在現代 Web 應用中,即時資料傳輸已成為不可或缺的功能。無論是直播串流、AI 生成內容,還是實時監控畫面,我們都需要能夠持續向客戶端推送資料的解決方案。今天讓我們來探索 FastAPI 的 StreamingResponse,看看它如何優雅地解決這些挑戰。

StreamingResponse 是 FastAPI 提供的一個強大功能,它允許我們以串流的方式向客戶端傳送資料。與傳統的 HTTP 回應不同,StreamingResponse 不需要等待所有資料準備完成才開始傳送,而是可以邊產生資料邊傳送,這在處理大量資料或需要即時回應的場景中特別有用。
想像你正在開發一個遠端桌面應用,需要即時傳輸桌面畫面。使用 StreamingResponse 搭配 pyautogui,我們可以輕鬆實現這個功能:
import io
import time
import pyautogui
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
def generate_desktop_stream():
while True:
# 擷取桌面截圖
screenshot = pyautogui.screenshot()
# 將圖片轉換為 bytes
img_buffer = io.BytesIO()
screenshot.save(img_buffer, format='JPEG', quality=70)
img_buffer.seek(0)
# 準備 multipart 格式資料
yield (
b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' +
img_buffer.read() +
b'\r\n'
)
time.sleep(0.1) # 控制幀率
@app.get("/desktop-stream")
async def desktop_stream():
return StreamingResponse(
generate_desktop_stream(),
media_type="multipart/x-mixed-replace; boundary=frame"
)
透過調整 time.sleep() 的值,我們可以控制傳輸的幀率來平衡流暢度與頻寬使用。
記得要額外安裝套件:
pip install pyautogui pillow
接下來,啟動 FastAPI 之後,就可以使用 VLC 或 Pot Player (或其他類似工具)來打開串流網址:http://127.0.0.1:8000/desktop-stream
或是也可以寫一個簡單前端:
# main.py
from fastapi.responses import HTMLResponse
# ...
@app.get("/demo", response_class=HTMLResponse)
async def hello_world():
return """
<body style="background: white;">
<div style="margin: 0px auto;">
<img src="/desktop-stream" />
</div>
</body>
"""
接下來只要打開瀏覽器進入 http://127.0.0.1:8000/demo 就可以看到桌面直播了。
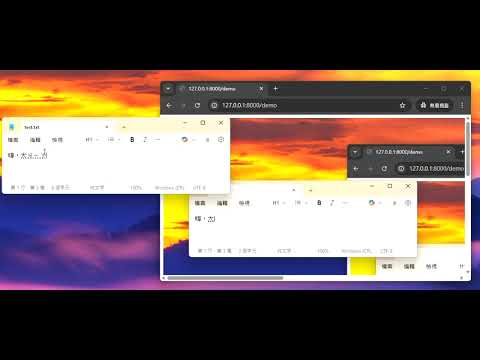
(這是影片)
在 AI 應用中,我們經常需要將 AI 模型的回應即時傳送給使用者,而不是等待完整回應生成完畢。這在聊天機器人或內容生成應用中特別重要:
from google import genai
from google.genai import types
# Gemini API 設定
API_KEY = "your_api_key"
# ...
def generate_gemini_stream():
"""生成 Gemini AI 回應的串流資料"""
client = genai.Client(api_key=API_KEY)
response = client.models.generate_content_stream(
model="gemini-2.5-flash",
contents=["Explain how AI works"],
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_budget=0) # 關閉思考模式
),
)
for chunk in response:
if chunk.text:
yield f"data: {chunk.text}\n\n"
@app.get("/gemini-stream")
async def gemini_stream():
"""Gemini AI 串流回應端點"""
return StreamingResponse(
generate_gemini_stream(),
media_type="text/plain; charset=utf-8",
headers={"Cache-Control": "no-cache", "Connection": "keep-alive"}
)
因為 Gemini 有免費 API KEY,所以這邊就選擇用 Gemini 作為範例XD
這個範例展示了如何將外部 AI API 的串流回應轉發給前端,讓使用者能夠看到 AI 正在「思考」並逐字產生回應的過程,大幅提升使用者體驗。
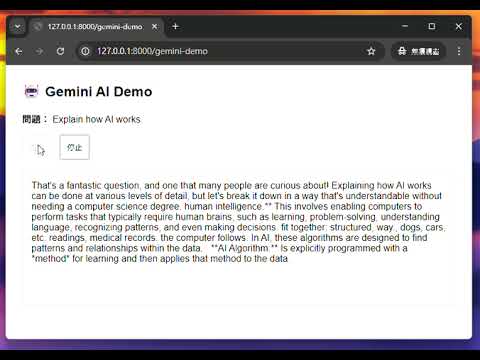
(這也是影片)
想了解怎麼用前端串接這類的文字串流請參考這個 Github 連結 (由於前端程式碼太長了,感覺貼上來太占版面QQ)
StreamingResponse 的核心是生成器函式 (generator function)。使用 yield 關鍵字可以在需要時產生資料,而不是一次性建立所有內容。這樣的設計確保了記憶體使用的效率。
根據傳輸內容選擇適當的 media_type:
multipart/x-mixed-replace
text/plain 或 text/event-stream
application/json
StreamingResponse 為 FastAPI 應用帶來了強大的即時資料傳輸能力。無論是畫面串流、AI 對話,還是其他需要持續資料推送的場景,它都能提供高效且優雅的解決方案。明天會繼續接著介紹 StreamingResponse 的其他應用。


 iThome鐵人賽
iThome鐵人賽