在前一篇文章中,我們談到 Log 與資料庫的關係,以及系統如何從傳統的批次處理轉向事件流架構。Kafka 正是這場轉變中最具代表性的實作之一,它將「Log」抽象成一個分散式事件流平台,讓資料能以 一致、可重播、可擴展 的方式,在不同系統之間持續流動。
作為一個中間件,Kafka 本身的設計已經相對簡潔,並提供了許多現成的部署方式。像是使用 Kafka Docker Image 就能在幾分鐘內啟動一個測試環境,或者透過 Kubernetes 快速建立 Kafka 集群。然而,隨著應用規模擴大,Kafka 的運行不僅是啟動服務,更需要掌握核心組件與配置細節,以確保穩定與擴展性。
在我們的維運場景中,Kafka 被視為資料流的基礎設施,因此我們選擇導入 Strimzi 來管理它。Strimzi 將 Kafka 的各種服務元件抽象成 Kubernetes 原生資源,讓部署、升級與維護更加自動化與標準化。接下來的章節,我們將透過 Strimzi 官方文件,從 Kubernetes 資源視角 來認識 Kafka 的整體架構與核心組件,並逐步了解它們在事件流平台中的角色與互動。
Strimzi 是一個專為 Kafka 設計的 Kubernetes Operator,用來簡化 Kafka 在 Kubernetes 環境中的部署、管理與維護。Operator 是 Kubernetes 生態中一種常見的設計模式,除了 Strimzi,還有像 Flink Operator、Prometheus Operator 等專案,都是透過程式化方式管理複雜系統。
簡單來說,Operator 將一套系統的「運維知識」自動化,並以 Custom Resource (CR) 的形式呈現在 Kubernetes 中。對使用者而言,這意味著不需要手動建立 ZooKeeper、Kafka Broker、Kafka Connect 等服務,而是直接透過 Kubernetes 原生的 YAML 資源來描述整個 Kafka 集群。
Strimzi 的核心運作可以分為三個步驟:
Deployment 啟動 Operator Pod
Strimzi 以 Deployment 形式運行 Operator Pod,這些 Pod 持續監聽 Kubernetes API,偵測任何 Kafka 自訂資源的變更。
操作 Kafka 專屬 CRD(CustomResourceDefinition)
Strimzi 預先定義好多種 Kafka 專屬資源,方便使用者以 Kubernetes 原生方式管理 Kafka 生態:
Kafka:定義完整的 Kafka 集群KafkaConnect:定義 Kafka Connect 集群KafkaTopic:定義 Kafka TopicKafkaUser:管理使用者與 ACL 權限自動化控制循環(Reconciliation Loop)
當使用者建立或修改 CR 時,Operator 會根據資源規格,自動建立或調整相關的 Deployment、Service、ConfigMap 等 Kubernetes 物件,確保叢集狀態與設定一致。
透過這種模式,Strimzi 將傳統需要手動維護的 Kafka 基礎架構,轉化為 Kubernetes 原生的自動化流程。這不僅降低了維運複雜度,也讓 Kafka 的升級、擴容、權限管理等操作更加標準化與可重複。
在接下來的章節,我們將從 Strimzi 的資源結構出發,逐步解析 Kafka 的整體架構與核心組件,並說明它們如何協同運作,支撐高可用、可擴展的事件流平台。
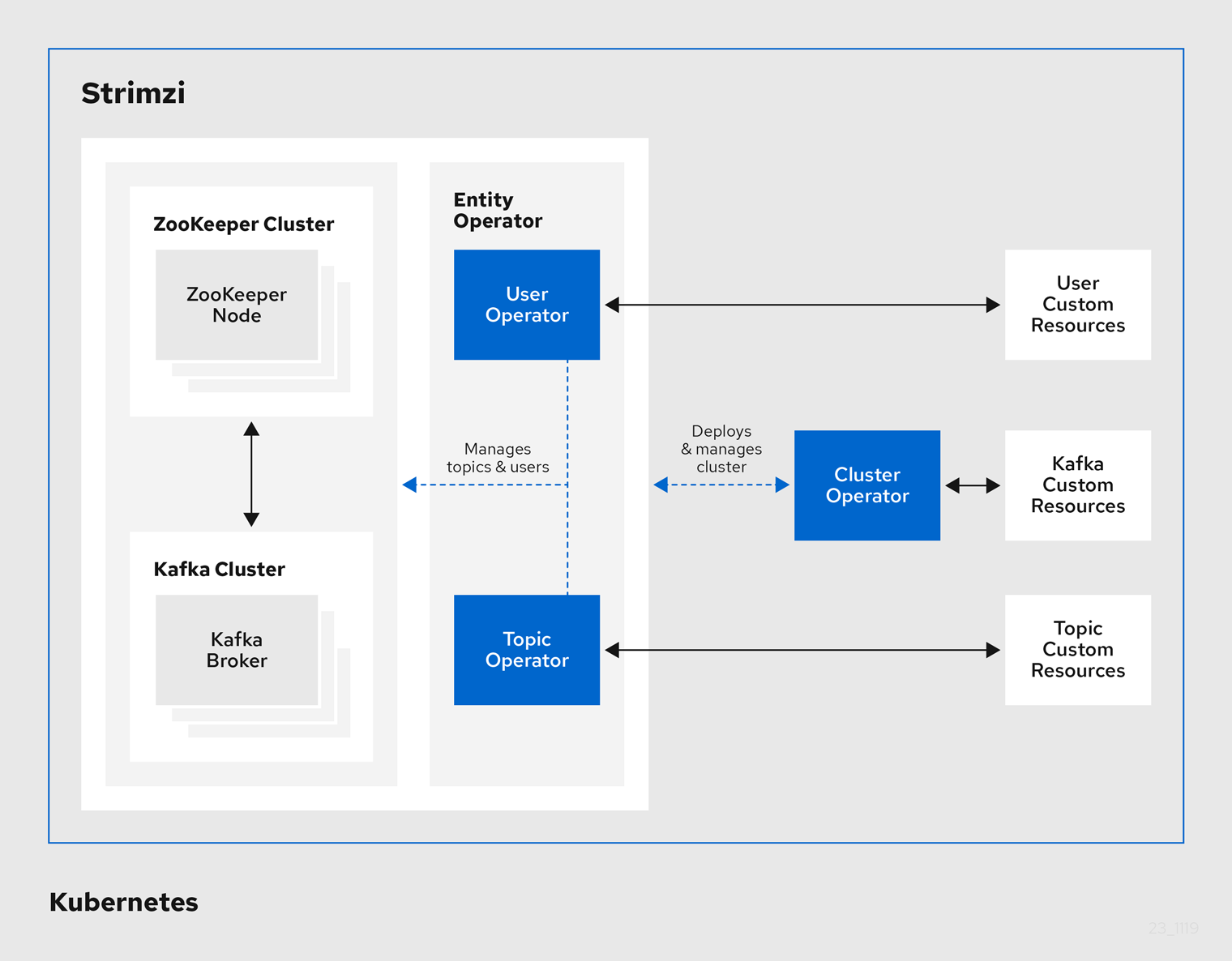
圖示來源:Strimzi 官方文件
在 Kafka 生態系中,Broker 是事件流的核心,但要在生產環境中穩定運作,往往還需要一系列輔助元件來支撐。這些元件各自扮演不同的角色,確保資料能被安全地 生產(produce)、消費(consume)、轉換(transform) 以及 傳遞(transfer) 到其他系統。
以下是 Kafka 主要的支援組件與其功能:
| 組件 | 主要功能 | 在整體架構中的角色 |
|---|---|---|
| ZooKeeper / KRaft | 叢集管理、節點協調、Topic 與 Partition 中 metadata 儲存 | 負責 Broker 之間的共識(KRaft 模式下取代 ZooKeeper) |
| Kafka Connect | 將資料與外部系統同步,例如資料庫、雲端儲存服務 | 充當資料進出 Kafka 的橋樑 |
| Kafka MirrorMaker | Kafka 與 Kafka 之間的資料複製 | 跨叢集資料同步(常用於多地部署或災難備援) |
| Kafka Bridge | 將 Kafka 資料以 HTTP/REST API 方式存取 | 適合無法使用原生 Kafka 客戶端的服務 |
| Exporter(如 JMX Exporter) | 提供 Kafka 的監控數據 | 整合監控系統,如 Prometheus、Datadog |
說明:
- Kafka 傳統上依賴 ZooKeeper 進行集群管理,但在新版 Kafka 已逐步過渡到 KRaft(Kafka Raft) 模式,將元數據管理內建於 Kafka 內部,簡化架構並降低外部依賴。
- 其他模組如 Kafka Connect、MirrorMaker 等,通常會根據企業的資料流需求,選擇性地加入架構中。
下圖展示了 Kafka Broker 與各種支援性元件的關係,讓我們對整體資料流有更直覺的理解:
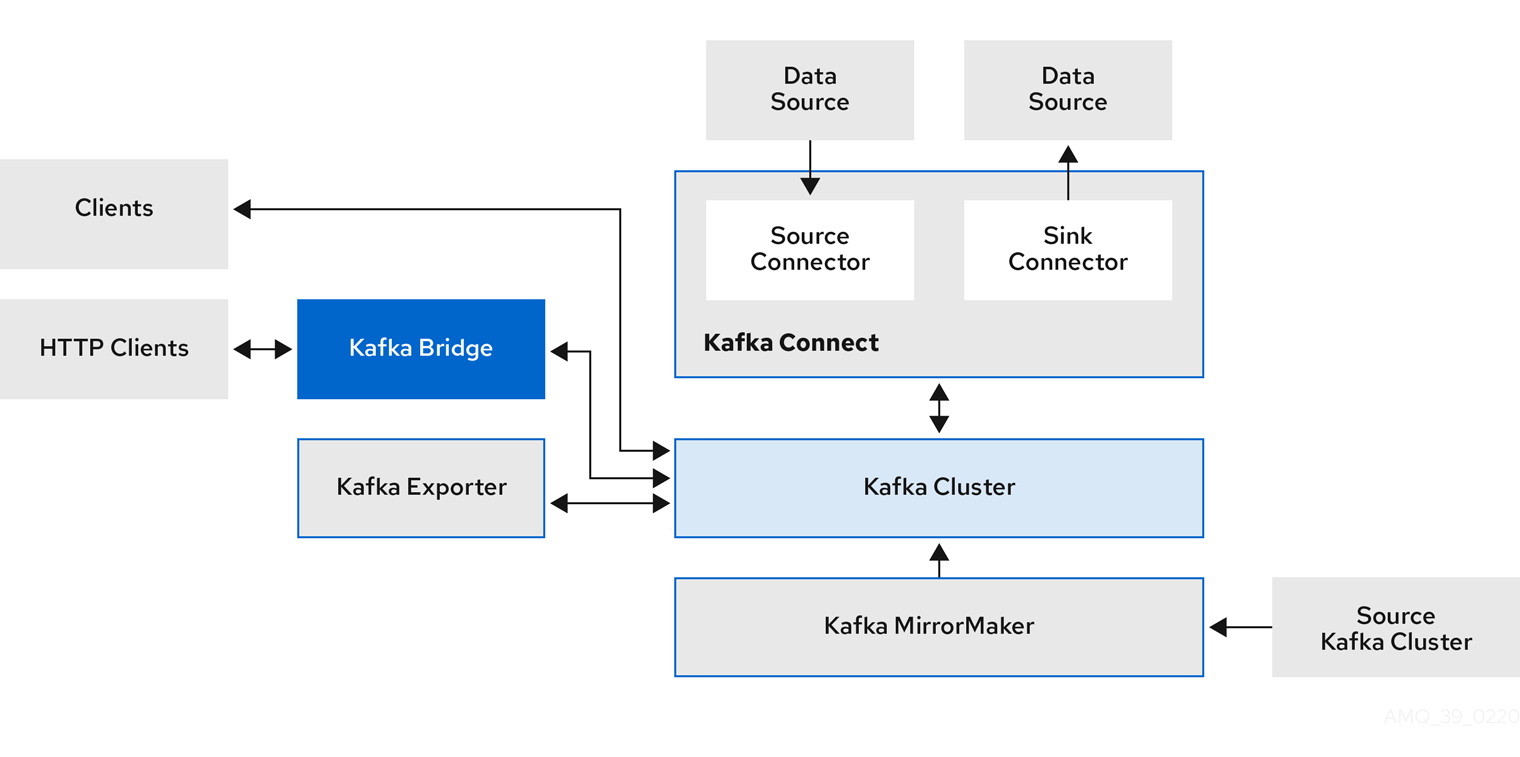
從圖中可以看出:
Kafka 的核心設計理念是透過 分散式架構 來處理大量的事件流,將資料切分、分配到多個節點上,達到 高效能 與 水平擴展。
要理解 Kafka 如何運作,我們先從兩個最核心的概念開始:Broker 與 Topic/Partition。
舉例:
如果一個 Kafka 叢集有三台機器(Broker 1、Broker 2、Broker 3),它們會各自負責一部分資料,分擔整體負載。
這樣的設計讓資料處理變得更靈活,因為每個 Partition 可以被分配到不同的 Broker 上,達成並行處理。
假設有一個名為 orders 的 Topic,並且設定成三個 Partition,則三個 Partition 會分散儲存在三個不同的 Broker 中:
Topic: orders
├── Partition 0 (儲存在 Broker 1)
├── Partition 1 (儲存在 Broker 2)
└── Partition 2 (儲存在 Broker 3)
這代表:
下圖展示了資料如何被分散儲存:

在上一章我們了解了 Broker 與 Topic/Partition,並看到 Kafka 如何將資料分散儲存在叢集中。
但儲存只是第一步,Kafka 的真正價值在於 資料流的傳遞與串接。這就需要兩個重要角色來完成:Producer(生產者) 與 Consumer(消費者)。
Producer 是資料的來源,負責將事件(Event)或訊息(Message)送入 Kafka 中。
決定要寫入哪個 Topic
每一筆訊息都會被指定到一個 Topic,Kafka 依此決定如何儲存和分流。
Partition 分配
當 Topic 有多個 Partition 時,Producer 需要決定該筆資料要寫入哪個 Partition,常見策略有:
舉例:
- 電商系統可使用「會員 ID」當作 Key,讓同一位會員的操作紀錄保持在同一 Partition。
- 訊息通知服務可以使用輪詢,讓訊息平均分散,提升吞吐量。
Consumer 則是資料的使用者,負責從 Kafka 中讀取資料並進行後續處理,例如:
Kafka 的消費模式設計得非常彈性,核心概念如下:
消費者群組(Consumer Group)
舉例:
假設一個 Topic 有三個 Partition,而 Consumer Group 內有三個 Consumer,Kafka 會自動分配如下:Partition 0 → Consumer A Partition 1 → Consumer B Partition 2 → Consumer C如果之後新增第四個 Consumer,Kafka 會自動重新分配(Rebalance)。
以下圖為例,展示了從 Producer 到 Consumer 的完整資料流動過程:
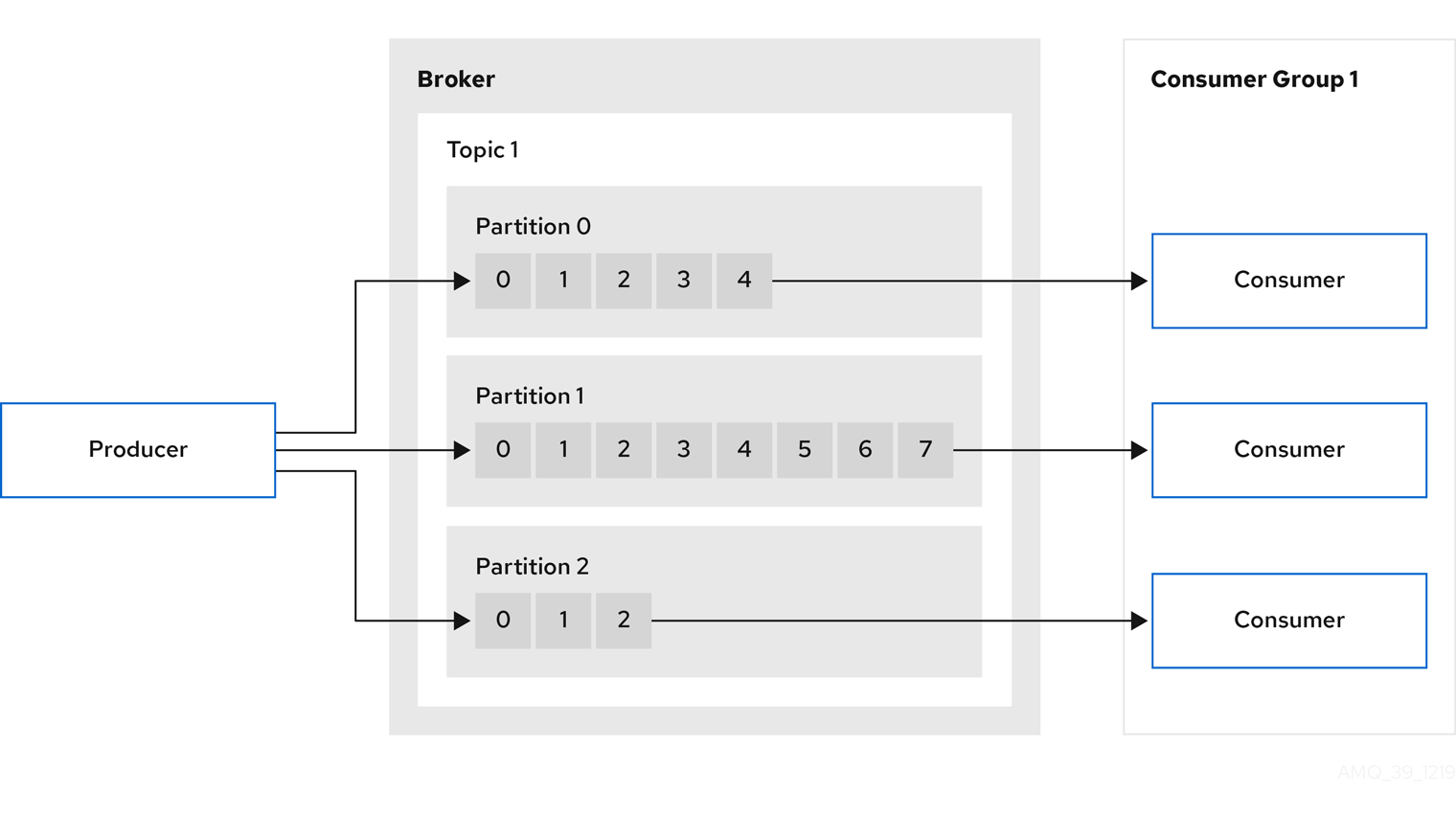
這樣的架構讓 Kafka 成為 鬆耦合(Decoupled) 的中介層:
到目前為止,我們對 Kafka 的核心架構與資料流機制已有完整認識:
Kafka 核心組件
Strimzi 的角色(輔助)
總結來說,Kafka 是事件流平台的核心,其設計讓資料能夠高效、可靠地流動;對初學者而言,可以先用簡單的 Producer → Broker → Consumer 流程來理解整個資料流,逐步熟悉細節後,再深入 Partition、Replica 或 Consumer Group 的概念。Strimzi 則作為管理工具,使 Kafka 在 Kubernetes 環境下更容易部署與維護。
希望這篇文章能幫助讀者更直觀地理解 Kafka 與 Strimzi,並在未來的資料流架構設計與實作中,提供實用的參考。
感謝各位的閱讀,我們明天見!

