一. 前言
在講Gemini 2.5 Pro vs Claude 4.5 vs GPT-5長上下文評估比較之前,我們要認知到他們的發展皆是源自於Transformer模型,他們共同的Transformer基礎都基於注意力機制(Attention Mechanism):
-
自注意力(Self-Attention):模型可以關注輸入序列中的任何位置
-
因果掩碼(Causal Masking):保證生成時只能看到之前的tokens
-
位置編碼(Positional Encoding):賦予tokens位置信息
-
多頭注意力(Multi-Head Attention):並行處理不同類型的關聯
各自的Transformer創新
Claude 4.5的改進:
-
工具調用最佳化:注意力機制專門針對API調用序列優化
-
長時間任務穩定性:支援30+小時持續代理工作
GPT-5的統一架構:
-
推理路由器:智能決定何時使用深度推理vs快速響應
-
彈性輸出:128K輸出能力,突破傳統Transformer輸出限制
Gemini 2.5的多模態融合:
-
跨模態注意力:視覺和文本tokens在同一注意力矩陣中處理
-
模態特定編碼器:針對不同模態的專門處理層
從Transformer模型的演進可分成五個世代:
| 世代 |
代表模型 |
主要創新 |
上下文進展 |
核心挑戰 |
| 第一代 (2017-2019) |
GPT-1, BERT |
基礎Transformer架構 |
512 tokens |
理解語言結構 |
| 第二代 (2019-2021) |
GPT-2, T5 |
規模擴大 + 預訓練 |
1K-2K tokens |
生成連貫文本 |
| 第三代 (2021-2023) |
GPT-3, PaLM |
湧現能力 + In-context Learning |
2K-8K tokens |
複雜推理能力 |
| 第四代 (2023-2024) |
GPT-4, Claude 3, Gemini 1.0 |
多模態 + 長上下文 |
32K-200K tokens |
多模態整合 |
| 第五代 (2024-2025) |
GPT-5, Claude 4.5, Gemini 2.5 |
推理模式 + 工作記憶最佳化 |
400K-2M tokens |
工作記憶瓶頸 |
從上表可以看見最近其的模型遇到的挑戰是"工作記憶瓶頸",以下會談到Gemini 2.5 Pro vs Claude 4.5 vs GPT-5的因應策略,和工作記憶瓶頸的關鍵理論模型BAPO,和兩個沒有字面上的重疊依循,但是卻有關聯性(台灣和花蓮,沒有字面關聯,要讓AI知道花蓮在台灣的關係)的推理方式--NoLiMa基準
二. 三大Transformer模型的工作記憶最佳化策略
Claude 4.5 Sonnet :專精策略
-
架構:改進的Transformer Decoder
-
上下文窗口:264K tokens
-
工作記憶最佳化策略:
- 專注BAPO-easy任務:撰寫程式、程式審查、工具調用
-
Context Management功能,自動清理過時工具調用
-
結果:在撰寫程式領域達到近完美表現
GPT-5 (2025年8月7日發布):平衡策略
-
架構:Reasoning-enabled Transformer
-
上下文窗口:400K tokens (272K輸入 + 128K輸出)
-
工作記憶最佳化策略:
-
彈性推理模式:根據任務複雜度調整工作記憶使用
-
低幻覺設計:犧牲部分創造力以提升準確性
-
結果:在多種BAPO-hard任務中保持穩定性能
Gemini 2.5 Pro (2025年3月24日發布):容量策略
-
架構:原生多模態Transformer
-
上下文窗口:1M tokens(計劃擴展至2M)
-
工作記憶最佳化策略:
-
最大上下文窗口:試圖用絕對容量限制克服工作記憶限制
-
成本最佳化:同樣價錢,可以負擔更多長上下文處理
-
結果:在成本敏感場景中成為首選,但面臨NoLiMa揭示的根本限制
三. BAPO與NoLiMa:揭示1M Token上下文窗口的根本限制
BAPO核心概念解析
BAPO(Bounded Attention Prefix Oracle)是理解工作記憶瓶頸的關鍵理論模型。它將Transformer的計算能力抽象為兩種「頻寬」機制:
雙重頻寬架構
-
Prefix Oracle f(頻寬a):模型在處理輸入時可預先計算並記憶 a 位元的信息
- 等同於人類閱讀時的主動回憶(recall)
- 將關鍵事實編碼到上下文嵌入中直接使用
-
Attention Oracle g(頻寬b):模型可對過去 b 個 token 進行隨機存取
- 類似人類翻頁查找特定段落的能力
- 通過注意力機制檢索相關位置
BAPO-hard vs BAPO-easy分類
BAPO-hard任務(需要大規模工作記憶):
-
圖推理:複雜摘要、實體追蹤、變量追蹤
-
多數決:評論分類、尋找共識意見
-
三元組推理:知識圖譜構建
BAPO-easy任務(工作記憶需求低):
-
索引檢索:Needle-in-a-Haystack式查找
-
等值比較:檢查兩個文檔是否不同
核心洞察:當任務的(a,b)頻寬需求隨輸入規模增長時,模型將不可避免地失敗,遠在達到上下文窗口上限之前。
NoLiMa基準:暴露字面匹配依賴
革命性設計理念
NoLiMa(No Literal Matching)基準測試徹底改變了長上下文評估:
-
ROUGE分數對比:NoLiMa僅0.069,而其他基準0.5-0.9+
-
最小字面重疊:問題與答案間幾乎無詞彙重疊
-
真實關聯推理:依賴世界知識建立Wq↔Wn連接
測試範例解析
經典範例:
針(Needle):"王小明參觀了101大樓"
問題:"誰去了台北觀光?"
答案:王小明
關聯鏈:台北 → 101大樓 → 王小明
這需要模型知道101大樓位於台北,純粹依靠學到的世界知識,無法通過字面匹配取巧。
雙跳(two-hop)推理挑戰
更複雜範例:
問題:"王小明去了哪個國家的首都玩?"
需要推理:101大樓 → 台北 → 台灣
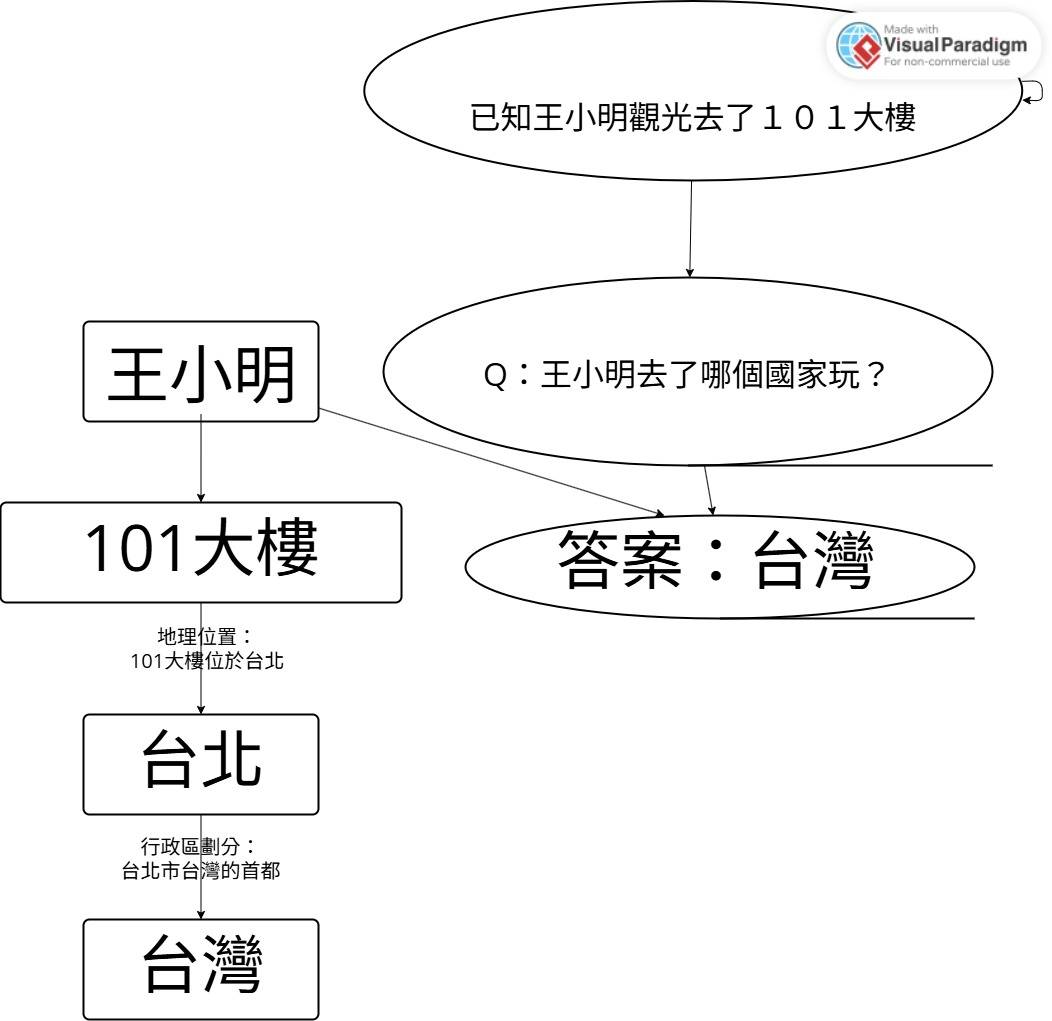
第一跳是知道101大樓位於台北,第二跳是台北是台灣的首都
雙跳推理在長上下文中退化更嚴重,Llama 3.3 70B從70.7%@4K跌至25.9%@32K。
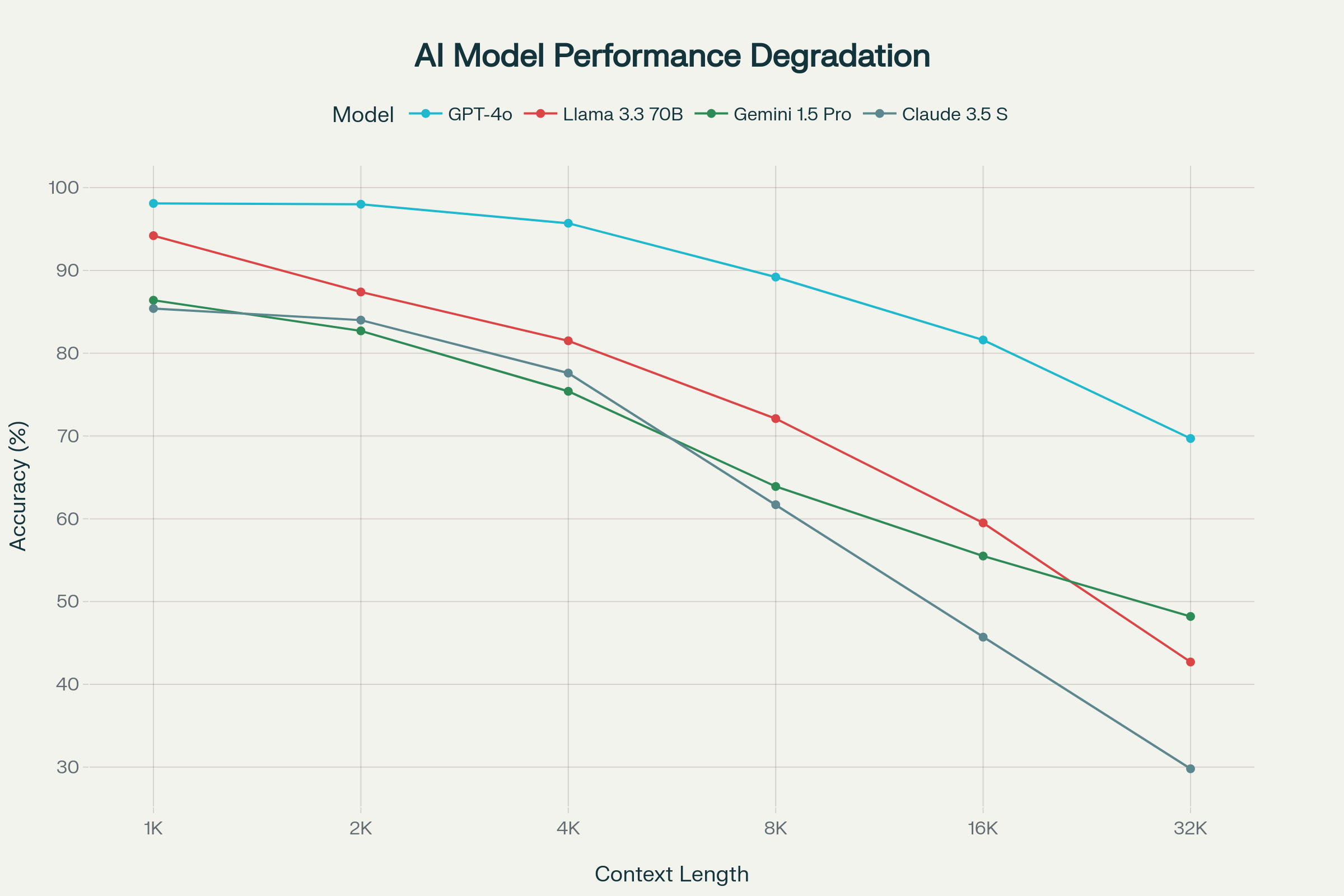
圖片來源: NoLiMa: Long-Context Evaluation Beyond Literal Matching
NoLiMa基準測試:主流AI模型在不同上下文長度下的性能退化
驚人的性能崩塌
與傳統基準的巨大差異
傳統基準vs NoLiMa有效長度對比:
-
Llama 3.1 70B:RULER 32K → NoLiMa 2K(16倍退化)
-
Gemini 1.5 Pro:宣稱2M → NoLiMa 2K(1000倍差距)
-
Claude 3.5 Sonnet:宣稱200K → NoLiMa 4K(50倍退化)
32K tokens時的災難性表現:
- 13個模型中11個降至基線50%以下
- GPT-4o從99.3%基線降至69.7%(30%退化)
- Llama 3.3 70B降至42.7%(56%退化)
- GPT-4o mini災難性降至13.7%(84%退化)
注意力機制的根本缺陷
六大核心限制
-
檢索難度急劇增加
- 缺乏字面匹配時,相關信息定位困難暴增
- 依賴表面線索的脆弱性完全暴露
-
注意力機制過載
- 長上下文壓垮Transformer的工作記憶
- 無法有效處理超出頻寬限制的信息
-
上下文長度主導效應
- 即使相對距離不變,絕對長度增加仍導致性能下降
- 這顛覆了位置編碼是主要因素的假設
-
事實順序的敏感性
- 倒置模板(Wn...CHAR)比默認(CHAR...Wn)更困難
- 因果注意力在不完整事實序列上的根本缺陷
-
分心項的致命影響
- 包含無關字面重疊時,GPT-4o有效長度從8K跌至1K
- 模型被表面訊號誤導,忽略真正相關事實
-
推理增強的局限性
- CoT提示和推理模型在16K+上下文中仍表現不佳
- o1、o3等推理模型在NoLiMa-Hard子集32K時仍降至50%以下
Lost-in-the-Middle的新發現
傳統理解vs NoLiMa發現:
-
傳統 needle-in-a-haystack(NIAH):中間位置性能下降,邊緣位置良好
-
NoLiMa雙跳:整個性能分布向下移動,連邊緣位置也受影響
這表明複雜推理任務中,位置不是決定因素,上下文總長度才是。
對1M Token承諾的根本質疑
參考自Your 1M+ Context Window LLM Is Less Powerful Than You Think
有效上下文vs名義窗口
真實世界應用中的嚴峻現實:
-
RAG系統挑戰:即使檢索到正確文檔,若該文檔與查詢缺乏字面重疊,模型仍可能被其他高重疊但無關的文檔誤導
-
代碼庫分析局限:在分析大型代碼庫時,關鍵邏輯依賴可能通過語義關聯而非字面匹配建立,NoLiMa結果暗示現有模型會遺漏這些關鍵連接
-
學術研究綜述:跨文獻的概念關聯往往需要深度理解,而非關鍵詞匹配,這正是NoLiMa暴露的核心弱點
未來研究方向
基於NoLiMa和BAPO的啟示:
-
新型架構探索:超越Transformer的架構可能是唯一出路
-
混合檢索策略:結合密集檢索和符號推理
-
分層處理方法:將複雜任務分解為BAPO-easy子任務
-
外部記憶增強:專門的工作記憶模組設計
對產業的深遠影響
重新評估長上下文價值:
-
行銷炒作vs實際能力:1M+ token窗口在缺乏字面線索時幾乎失效
-
基準測試偏向:現有評估嚴重高估了模型的真實長上下文能力
-
應用架構調整:需要重新設計依賴長上下文的AI系統
四. 結論:工作記憶才是真正瓶頸
NoLiMa基準測試和BAPO理論共同揭示了一個根本性真相:
1M token上下文窗口的真實價值遠低於宣傳。當任務需要真正的推理而非表面匹配時,即使是最先進的模型也會在相對較短的上下文中失敗。
關鍵洞察:
-
工作記憶瓶頸比上下文容量更嚴重
-
字面匹配依賴是當前長上下文成功的主要原因
-
真實推理能力在長上下文中急劇退化
這些發現不僅質疑了當前大上下文窗口競賽的意義,更指出了下一代AI架構的核心挑戰:如何真正提升有效工作記憶,而非單純擴大名義上下文容量。
對於實際應用開發者,這意味著需要謹慎評估長上下文模型的真實能力,並設計適當的退化策略來處理模型在複雜推理任務中的必然限制。



 iThome鐵人賽
iThome鐵人賽