嗨嚕~
前幾篇的內容中,我們很常提到,電腦其實看不懂文字,所以我們必須把文字轉成數值向量,才能進行後續的分析或建模。而這種「文字轉向量」的方法有很多,早期常見的有三種,我們在前幾篇的內容上面也加減有提到一些,像是One-hot Encoding、Bag of Words 以及TF-IDF,然而他們在作法上面都還是存在一些限制還有問題,這邊小小幫大家快速看過一下
1. one-hot encoding
把文本中所有種類的字都變成一個詞表,把她在這個詞表中的位置設為1,其他都是0。
舉例:
I am happy puppy 這句話用One-hot Encoding 的方式轉換,就會像這樣:
I = [1,0,0,0]
am = [0,1,0,0]
happy = [0,0,1,0]
puppy = [0,0,0,1]
缺點:儲存方式很浪費空間,也無法捕捉單詞之間語意的關係,就只有單純的把文字轉化為向量而已
2. Bag of word
跟one-hot encoding 很像,只是one-hot-encoding 是每個字詞都有一個向量,Bag of word 則是將整篇文本轉換為一個向量,向量的每個元素是文檔中每個單詞是否出現。
舉例:
詞彙表:["I", "love", "dogs", "cats", "are", "great"]I love dogs 這個句子就會以這樣的方式表示:I love dogs → [1, 1, 1, 0, 0, 0]
3. Tf-idf
利用計算單詞在文檔中的出現頻率 ( Term Frequency ) 和單詞有出現的文檔數 ( Document Frequency ),決定這個單詞對這篇文檔的重要程度,每個詞也都會算出一個值,但這樣轉換的方式也是會有上述Bag of Word 以及one-hot encoding 的問題。
上述三種轉換文字至向量的方式本質上都是屬於 Sparse Vector(稀疏向量),所以有共同很明顯的問題就是有維度高、空間浪費、無法捕捉語意的問題,因此,後來出現了 Word Embedding的技術,來解決這個問題維度爆炸以及無法捕捉詞的語意的問題
詞嵌入(word embeddings)?
word embeddings 的概念其實很簡單,就是如果兩個詞在語言中語意相近,那麼它們在向量空間中的距離也應該很接近。舉例來說:「國王」跟「皇后」應該比「國王」和「香蕉」更接近,「貓」跟「狗」應該比「貓」和「桌子」更接近,就是當在把文字向量化時後,同時也能捕捉到詞的語意。這樣的表示方式是以低維度、連續值的 稠密向量 (dense vector)來表示。
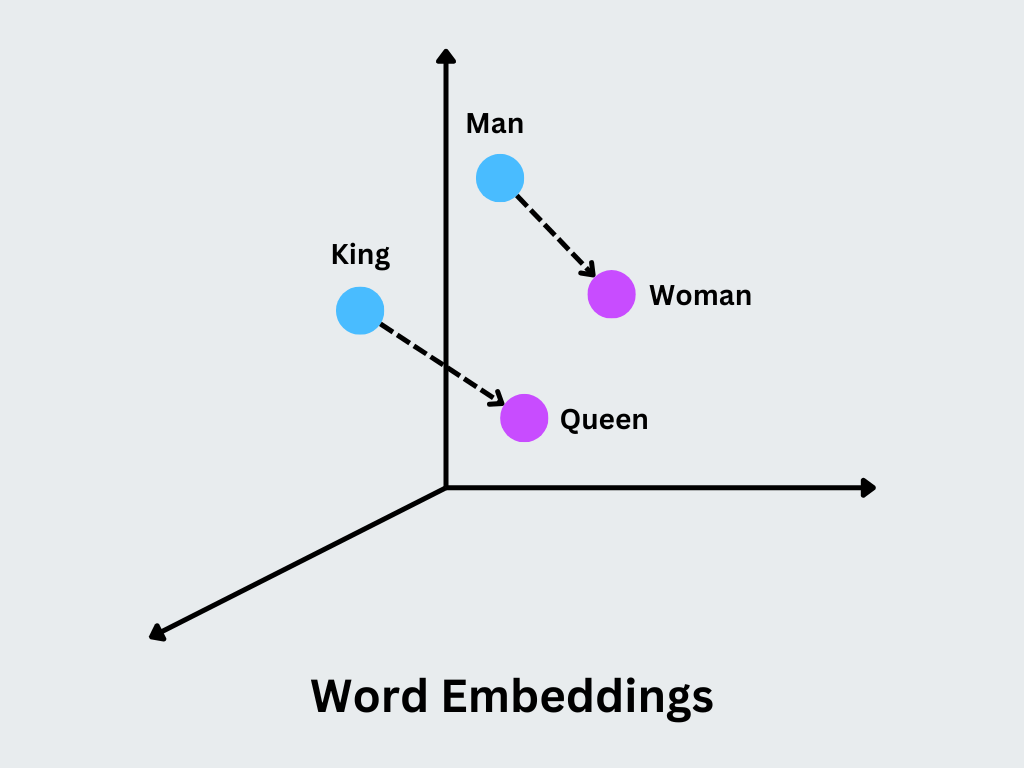
而今天要說的這word2vec 就是一個可以用來表示詞嵌入的的一種技術!
核心概念是透過上下文,讓模型了解詞的語意
模型訓練方式有兩種:skip-gram 和Continuous Bag-of-Words(CBOW)
句子:我是快樂小狗
目標詞=快樂
上下文就是「我」,「是」,「小狗」
在訓練的時候模型會透過觀察很多的詞與上下文的配對,然後去調整參數,最後就可以得出一個向量,而這個向量保留了許多的語意資訊(ex.很常跟哪些詞彙一起出現、一般會出現在哪些上下文中)
在訓練的時候會設定一個 window size,設定模型觀察上下文的範圍大小
我們用一張圖了解一下兩者訓練上差異: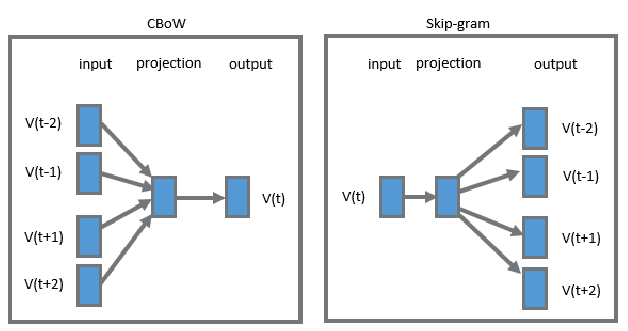
透過上述的方式就能解決傳統文字轉向量遇到的問題了!不過 Word2Vec 還是有一些小小的不足,因為在 Word2Vec 中,每個詞最後都會被轉換成一個固定的向量表示,所以同一個詞在不同情境下語意其實是一樣的,舉例來說,有兩個句子分別是1.我吃飯2. 這個遊戲很吃網速
這兩個句子中的吃明顯是不同意思,但是在 Word2Vec 的向量空間裡,這兩個「吃」都會被表示成一模一樣的向量,因此無法區分語境差異。所以後續就有其他改進方式,能根據上下文動態調整詞的表示方式。也就是說,模型在不同語境中會給同一個詞不同的向量,讓語意能夠更精準。這之後我們有機會再跟大家科普!
今天的分享就到這裡囉~大家掰掰!

