把「看起來像迷宮」的售票頁,拆成可被程式理解的乾淨資料 🧩
今天我們要做的事很單純:把 ibon 活動頁上的票區狀態,變成一份好用的 JSON。
做法是:用 DevTools 找到頁面內嵌的 jsonData → 用 Python 把它解析出來 → 整理成「區域中文名+狀態(張數/熱賣中/售完)」。 
[解析流程]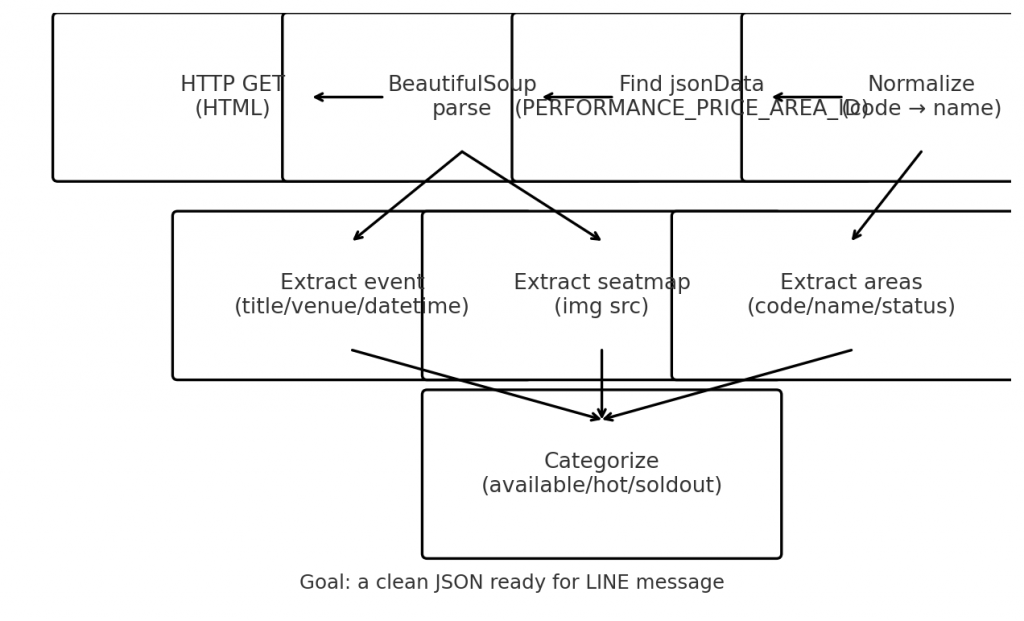
口訣:GET HTML → BeautifulSoup 找資訊 → 鎖定 jsonData(關鍵字:
PERFORMANCE_PRICE_AREA_ID)→ 正規化 → 區域代碼對應中文名 → 分類(可售/熱賣中/售完)
[DevTools 找 jsonData]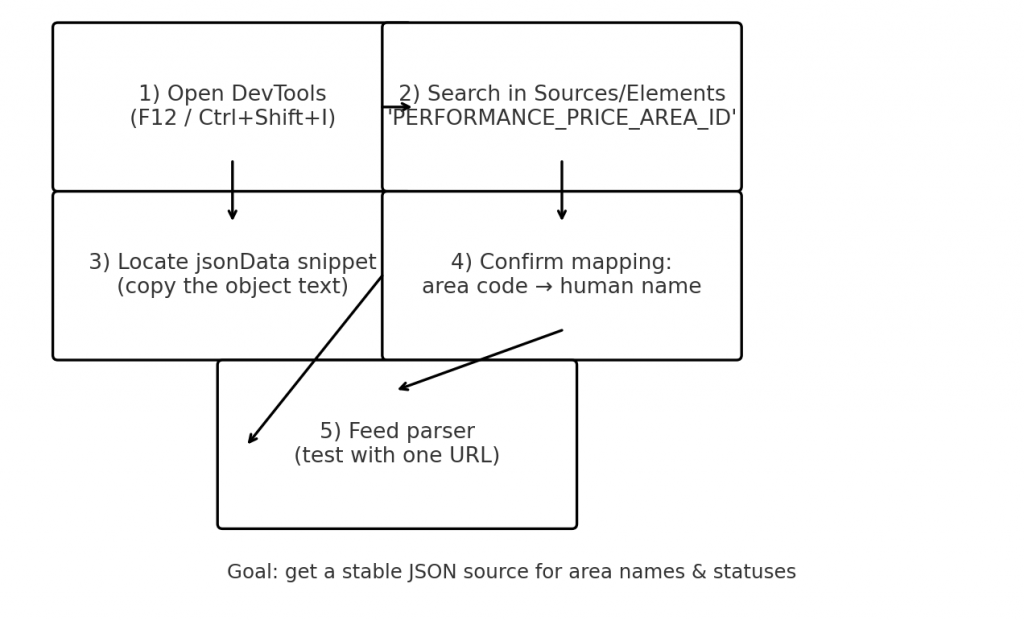
PERFORMANCE_PRICE_AREA_ID、jsonData、或 area
B09P2J33 = 5F B 區 3800)如果今天找不到特定關鍵字,也可以把
<script>內容整段抓下來,用正規表達式從中切出多個小 JSON 物件,逐個嘗試解析。
這段程式碼「可讀可跑」,但因 ibon 頁面結構可能調整,你可以把「選擇器/正規表達式」改成符合當前頁面的版本。
# pip install requests beautifulsoup4 lxml
import re, json, requests
from bs4 import BeautifulSoup
from typing import List, Dict
def fetch_html(url: str, timeout=15) -> str:
headers = {"User-Agent": "Mozilla/5.0"}
r = requests.get(url, timeout=timeout, headers=headers)
r.raise_for_status()
return r.text
def find_json_blob_from_scripts(soup: BeautifulSoup) -> str:
"""
在所有 <script> 文字裡,找包含 PERFORMANCE_PRICE_AREA_ID 或 area 清單的片段。
回傳原始文字(可能含多個物件),等等再逐段解析。
"""
scripts = " ".join(s.get_text(" ", strip=True) for s in soup.find_all("script"))
hit = re.search(r"PERFORMANCE_PRICE_AREA_ID|priceArea|areaList|jsonData", scripts, re.I)
return scripts if hit else ""
def extract_event_basic(soup: BeautifulSoup) -> Dict:
title = soup.select_one("h1, .perf-title, [data-perf-title]")
venue = soup.select_one(".venue, [data-venue]")
dt = soup.select_one(".date, [data-date], time")
# 嘗試找座位圖
seatmap = None
for img in soup.select("img"):
src = (img.get("src") or "")
if any(k in src.lower() for k in ["seat", "map"]):
seatmap = src; break
return {
"title": title.get_text(strip=True) if title else "N/A",
"venue": venue.get_text(strip=True) if venue else "N/A",
"datetime":dt.get_text(strip=True) if dt else "N/A",
"seatmap": seatmap
}
def parse_area_objects(blob: str) -> List[Dict]:
"""
從 blob 中切出多個「看起來像物件」的片段,嘗試 json.loads。
這裡採「盡量嘗試,能 parse 幾個算幾個」的耐髒寫法。
"""
areas = []
# 1) 先把單引號換成雙引號(粗略;實務可用更嚴謹的 parser)
normalized = blob.replace("'", '"')
# 2) 以帶有 area/id/name/status 的物件做粗切
pattern = re.compile(r"\{[^{}]*(AREA|area|name|status)[^{}]*\}")
for m in pattern.finditer(normalized):
chunk = m.group(0)
# 粗暴將未加引號的 key 加上引號(示意;視情況調整)
chunk = re.sub(r'(\b\w+\b)\s*:', r'"\1":', chunk)
# 避免結尾逗號
chunk = re.sub(r",\s*}", "}", chunk)
try:
obj = json.loads(chunk)
except Exception:
continue
# 嘗試映射出 code/name/status
code = obj.get("PERFORMANCE_PRICE_AREA_ID") or obj.get("code") or obj.get("areaId")
name = obj.get("name") or obj.get("areaName") or obj.get("zhName") or code
status = obj.get("status") or obj.get("remain") or obj.get("sellStatus") or "未知"
if code and name:
areas.append({"code": str(code), "name": str(name), "status": str(status)})
# 去重:同 code 取最後一次
uniq = {}
for a in areas:
uniq[a["code"]] = a
return list(uniq.values())
def extract_ticket_info(url: str) -> Dict:
html = fetch_html(url)
soup = BeautifulSoup(html, "lxml")
evt = extract_event_basic(soup)
blob = find_json_blob_from_scripts(soup)
areas = parse_area_objects(blob) if blob else []
return {"event": evt, "areas": areas, "has_json": bool(blob)}
# ---- demo(把 URL 換成你的 ibon 活動頁)----
if __name__ == "__main__":
demo_url = "https://tickets.ibon.com/Show/Index/EXAMPLE"
info = extract_ticket_info(demo_url)
print("event:", info["event"])
print("areas:", info["areas"][:5], "…", f"(total {len(info['areas'])})")
把「雜訊」整理成「一眼懂」:分類+格式化
讓訊息友善是關鍵。以下把區域分成三類:可售(數字)、熱賣中(未公開數量)、已售完。
def bucketize(areas):
avail = [a for a in areas if a["status"].isdigit()]
hot = [a for a in areas if a["status"] in ("熱賣中", "Hot", "hot")]
sold = [a for a in areas if a["status"] in ("已售完", "SoldOut", "sold")]
return avail, hot, sold
def format_preview(info):
ev = info["event"]
avail, hot, sold = bucketize(info["areas"])
lines = [
f"🎫 {ev['title']}",
f"📍 {ev['venue']} 🗓 {ev['datetime']}",
""
]
if avail:
lines.append("✅ 可售:" + " ".join(f"{a['name']} {a['status']}" for a in avail[:8]))
if hot:
lines.append("🟢 熱賣中:" + "、".join(a["name"] for a in hot[:10]))
if sold:
lines.append("🔴 售完:" + "、".join(a["name"] for a in sold[:10]))
return "\n".join(lines)
這張圖只是示意。實務上你可以把 bucketize 的統計值畫成長條圖,讓每次 /check 都能快速掌握「整體健康度」。
結構變了?:先用 DevTools 找新的關鍵字(例如 priceArea、sellStatus),或把 整段拉出來,用 parse_area_objects 逐個嘗試。
中文亂碼?:確認 requests 有用正確編碼(多半自動;必要時 r.encoding='utf-8')。
座位圖抓不到?:改用 if "seat" in src.lower() 以外再加上 floor/map/zone 等關鍵字。
沒有張數只有「熱賣中」?:先分類顯示,下一步再研究互動地圖或其他 API(Day 6 會教你優化訊息排版)。
為了不造成網站負擔,請維持合理頻率(例如 60 秒)。
本專案用途為提醒與資訊整理,購票仍需你親自完成。
用 DevTools 找一個活動頁的 jsonData 片段,貼到程式中試跑。
成功抓到區域清單後,列印 format_preview(info) 看看長相。
把你的成果貼在留言區:「哪一場、抓到了幾個區域、最特別的區域名稱是?」
要把「吵或不吵」調到剛剛好:票數差異比對 & 通知策略(只在該吵時吵你)。
我們會把 diff_areas 的思路講清楚,還會加上簡單的策略切換。 

