在前幾天的冒險中,我們修煉了AI加值的魔法。接下來,我們要進一步:將這些魔法拿來應用在生活中。
想像自己是 分析師或產品經理,每月初都要整理 上萬筆顧客評論。如果完全手動處理,不僅耗時,也容易出錯。我們的任務目標是:從海量消費者回饋中,依各個面向找出關鍵的強弱項決定性因素,生成每月智慧報表,包含情緒統計、平均評分、正負向文字雲與雷達圖,並產出可立即洞察的報告,讓主管或團隊一眼掌握重點。
核心觀念是:把零散資料透過AI賦能的魔法、加上統計繪圖的視覺化效果,封裝成一條自動化生產線,—— 這就是我們的 Mario Dashboard。
Mario Dashboard 的冒險步驟
Step 1:資料整理與暫存
今天用到的資料集是 Yelp 資料集,它是一個完整的「用戶-商家-評論」生態資料庫,非常適合用來練習資料清理、分析、NLP 與可視化,甚至做自動化月報或商業洞察演練。不過它的資料量驚人,原始資料光是旅遊類就高達90萬筆,這就是我們遇到的第一個挑戰。
我們的解法是先將原始資料將大檔案分塊
to_parquet存成 Parquet暫存為雲端,方便後續分批讀取與並行處理,提高記憶體效率與運算速度,同時也避免每次都得從頭讀取原始資料算。
Step 2:情緒分析
這次介紹的是 TextBlob 情緒分類,它是 Python 的簡單自然語言處理工具,能快速進行情緒分析、詞性標註和文字操作。特別適合分析評論或社群貼文的正負向情緒,並能輕鬆整合到資料分析流程中。簡單幾行程式就能抓取文字情緒和關鍵資訊,非常適合 NLP 入門或快速原型開發。
透過統計及分析評論文字的情緒 polarity → 正面、負面、中性,我們能快速提供量化指標,直接反映口碑趨勢,作為報表核心數據。
Step 3:關鍵字抽取
針對每則評論提取正負向關鍵字,觀察前100個關鍵字後啟用自訂停用字,並結合sklearn內建的ENGLISH_STOP_WORDS。
透過停用字機制,找出真正具有代表性的關鍵字。這在後續雷達圖、文字雲呈現上,能展現真正有洞察價值的詞。
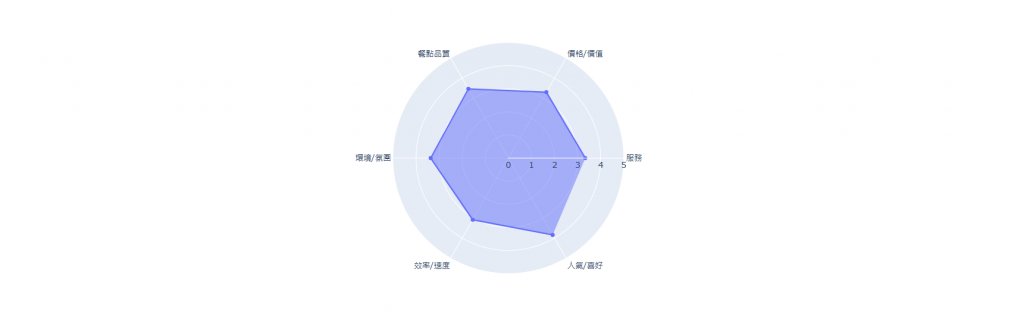
Step 4:雷達圖生成
透過前面抽取的關鍵字,各面向平均評分視覺化。比表格直觀,讀者一眼就能看出各面向表現。
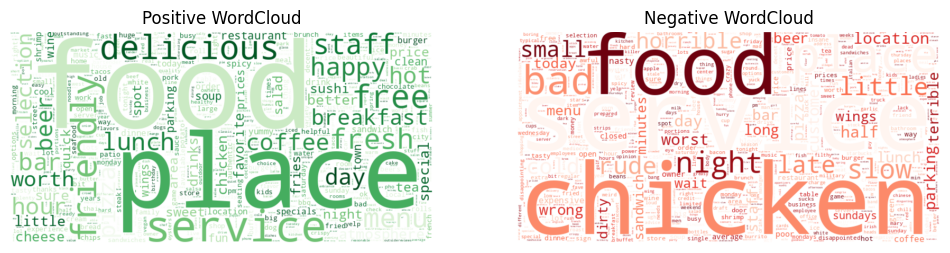
Step 5:文字雲生成
依照正負向關鍵字生成文字雲,讓高頻重要詞直觀呈現,快速抓住評論重點。
Step 6:Pipeline成函式並執行月報生成
把前面的步驟打包成 generate_monthly_report 函式,透過呼叫函式,產生指定月份報表,鎖定分析目標期間,避免干擾資訊。
資料探勘小發現
在整理評論資料的過程中,我們注意到:
- 評論時間分布差異:部分日期評論量特別高,影響平均情緒與評分,可考慮加權或排除極端值。
- 負向評論深度洞察:雖數量少,但常包含產品或服務改進建議,納入報表可提升決策參考價值。
這提醒我們,自動化月報不只是程式自動化,更要在資料前處理與文字分析上下功夫,才能產出高品質洞察。
今天解鎖的新技能:
🍄 資料處理與效能優化:大檔分塊、平行處理、暫存策略,運算穩定高效
🍄 文字分析與 NLP 技巧:TextBlob + 停用字 完成情緒分類、關鍵字提取,生成文字雲與雷達圖
📓 小結:
我們今天把零散的評論資料轉化成高效、可視化的智慧月報,讓「資料到決策」變得高效又可靠。期望未來,它能延伸到更多面向,讓自動化與效率真正落地到日常工作中。