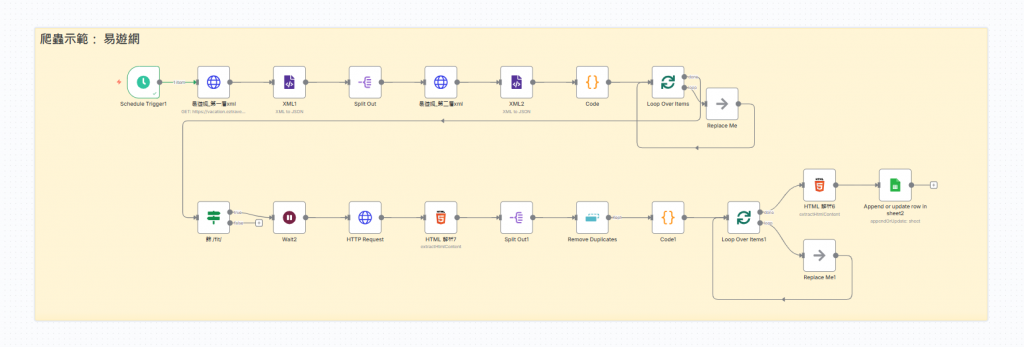
-不囉嗦~ 直接揭曉實作挑戰的挖礦路線~ 看起來蠻複雜的
第一步:鎖定入口
昨天有提到,爬蟲的第一步是確認網路禮儀,
就像探險家進入神秘地窟之前,先要看守門人留下的「規則石碑」。
在 eztravel.com.tw/robots.txt 裡,我們找到 sitemap.xml 的導引路線,引領我們去探索的地方。
這是第一步,確認能安心往下走。
我們透過 HTTP Request請求,順利按下門鈴
不過,進一步往下走卻發現地圖不是單層的,而是像俄羅斯娃娃般,居然包了另一層 XML! 導航瞬間失靈~
-小技巧:
在正式展開抓取前,還有個小提醒~ 找到sitemap後,建議先逐層檢查一下資料架構
幸好 n8n 內建的 AI 小助手 出面引路,
它用 Split Out node,把 sitemap 裡的資料逐筆 拆出來。這下子,路徑清晰了。
-AI 小助手 讓今天的實作挑戰少繞了很多遠路。
進入n8n Doc頁面,找到「Chat with the docs」
第二步:小心駕馭魔法
這邊要注意:爬蟲不是無腦抓資料的蠻力行為,而是一種需要謹慎控制的魔法:
-小技巧:
Code node 是用來保留前 N 筆資料來源,減少伺服器負擔。
Remove Duplicates node 是用來避免重複抓取。
第三步:拆解結構
當路徑確認後,接下來要挑的就是寶物欄位。
在這次實驗中,我先聚焦在這幾個元素:
-商品名稱(去哪裡玩?)
-價格資訊(多少錢?)
-產品資訊(旅行社、起飛機場、日期...等等詳細內容)
這些欄位,就像冒險隊伍的基本裝備,先確保我們能收集到「最有價值」的資訊。
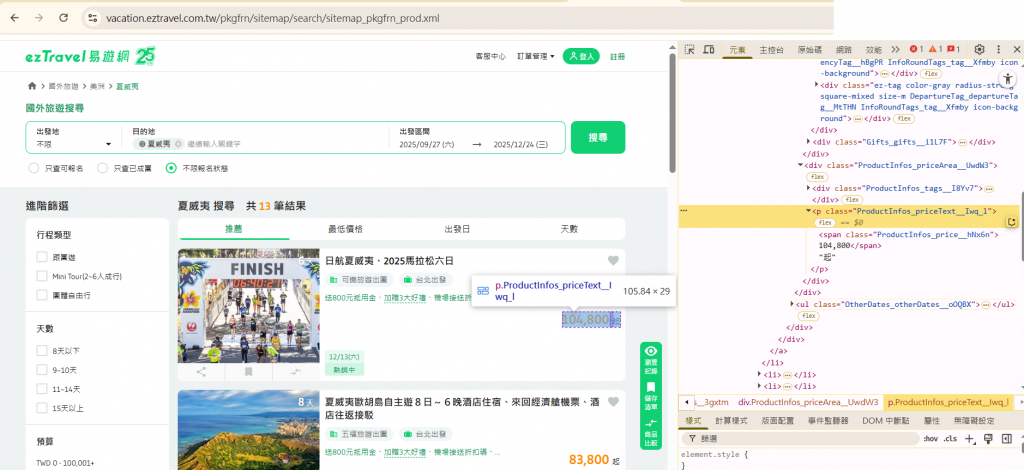
-透過瀏覽器的「檢查元素」功能找到正確的 CSS selector,
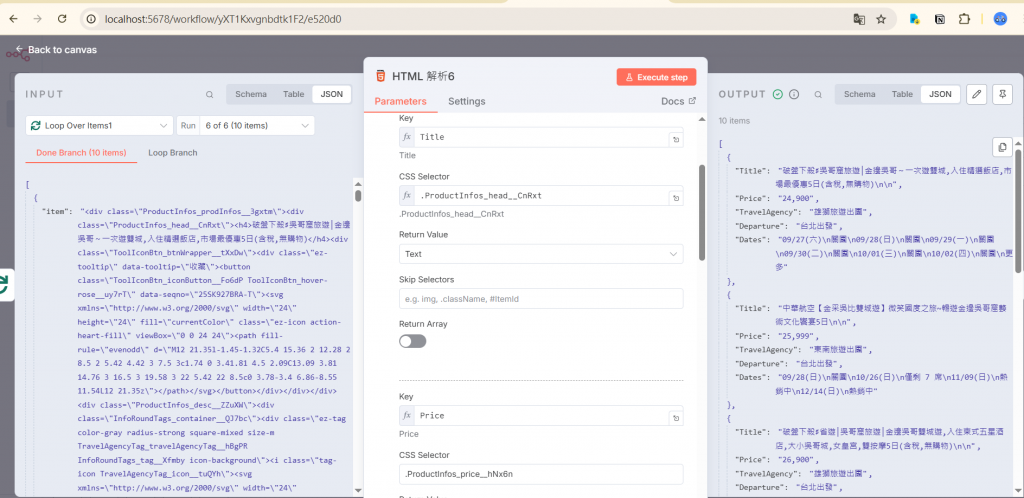
-再用 HTML Extract node 提取對應的 CSS selector。
這樣每一筆行程的標題、價格與細節,都能被精準挖掘。
第一批戰利品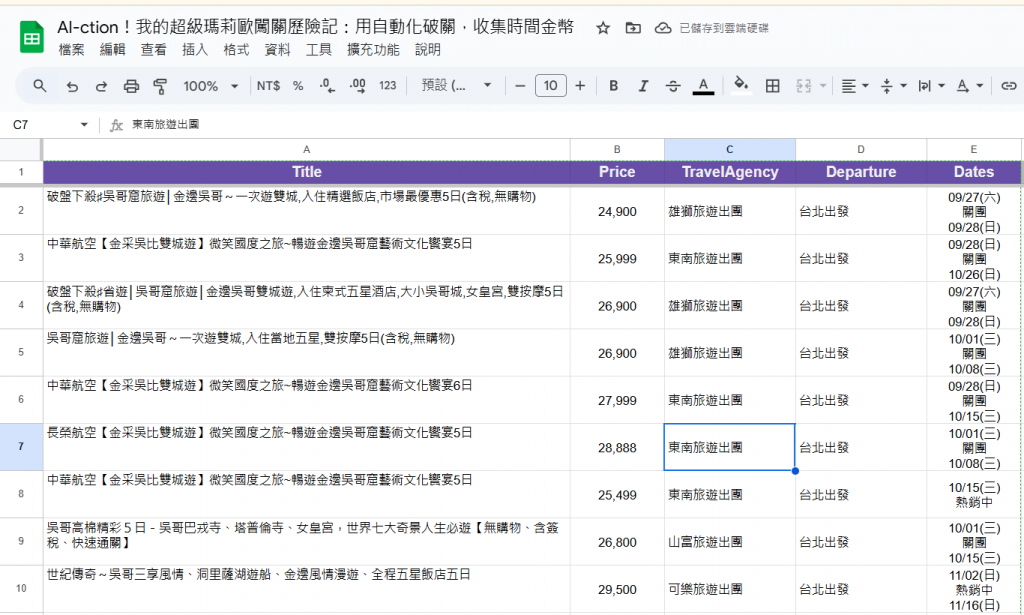
當我們把這些資訊成功抓下來,輸出成結構化表格的那一刻,就像在黑暗裡發現第一道光。
已經能看到未來的應用想像:
-翻譯 + 摘要 → 讓資料能跨語言流通
-情感分析 → 觀察用戶對旅遊商品的態度
-視覺化 → 把龐大的商品資料轉換成清晰的市場洞察
今天解鎖的新技能:
🍄 掌握資料入口與拆解:從 robots.txt 找到 sitemap,並用 n8n 的 Split Out node 拆解多層結構
🍄 資料抓取控管技巧:使用 Code node 保留前 N 筆、Remove Duplicates 去重
🍄 精準抓取與結構化輸出:CSS selector 定位目標欄位,對應 HTML Extract node 整理成結構化表格
📓 小結:
今天是爬蟲的第一場實戰。
我們不再是紙上談兵,從「概念」走到「落地」,也為未來更大規模的資料煉金術打下基礎。