終於來到最後一個關卡機器人爬蟲防護,先來定義什麼是機器人。
機器人(bot)是一種被程式設計完成特定任務的軟體應用程式,任務可能包含搜尋網路的內容、與網頁互動、與使用者聊天等等。根據Thales 集團發表 《2025年Imperva惡意機器人報告》已指出,機器流量超車人類流量!占比所有網路流量51% !! 報告來源
機器人的用途也分為好跟壞,例如幫忙你找資料寫論文題材的AI爬蟲機器人或是模擬人類對話的聊天機器人,當然也有不當爬取機敏資料以及發起大量憑證填充的惡意機器人。
Jerry,尤其是你們電商的特價產品價格,還有演唱會及特殊活動訂票,更是會有有心人士寫機器人程式來搶票。
好的與壞的
怎麼分辨好的跟壞的,對開發來說干擾WEB主機效能都是壞人,對行銷來說來爬資料幫忙推廣公司活動能見度的是好人,有好的方式可以防護嗎?
顧問回答,Akamai的作法是管理而不是阻擋!!
既然無法杜絕機器人的存取,還可能因為檔到好的機器人導致業務受到影響。
為了能做出良好的管理,必須要針對客戶的流量進行大數據分析,再藉此進行分類並透過不同的方式緩解。Akamai 每天傳輸的全球網路流量佔比高達 15% 到 30%。每天監測這些組織與超過 13 億台獨立設備之間超過 3 兆次的網路互動,因此收到的機器人請求也比任何人都多,數據越多檢測效果就越好,檢測結果就越準確。
怎麼分析的呢? 有幾個重點包含 用甚麼工具存取服務、存取服務時的行為模式、存取服務時的頻率
用甚麼工具存取服務 :既然機器人都是利用程式來存取,很多情況下不會用標準瀏覽器來存取,而使用不同的工具,也會有不同的特徵。
瀏覽器的特徵 : 應該要有accept-encoding、accept-language、Connection、user-agent等等HTTP標頭欄位資訊。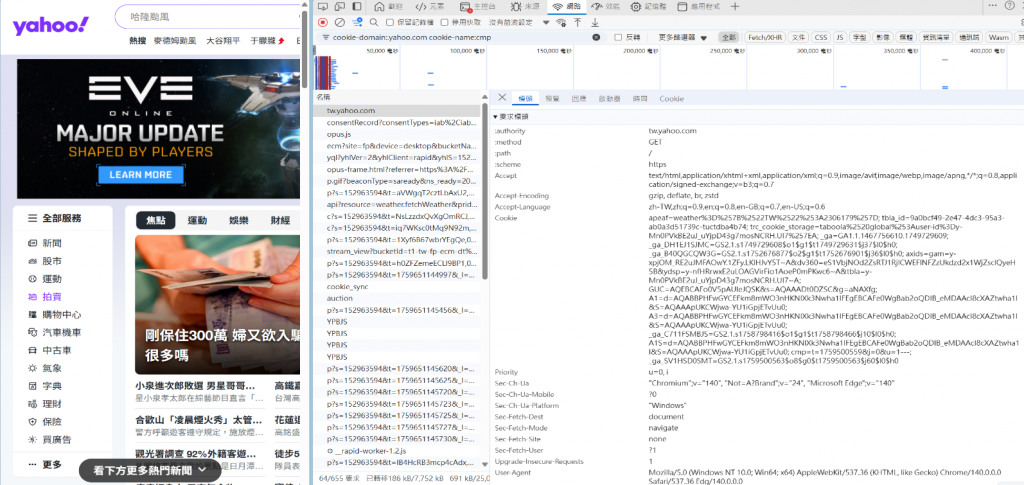
其他工具或AI機器人的特徵 :大部分的工具都會利用user-agent來宣告自己是誰,例如
Google 縮圖機器人 : User-Agent:
Mozilla/5.0 (Windows NT 5.1; rv:11.0) Gecko Firefox/11.0 (via ggpht.com GoogleImageProxy)
AI機器人 : User-Agent:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot
curl工具 :User-Agent:
curl/7.19.7 (x86_64-unknown-linux-gnu) libcurl/7.19.7 OpenSSL/1.0.2l zlib/1.2.5
仿冒瀏覽器 :為躲避機器人防護或是請求特徵分析而遭阻擋的機器人,然後又模仿的不夠認真,例如
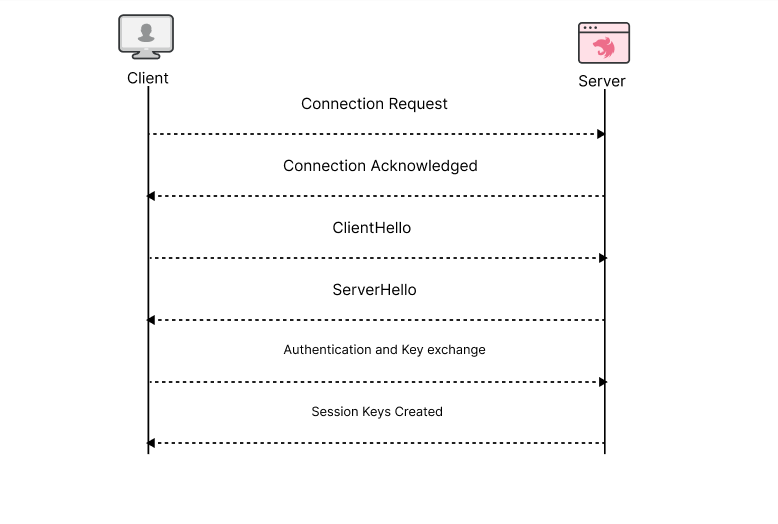
TLS Fingerprint :在開啟 TLS 通訊時,客戶端與伺服器會先經過 TLS handshake。而每套程式或工具在進行TLS handshake 時,包括 TLS 密碼套件、擴充功能和其他參數的有序列表都可以形成一個辨識的特徵,透過這個特徵也能定義來源使用的工具為何。
存取服務時的行為模式 : 對比機器人產生的異常請求,其實可以從以下幾點分析出來
持續性針對特定頁面或功能進行請求,例如
來自雲端或是VPS商網段,請求的物件針對且特定,並非一般使用者瀏覽行為。
存取服務時的頻率 : 依據業務需求,有些資訊會定期的更新。總是會有機器人用你超乎想像的頻率來更新資料,因此分析請求的頻率,也能判斷出是否為自動化程序的機器人流量。
舉個例子:不管訂甚麼票,一般人總是會想一下如何選擇吧! 不太可能在一秒內完成好幾個選項的請求,這就不難判斷出是否為真人?
機器人分類
Akamai將機器人分為三大類:
Akamai 驗證分類的機器人 :Akamai經過大數據分析有明確用途的機器人包含:
Akamai 偵測到的機器人 :透過不同層面特徵請求分析出來,例如不正確的標頭簽章和亂序標頭以及瀏覽器版本不符等,分類包含:
自訂分類的機器人 :依照需求自行定義機器人。
防護
設定方式
Akamai的BOT防護分為兩種授權,因應授權不同可以與機器人互動的方式也不同,目前採購的AAP只有Monitor、Deny、Allow三種動作。
而進階的BOT還多了Captcha(驗證碼)、Slow Delay(延遲回應)、Tarpit(完全不理會)、Crypto challenge(加密挑戰)等機制,可以因應的情境更為多元及複雜。
AAP因授權機制考量,設定時只要針對類別勾選要不要檔即可,進階的回應機制就不多談。
防護規則建議
接下來,每一個防護功能我們都要來評估及討論,先前講的4個項目
能分辨出惡意來源及惡意請求的意圖嗎?
惡意來源:
透過請求的網段再加上User-agent,其實蠻容易辨識出是否為正常來源。
但是近年VPN服務的盛行,VPN服務的主機大多建置於雲端以及VPS商,此時這些平常被視為惡意的來源,瞬間又變成正常人了。
惡意意圖 :
透過平台分析可以初步從BOT的分類確認是用甚麼工具來存取,再依據業務的需求分析存取的資原及物件,也能分析出意圖。
但是針對單一物件或功能一定有問題嗎? 金融的匯率資料、氣候地震資料、車票時間費用等等,可能還是需要其他的考量例如頻率、請求的Mathod、請求參數的準確度等來統一分析,避免誤判。
怎麼判斷?
請務必先從提供服務網站其業務行為進行深入了解,包含
怎麼擋?
阻擋的方式除了直接勾選平台已經定義好的類別外,可依據HTTP請求的標頭內容設定條件阻擋。
會擋不住或是誤擋?
擋不住 :
既然知道了偵測的方式,那麼是否可以繞過呢? 答案是肯定的!!
但也有分有作功課跟沒作的,怎麼說呢?
如果,我知道你一定會檢查瀏覽器的特徵,是不是我仿冒的時候該加的HTTP標頭欄位都加一加?
有TLS Fingerprint跟JS挑戰,網路上已經有公開套件可以協助繞過 ?
認真的要繞過也是有可能的!!
誤擋 :
你更應該擔心誤檔!! 除非開發部門明確的定義及限制,前端所有可存取的方法。
包含以下情況都應該調查清楚:
在沒搞懂前,你只能一直Alert下去,永遠開不了Deny!!
策略整理
評估完後,就綜合評估你可能會遭遇的情境,擬定出防護策略。
其實大部分的情況,開發單位可能也沒想這麼多,也沒法提供給你太多的資訊,所以有以下規劃建議:
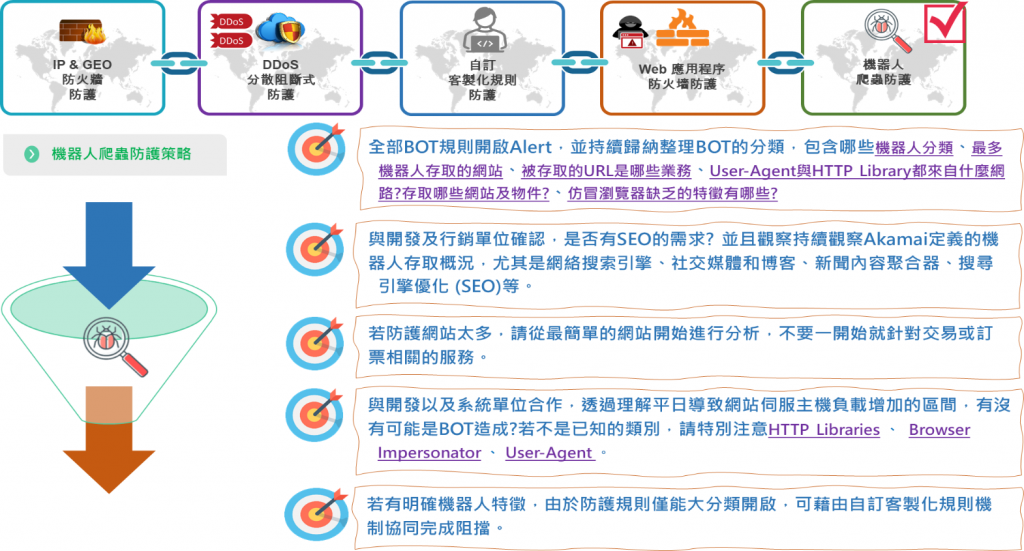
全部BOT規則開啟Alert,每天透過平台用以下條件過濾,透過數據及Akamai BOT分類的歸納,整理出以下資訊
與開發及行銷單位確認,是否有SEO的需求? 並且觀察持續觀察Akamai定義的機器人存取概況,尤其是網絡搜索引擎、社交媒體和博客、新聞內容聚合器、搜尋引擎優化 (SEO)等。
若防護網站太多,請從最簡單的網站開始進行分析,不要一開始就針對交易或訂票相關的服務。有可能你會絕望到都開不了Deny~~~~XD
與開發以及系統單位合作,透過理解平日導致網站伺服主機負載增加的區間,有沒有可能是BOT造成?
承上,若不是Akamai已知的類別造成問題,那後續把心力都花在以下3個項目即可
若有明確機器人特徵,由於防護規則僅能大分類開啟,可藉由自訂客製化規則機制協同完成阻擋。