在之前的冒險裡,我們學會了如何提煉評論、視覺化情緒、地圖化呈現。隨著任務越來越複雜,我們需要的不只是一次次的手動施法,而是一條能自動運轉的智慧生產線 —— 這就是 Pipeline。
Pipeline 是一種將資料處理流程自動化、模組化的方法。它能把繁瑣的任務──例如資料清理 → NLP 模型處理 → 視覺化圖表生成 → 報告輸出──依序串接起來。這樣一來,當資料量從幾百筆增長到幾萬筆時,我們不需要重寫程式,只需啟動同一條 Pipeline,就能確保結果一致且高效。未來無論是自動化報表、互動式儀表板,甚至 ChatBot 即時回覆,都得先有這條穩定的生產線。
在自動化的世界裡,Pipeline 就像智慧引擎,負責運算與邏輯。當我們要量身設計功能時,就可以呼叫它。 例如,我們可以透過 Pipeline 在之前學過的 n8n 平台上打造一個自訂 Node,讓 n8n 作為調度者,將外部觸發(如檔案上傳、Webhook、API 呼叫)交給 Pipeline 執行。更酷的是,我們可以把複雜的 NLP、情緒分析或圖表生成封裝成小小積木,讓沒有程式背景的人也能透過拼積木的方式,把 AI 智慧嵌入日常工作中。
Pipeline積木組合步驟
我們這次一樣以 Kaggle 資料集來做示範 將原本負責單一任務的模型積木組合起來,形成完整 Pipeline:
Pipeline 打包示範:
def full_pipeline(df):
print("➡️ 開始翻譯評論...")
df['review_cn'] = df['review'].apply(translate_text)
print("➡️ 開始關鍵字抽取...")
df['keywords'] = df['review_cn'].apply(extract_keywords)
print("➡️ 開始情緒分析...")
df['sentiment'] = df['review_cn'].apply(analyze_sentiment)
print("➡️ 開始摘要...")
df['summary'] = df['review_cn'].apply(summarize_text)
Step 1:翻譯處理:透過googletrans翻譯 API 協助語言翻譯,確保後續關鍵字提取與摘要模型運作順暢。它對多語短評論表現通常很好,但偶爾口語或拼寫錯誤會造成小偏差。
Step 2:關鍵字抽取:使用KeyBERT找出評論核心詞彙。它抓到的詞通常能反映評論重點,但對短句或非常口語化文字,有時會缺漏隱含意涵。
範例:['加德滿都', '山谷', '景點', '美景', '寺廟']。
Step 3:情緒分析:使用sentiment-analysis模型判斷每則評論情緒,標記為 POSITIVE / NEUTRAL / NEGATIVE。它對英文標準句表現穩定,短句、混合語言或諷刺語氣可能判斷錯誤。
Step 4:摘要生成:利用summarization 模型,把冗長評論濃縮成簡短摘要。它能快速濃縮評論,但摘要較簡單,對非常長或多主題評論,細節可能丟失。
範例:「它位於山谷山的頂部。最佳旅遊體驗,推薦一生必訪。」
Step 5:行動建議生成:根據關鍵字與情緒自動生成建議。
範例:針對 ['加德滿都', '山谷', '寺廟'],建議增加導覽說明與遊客休息區。
成果呈現
完成後,我們能看到: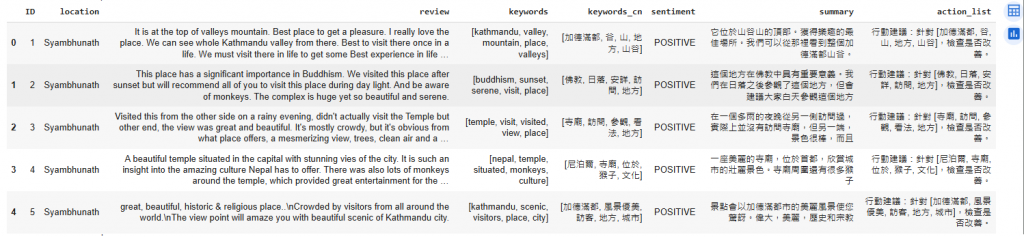
今天解鎖的新技能:
🍄 Pipeline打包:把翻譯、摘要、關鍵字、情緒分析與建議串成一條龍流程
🍄 自動化資料處理:上傳 CSV → 分析 → Excel 下載,全程自動化
🍄 中文化與精簡化技巧:翻譯統一語言,摘要生成短句,讓資料快速可讀
📓 小結:
今天,我們學會了如何在自動化基礎上加入量身訂做的 Pipeline,利用它重複使用、擴充性高、適合大數據量的特性,使智慧生產線更具彈性,為後續擴充以及延伸應用提供更多可能。

