把「聲音 → 文字」
流程:
收集資料:大量的語音錄音 + 對應逐字稿(最好有多種口音、音量、背景雜訊)
資料前處理:
降噪、切分語音片段,把音檔轉成 梅爾頻譜 (Mel-spectrogram)
模型選擇:
1.傳統:HMM + GMM
2.現在主流:深度學習模型(RNN, Transformer, wav2vec 2.0, Whisper)。
訓練:讓模型學習「語音特徵 ↔ 文字」對應關係
微調:針對特定領域(例如醫療、客服)加上專屬詞庫
語音合成(Text-to-Speech, TTS)
把「文字 → 聲音」
流程:
收集語音資料:
找一位聲音清晰的配音員錄製數小時以上(幾千到幾萬句)配對的「文字 + 音檔」
前處理:
把文字轉成 音素(語音單位),避免多音字問題,把音檔轉成梅爾頻譜
模型選擇:
1.Tacotron 2(Google)、FastSpeech、VITS(現代端到端)
2.聲碼器(Vocoder,如 WaveNet、HiFi-GAN)把頻譜轉成真實波形
訓練:學習「文字/音素 → 聲音特徵 → 波形」
應用:可以生成不同語氣、情感,甚至做聲音克隆
簡易實作:用edge-tts生成語音
1.建立venv讓自己是在虛擬環境下進行
2.安裝edge-tts,這邊用pygame當播放模組
3.主程式
3-1.套件
asyncio → Python 的非同步模組,用於非同步執行語音生成與播放
edge_tts → 微軟 Edge TTS API 的 Python 封裝,用來將文字轉成語音
pygame → 用來播放 mp3 音檔
os → 做檔案操作
tempfile → 生成臨時檔案,避免每次都寫死檔名
3-2.speak 函式
text → 要轉語音的文字
voices → 優先使用的語音列表,依序嘗試
success → 標記是否成功播放語音,如果所有語音都失敗就提示使用者
3-3.Edge TTS 生成語音
edge_tts.Communicate → 建立語音物件,指定文字與語音。
save(temp_path) → 將語音生成並存成 mp3。
await → 因為這是非同步操作,需要等待完成。
3-4.播放語音
pygame.mixer.music.play() → 開始播放。
while pygame.mixer.music.get_busy() → 等待播放結束,避免程式提前結束。
await asyncio.sleep(0.1) → 非同步等待,讓事件循環不阻塞。
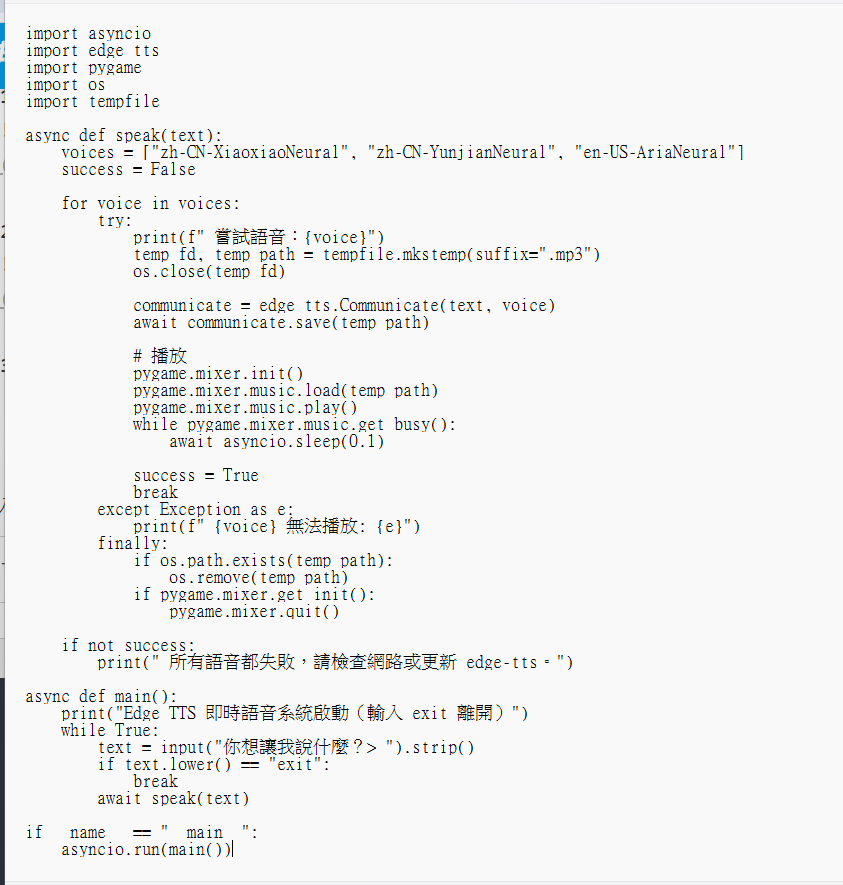
4.執行
5.結果

