我們已經突破了自動化的基本建設關卡,今天要穿過水管,來到另一端的 AI 加值魔法世界。
大家都知道 AI 的魔法令人讚嘆,而我們的目標是站在前人的肩膀上,把這些魔法技能點滿,讓原始資料煥發新生。這個魔法之地就是 —— Hugging Face。
今天,我們將面對 Hugging Face 的魔法。有了它,我們可以把最初收集的原始評論與資料,提煉成更有價值的寶物。
什麼是 Hugging Face ?
Hugging Face 可以想像成冒險者的魔法工坊。
來自世界各地的好心人士將訓練好的魔法秘方共享在這裡。
相較於 GitHub 讓開發者有個共通的平台分享「程式碼」;
Hugging Face 則是讓大家分享「開源模型」,想得到的大咖像是openai、google、meta...等,也都會將他們的開源模型發表在這上面,像前陣子剛更新的GPT 5.0模型在這也找得到。
不管你要: 關鍵字抽取、翻譯、摘要、情感分析,甚至 文字生成、圖片辨識,這裡都有現成的香料
最棒的是:很多魔法可以直接在瀏覽器、或透過 API 使用。
換句話說,Hugging Face 就是把「原礦」變「寶石」的工坊。
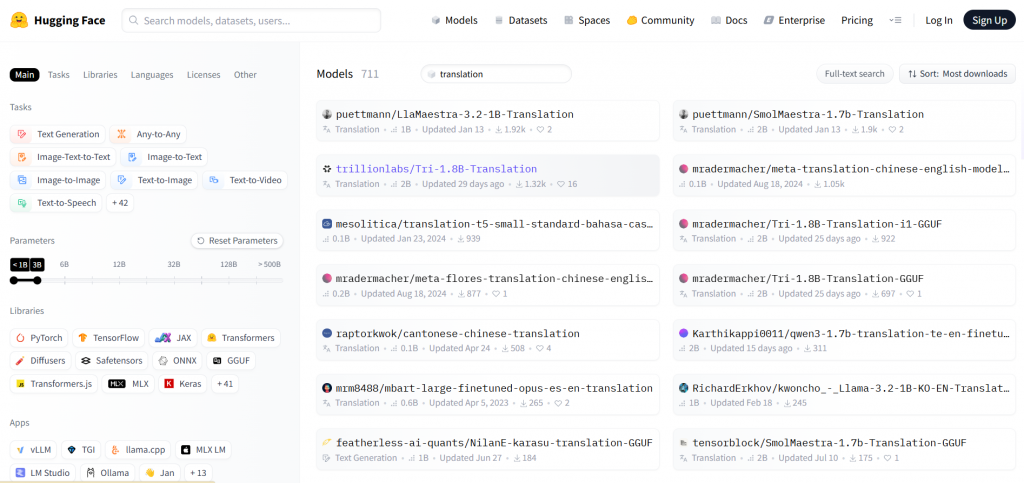
-我們可以從Models點選Tasks,依據想玩的任務類型像是:Image-to-Video、Text-to-Speech...隨意挑選;或者也可以輸入keyword直接搜尋。通常會以下載次數、更新日期..作為依據來做挑選。但要注意! 除非硬體等級有黃爸爸加持,不然還是仔細看一下Parameter參數,儘量挑小一點的電腦才不會跑得太吃力。
小實驗:新聞摘要練習
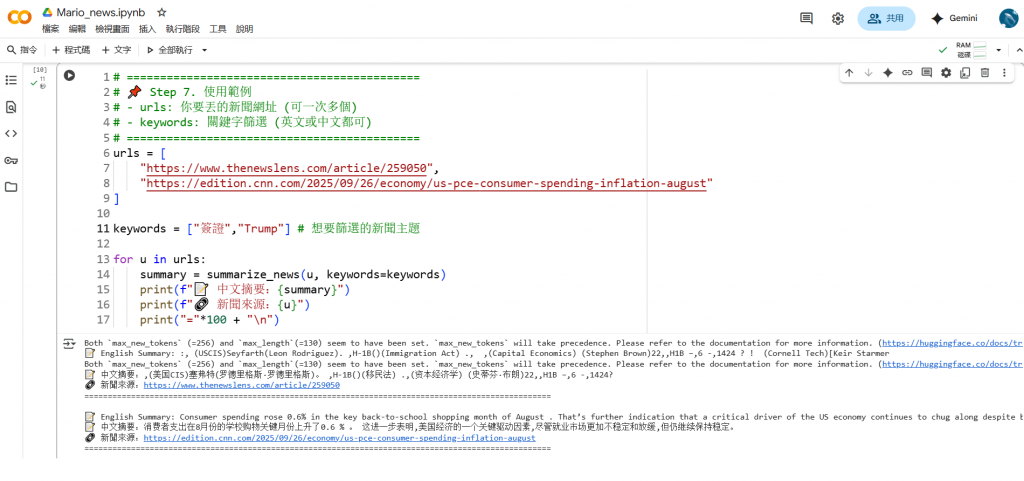
我們挑了CNN、The News Lens上的兩篇新聞作練習,目標是提供新聞報導連結便能幫我們產出中文新聞摘要。所以我打算這麼做:
第一步,引用「翻譯模型 translation」:由密密麻麻的外國語言,翻譯成熟悉的中文
第二步,引用「摘要模型 summarization」:把冗長的新聞或評論,濃縮成清晰摘要。
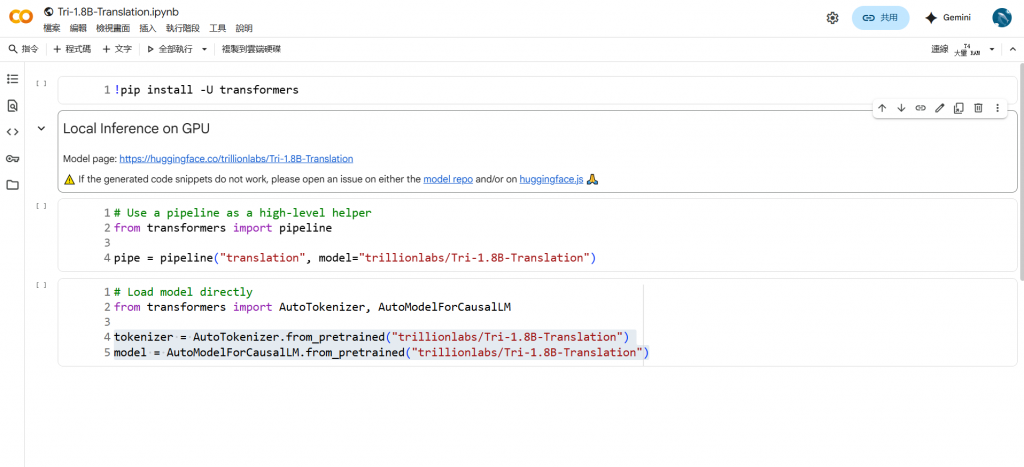
-點選選定的模型進入介紹頁之後,稍微瀏覽一下,要引用的話右上角有個「use this model」
-點進去,會有使用說明
最後,就會順利得到 「連結 + 中文摘要」 的輸出:
-小技巧:
善用Google家提供的Colab線上服務,減輕電腦負擔
今天解鎖的新技能
🍄 認識 Hugging Face:一個讓資料「開口說話」的魔法工坊,為後續加值鋪路
🍄 自動化流程:丟網址 → 翻譯 → 摘要 → 輸出,一條龍完成
📓 小結:
今天,我們穿越水管,從自動化的基礎建設升級到 AI 加值的魔法世界。
在 Hugging Face 魔法工坊初探之後,資料不僅能跨語言流通,還被精煉成更有價值的寶物。
接下來,期待這些魔法碰撞出更多精彩火花,為後續冒險增添強力助力。