LLM(Large Language Model) 是透過大量語料學習「下一個token」的機率,具備語言理解與生成的能力。
昨天提到的 In-Context Learning (ICL) 則讓模型能夠在推論階段,透過「範例」學習任務的形式。
今天要介紹的是 Chain-of-Thought (CoT),可以被視為 ICL 的延伸,它讓模型不只是模仿「答案格式」,而是學習「思考過程」。
假設要模型解這個方程式:
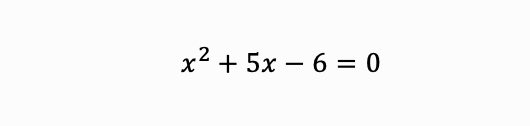
具備 CoT 能力的模型會像這樣逐步推理:
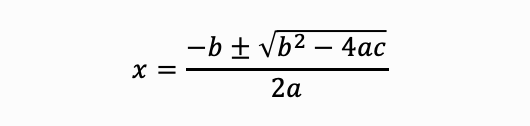
➔ 這些中間步驟就像人類思考的過程,CoT 讓模型模仿這種「思維鏈」,從而提升推理能力。
CoT 是讓 LLM 從「會回答」變成「會推理」的重要關鍵,它結合了 LLM 的語言能力、ICL 的模仿學習能力,讓模型能像人一樣,用語言進行思考!
Reference 1
Reference 2
Reference 3


 iThome鐵人賽
iThome鐵人賽