前天從 Decision Tree 這個傳統的 Supervised 機器學習模型開始介紹,並在昨天有進一步講解 Supervised、Unsupervised 跟 Semi-supervised Learning 的差別。
今天要介紹另外一個經典的 Supervised 機器學習模型 — Naive Bayes Classifier(貝氏分類器)
在傳統機器學習跟自然語言處理的領域裡,Naive Bayes Classifier 是一個經典的分類方法。
Naive Bayes 的出發點來自於貝氏定理(Bayes’ Theorem)。
它的核心就是我們先根據資料裡已知的資訊,去估計一個類別大概出現的機率。接著,再看某些特徵(像是文章裡的單字)在不同類別下出現的可能性。最後,把這些資訊組合起來,算出文本屬於某個類別的整體可能性。系統就會選擇那個機率最大的類別,作為判斷的結果。
首先我會從貝式定理開始介紹,接著再進入 Naive Bayes。
貝氏定理的公式如下:
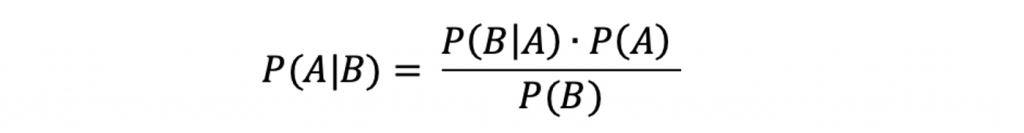
假設我們今天一樣要來分類垃圾郵件跟非垃圾郵件,我會用這個例子來解釋上面這個公式:
A:模型要分類的類別,例如垃圾郵件跟非垃圾郵件B:特徵,例如一封郵件裡面的關鍵字P(A|B):在觀察到特徵後,該郵件屬於某個類別的機率P(B|A):在某個類別下,觀察到該特徵的機率(likelihood)P(B):類別的個別機率舉例來說,如果一封郵件中出現了「discount」和「offer」兩個詞,Naive Bayes 會計算這些詞在垃圾郵件與非垃圾郵件中出現的機率。最後,模型選擇特徵出現機率最大的類別,判斷該封郵件是垃圾郵件還是非垃圾郵件。
Naive Bayes 的「naive」(中文可譯為天真)假設是:所有特徵彼此獨立。換句話說,它假設單字之間沒有相關性。雖然這個假設在真實世界的語料當中明顯不成立,但在實際應用中,Naive Bayes 依舊能達到一定的表現。
Naive Bayes 並不是單一種分類法,而是一個總稱,依據資料型態不同,有不同的類型,以下簡單講解兩種:
Multinomial Naive Bayes
Gaussian Naive Bayes
Naive Bayes 是 NLP 中的一個基於貝氏定理的入門級分類器,它雖然對於特徵的假設「天真」,但是在某些任務當中,像是文本分類、情感分析上可以仍然達到一定的效果。

