Extended Page Table(EPT)是 Intel VT-x 的二級分頁技術,用來處理 Guest Physical Address (GPA) 到 Host Physical Address (HPA) 的轉譯。結構與傳統頁表相似。
EPTP(EPT Pointer):在 VMCS 中記錄 EPT 的位置與屬性。
4 級頁表:PML4、PDPT、PD、PT,每頁 512 項,每項為 8 bytes,以下以 4 級頁表為例。
在主觀上,最直覺的想法是先查找 Guest 再查找 Host,也就是:
GVA -> 走 PML4 -> PDPT -> PD -> PT,得到 GPA
GPA -> 走 EPT PML4 -> EPT PDPT -> EPT PD -> EPT PT,得到 HPA
因此看起來就是 4 + 4 = 8 層 page walk。並且假設 TLB miss 的狀況下每查找一層 Guest 表就會觸發一次 8 層 page walk,在性能上是完全不能接受的。
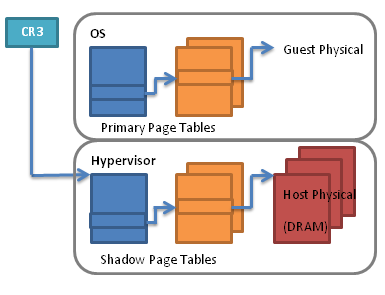
圖片取自 (https://commons.wikimedia.org/wiki/File:Shadowpagetables.png)
在沒有 EPT 的年代,CPU 只能理解 單一份 page table,而且必須是 GVA -> HPA 的直接映射。
因此,Hypervisor 需要額外維護一份 Shadow Page Table (SPT),讓 CPU 使用。
對 CPU 而言,SPT 就是一張標準的四級頁表,能直接提供 GVA HPA 的翻譯;但在背後,Hypervisor 必須監控 Guest 的頁表 (GVA -> GPA),並在 Guest 發生頁表修改時,攔截事件並同步更新到 SPT 中。
但這也造成性能上的問題,每次同步或修改 SPT,都需要 Hypervisor 介入,每次介入都會伴隨一次 VM-exit,導致效能大幅下降。
為了解決此問題,Intel 引入 EPT,由硬體做交錯查查找(2D page walk)。這種方式允許 Guest 自主管理 GVA -> GPA 的頁表,並由 EPT 負責 GPA -> HPA 的轉換,從而減少 VM-exit 的次數。
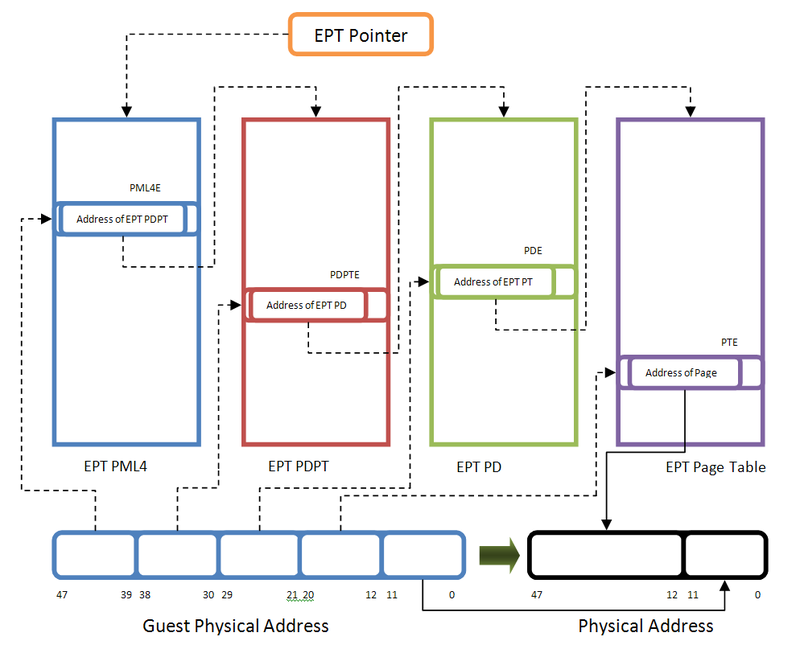
圖片取自 (https://bbs.kanxue.com/thread-281146.html)
Intel 的實作方式並不是先走完 Guest 再走 Host 的逐級查找,而是採用交錯式查找,在這個流程中:
這就是交錯式查找 2D page-walk。
不過這種交錯式的方法在做差的狀況下會需要多達 24 次的記憶體存取(如下圖)。
為了避免這個最差的性能開銷,intel 有一些優化如(nested TLB、Walk Cache、INVEPT/INVVPID),讓執行性能可以接近單純的 4 級分頁。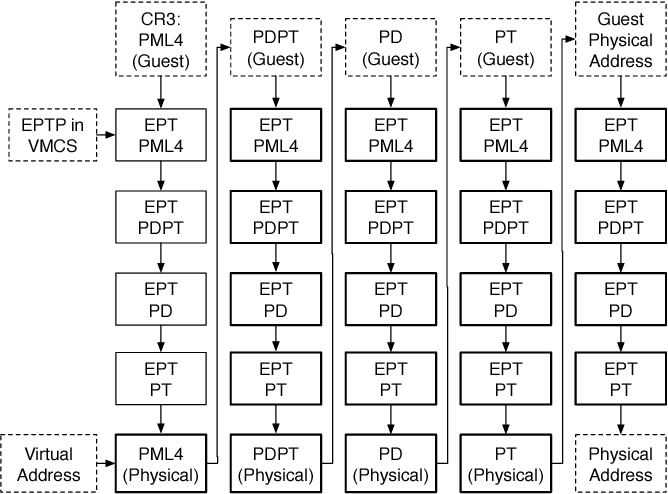
圖片取自 (https://bbs.kanxue.com/thread-281146.html)
開啟虛擬化後,TLB 會直接將兩段翻譯的(GVA -> GPA、GPA -> HPA)最終結果存在 TLB 結構中,直接做到 GVA -> HPA 的映射,另外 TLB 標籤會包函 VPID/EPTP等信息用以區分不同的 vCPU。
又稱 Paging Structure Cache 是 CPU 用來縮短 TLB miss 後查表成本的快取。發生 TLB miss 時,CPU 本來需要從最上層頁表一路往下逐層查找。而 Walk Cache 則是在這個查找過程中介入讓 CPU 可以直接命中先前快取過的中間項(如 Guest 或 EPT 的 PDE、PTE),每次查找就不需從 Host PML4 開始。
再虛擬化的環境下,CPU 會快取很多東西,比如剛才提到的 Nested TLB 與 Walk Cache。當 Guest 更新 page 或是 Hypervisor 修改 EPT 後就需要刷新這些快取。但這裡就衍生一個問題,要刷新多少?
假設我們利用 reload CR3 暫存器刷新所有快取必然造成性能的衝擊,同時造成所有 VM / vCPU 被波及。
因此 Intel 提供兩組指令 INVEPT / INVVPID 讓 Hypervisor 可以只清除必要的快取。


{kind=link}