大家好!在 Day 16,我們的「省錢拍拍」App 已經學會了「閱讀」,能夠透過 ML Kit 將發票圖片中的文字提取出來。現在,我們手裡握著一長串從發票、收據、價格牌掃描出的原始文字,例如:
「7-ELEVEN ... 發票 ... 熱狗 35 ... 拿鐵 55 ... 總計 90 ... 特價 49 ...」
這段文字包含了所有資訊,但它是雜亂無章的。我們該如何從中精準地找出我們想要的資訊呢?靠傳統的字串搜尋或正規表示法嗎?那將會是一場噩夢,因為不同發票或收據的格式都不同。
這正是現代大型語言模型(LLM)大展身手的舞台!今天,我們將正式為 App 接上 AI 大腦——Google Gemini API。我們將學習如何獲取 API 金鑰,並成功地將 OCR 辨識出的文字發送給 Gemini,讓它為我們進行初步的理解與整理。
要使用 Gemini API,首先你需要一把專屬的「鑰匙」。Google AI Studio 提供了免費的額度供開發者使用。
⚠️ 極度重要警告 ⚠️
API 金鑰就等同於您的密碼,擁有它就等於能以您的名義和額度使用 API。切勿、絕對不要將 API 金鑰直接寫在程式碼中,然後上傳到公開的 GitHub 儲存庫!
Google 已經為 Dart/Flutter 開發者準備好了官方套件 google_generative_ai。
在終端機執行以下指令,它會自動抓取最新穩定版並加入 pubspec.yaml。:
flutter pub add google_generative_ai
遵循我們的架構原則,所有與 Gemini 相關的操作都應該封裝在一個專屬的 Service 中。這次,我們將加入更完善的錯誤處理和效能優化。
在 lib/services 資料夾下建立一個新檔案 gemini_service.dart。
// lib/services/gemini_service.dart
import 'package:google_generative_ai/google_generative_ai.dart';
class GeminiService {
// 警告:將 API 金鑰直接寫入程式碼有安全風險,請務必替換成您自己的金鑰
final String _apiKey = 'YOUR_API_KEY_HERE';
Future<String?> analyzeReceiptText(String ocrText) async {
// 優化:如果 OCR 文字是空的或包含錯誤訊息,就直接返回,不浪費 API 呼叫
if (ocrText.isEmpty || ocrText.contains('無法辨識')) {
return 'OCR 文字為空或辨識失敗,無法進行 AI 分析。';
}
try {
// 1. 初始化模型,可以看一下 Google 目前有提供哪些模型
final model = GenerativeModel(
model: 'gemini-2.0-flash-lite',
apiKey: _apiKey,
);
// 2. 建立我們的 Prompt (提問)
final prompt =
'這是一張發票或收據的原始文字,請幫我用自然語言,簡潔地總結一下這張收據的內容,例如店家名稱和總金額。請用繁體中文回覆。\n\n'
'--- 發票文字開始 ---\n'
'$ocrText\n'
'--- 發票文字結束 ---';
final content = [Content.text(prompt)];
final response = await model.generateContent(content);
return response.text;
} on GenerativeAIException catch (e) {
// 優化:捕捉 Gemini 特有的例外,提供更明確的錯誤訊息
print('Gemini API 錯誤: ${e.message}');
return 'AI 分析失敗,請檢查 API 金鑰或網路連線。';
} catch (e) {
print('Gemini API 請求失敗: $e');
return 'AI 分析失敗,請稍後再試。';
}
}
}
on GenerativeAIException 來捕捉由 API 本身回傳的錯誤(例如 API Key 無效、請求頻率過高等),提供使用者更具體的錯誤提示。現在,我們將 ScanPage 的流程整合為「一鍵式」操作:使用者點擊「開始辨識」按鈕後,App 會自動完成 OCR,並接著呼叫 Gemini 進行分析,提供更流暢的使用者體驗。
修改 lib/scan_page.dart 檔案。
// lib/scan_page.dart
import 'dart:io';
import 'package:flutter/material.dart';
import 'package:image_picker/image_picker.dart';
import 'package:snapsaver/services/gemini_service.dart';
import 'package:snapsaver/services/ocr_service.dart';
class ScanPage extends StatefulWidget {
const ScanPage({super.key});
@override
State<ScanPage> createState() => _ScanPageState();
}
class _ScanPageState extends State<ScanPage> {
File? _imageFile;
final ImagePicker _picker = ImagePicker();
final OcrService _ocrService = OcrService();
final GeminiService _geminiService = GeminiService();
bool _isProcessing = false;
String? _recognizedText;
String? _geminiResponse;
Future<void> _pickImage(ImageSource source) async {
final XFile? image = await _picker.pickImage(
source: source,
maxWidth: 1600,
maxHeight: 1600,
imageQuality: 85,
);
if (image != null) {
setState(() {
_imageFile = File(image.path);
_recognizedText = null; // 清除舊結果
_geminiResponse = null; // 清除舊結果
});
}
}
// 整合 OCR 與 Gemini 呼叫
Future<void> _processImage() async {
if (_imageFile == null) return;
setState(() {
_isProcessing = true;
_recognizedText = null;
_geminiResponse = null;
});
try {
// 步驟 1: 執行 OCR
final ocrText = await _ocrService.processImage(_imageFile!);
if (!mounted) return;
setState(() { _recognizedText = ocrText; });
// 步驟 2: 如果 OCR 成功,就接續呼叫 Gemini
final aiResult = await _geminiService.analyzeReceiptText(ocrText);
if (!mounted) return;
setState(() { _geminiResponse = aiResult; });
} catch (e) {
if (!mounted) return;
ScaffoldMessenger.of(context).showSnackBar(
SnackBar(content: Text('處理過程中發生錯誤:$e')),
);
} finally {
if (mounted) {
setState(() { _isProcessing = false; });
}
}
}
@override
void dispose() {
_ocrService.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('掃描發票')),
body: Column(
children: [
Expanded(
child: _imageFile == null
? const Center(child: Text('尚未選擇圖片'))
: Container(
padding: const EdgeInsets.all(16.0),
child: Image.file(_imageFile!),
),
),
Expanded(
flex: 2,
child: _isProcessing
? const Center(child: CircularProgressIndicator())
: SingleChildScrollView(
padding: const EdgeInsets.all(16.0),
// 優化:優先顯示 Gemini 結果,若無則顯示 OCR 結果
child: Text(
_geminiResponse ?? _recognizedText ?? '點擊右下角「開始辨識」按鈕進行分析...',
),
),
),
],
),
bottomNavigationBar: BottomAppBar(
child: Row(
mainAxisAlignment: MainAxisAlignment.spaceAround,
children: [
IconButton(icon: const Icon(Icons.camera_alt), onPressed: () => _pickImage(ImageSource.camera)),
IconButton(icon: const Icon(Icons.photo_library), onPressed: () => _pickImage(ImageSource.gallery)),
IconButton(
icon: const Icon(Icons.analytics),
onPressed: (_imageFile != null && !_isProcessing) ? _processImage : null,
tooltip: '開始辨識與分析',
),
],
),
),
);
}
}
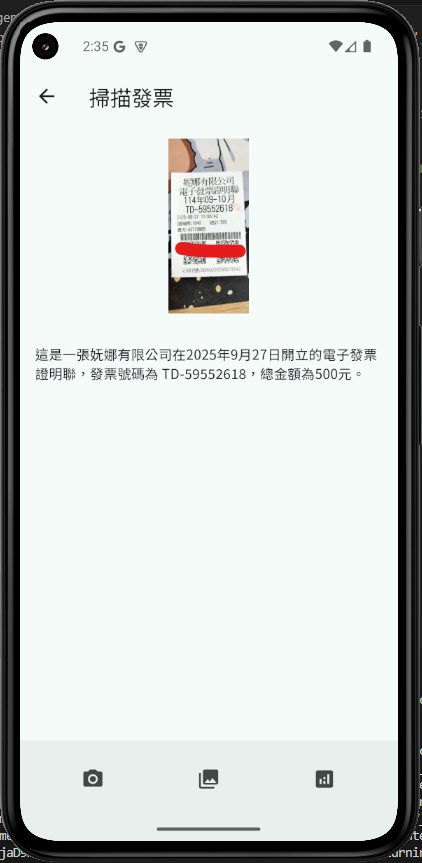
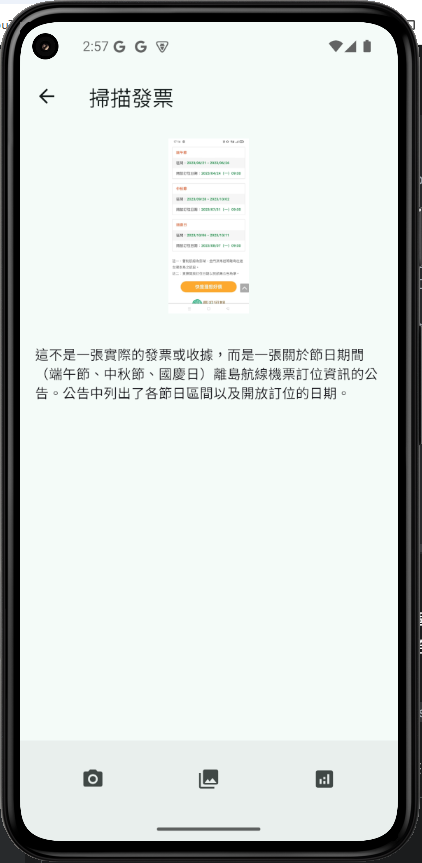
_processImage 現在是一個連貫的自動化流程。觸發後,它會先執行 OCR,緊接著將 OCR 結果直接傳遞給 Gemini 服務進行分析,使用者無需二次點擊。_geminiResponse ?? _recognizedText ?? '...' 的方式,優先顯示 AI 處理過的、更精煉的結果,如果 AI 分析尚未完成或失敗,則會顯示原始的 OCR 文字,提供了更佳的漸進式資訊呈現。這是一個歷史性的時刻! 我們的 App 不再只是一個本地應用,它已經成功地與世界上最先進的 AI 模型之一進行了對話。我們完成了:
google_generative_ai 套件,並以更穩健的方式處理錯誤。然而,今天我們只是讓 AI「自由發揮」。回覆的內容是自然語言,App 還無法直接拿來填入表單。如何讓 AI 成為一個聽話、可靠的資料處理助手呢?
明天,我們將深入探索與大型語言模型互動的核心藝術——提示工程 (Prompt Engineering)。我們將學習如何下達精準的指令,命令 Gemini 從文字中提取出我們想要的特定資訊,並以我們指定的格式回傳!


 iThome鐵人賽
iThome鐵人賽