嗨嚕~
不知道大家昨天在學會「怎麼串接 GPT」之後,有沒有自己試著玩玩看呢?
是不是發現他有時候好像蠻聰明,但有時又會突然開始亂講話(氣到想關掉😂)
在我們正式進入「打造專屬聊天機器人」之前,先來看看這些語言模型為什麼有時候會出包,也順便了解一下該怎麼讓它們變得更聰明吧!
有時候用gpt 的時候是不是會氣到懷疑人生?
明明只是想問個簡單問題,它卻回答得一臉自信、結果完全錯誤 🤦♀️
今天的重點就是讓我們來看看為什麼大型語言模型(LLM)有時候會「笨笨的」,以及後來人們是怎麼用 RAG(Retrieval-Augmented Generation) 來解決這些問題的!
基本上常見的問題大概有以下三點:
記得有次gpt 推薦我某篇論文,查一下發現那篇論文根本不存在!!如果沒查證直接引用後果不堪設想啊!!
難以達成「特定領域」需求
大型語言行在訓練的時候通常丟進去訓練的資料不會是特定領域的(就是什麼都會放進去),所以你可能想問特定領域的問題,大型語言模型是沒辦法好好回覆的或者說他無法太深入地回答你這些問題。(例如法律知識)
另外,像是一些比較隱私類型的資訊,像是公司政策、規章等,因為模型訓練時無法取得這些資料,所以如果涉及這些資訊,模型也無法為應你的問題。
無法取得最新資訊
模型的知識會停留在他訓練完的時間點。
什麼意思呢?
如果你問他一個最近才發生的事情,他可能沒辦法給你最新的資料或資訊,因為他的知識已經停在訓練文本的那時候了,我們舉例來說,我們問他一下最近很夯的鬼滅之刃的電影是幾號上映的,他給我的回覆是:
截至我最後更新(2024年10月),官方只宣布「無限城篇」將以三部劇場版上映,尚未公布確切上映日期,也還沒正式上映。現在已是2025年,情況可能有變化。
建議你:
- 查看官方網站或社群:鬼滅之刃官網、Aniplex、ufotable、@kimetsu_off(X/Twitter)
- 查你所在地區的院線與票務平台
- 追蹤 Crunchyroll News、AnimeAnime 等動畫新聞
如果你告訴我所在國家/城市,我可以幫你列出常用的查詢渠道與可能的發行商。
可以看到,模型的資訊會「停留」在他所訓練的資料中,而以這邊的例子來說,在模型訓練時得到的資料可能鬼滅無限城上映日期還沒確認,所以他給的資訊其實以模型的角度來說並沒有錯,只是對我們來說,這已經是過時的資訊了!
而因為語言模型擁有上述提到的這些問題,因此後續就開始出現RAG概念出現,也是我們這次想要告訴大家的重點了!
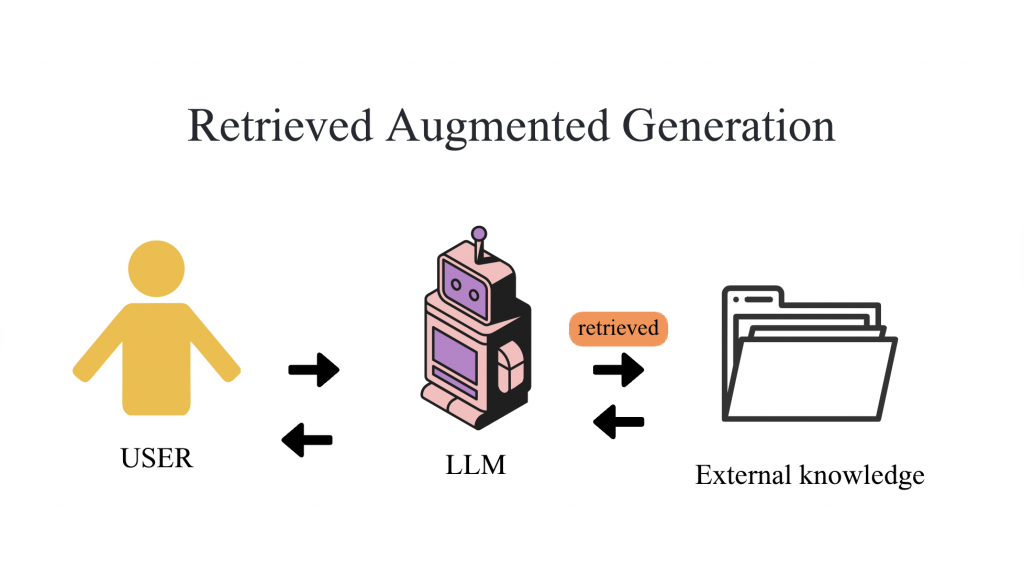
RAG 是 Retrieval-Augmented Generation 的縮寫, 簡單來說,它結合了「資訊檢索系統」和「文字生成模型」這兩種概念。
那它到底是怎麼幫助模型變聰明、解決原本的限制呢?🤔
其實想法很簡單——在模型產生答案之前,它會先被「強迫去看資料」,也就是先從資料庫裡找出相關資訊,再根據這些內容,結合自己內部的知識來生成回覆。
有點像是幫模型開放open book考試的概念,讓它在作答前可以先翻資料、再回答問題。
這樣一來,模型產生的答案就有依據、可追溯,除了能提升準確性之外,也能取得最新、最即時的資訊!
如何達成?
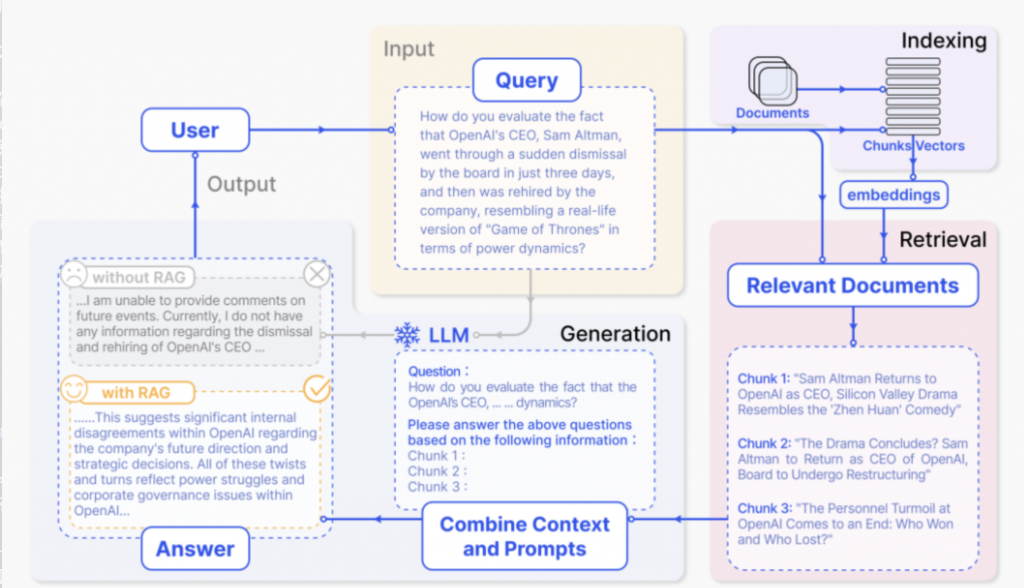
常見在做RAG做法流程會分成三個步驟:
2.Retrieval:
當使用者輸入問題時,系統會把問題也轉換成向量後,去比對資料庫中最相近的段落;最終選出最相關的前 k 個結果。
這樣就能快速找到跟問題最相關的資訊!
3.Generation:
把我們在資料庫中找到的相關資料納入prompt 中,讓大語言模型(LLM)根據這些相關資料,生成答案 這樣模型就不會只依賴自己的知識,還能利用檢索到的外部知識來生成更加準確的答案。
進階RAG(advantage RAG)
當然還有一些更進階的做法,這邊列幾個給大家參考
如果你覺得模型「笨笨的」,可能不是它真的笨,而是因為它的「記憶」有限、知識過時、或根本沒看過你要的資料。而RAG 的出現,無疑是幫語言模型的限制得到很棒的解決方法,透過先查資料再說話,不但能使回答內容更準確、也讓模型能更可靠!
好啦!明天我們將運用RAG技術真正的做出一個自己專屬的聊天機器人!大家敬請期待一下嚕~


 iThome鐵人賽
iThome鐵人賽