今天想來聊聊,為什麼SSO服務的反向代理工具,從Nginx換成了Apache APISIX?
從Nginx換成APISIX的,不只是在SSO服務提供架構上。客戶的入口網站也替換成使用APISIX提供服務;目前在進行的新MES系統導入,其架構也在原本設計上做過調整,包含進APISIX做整體的高可用性設計考量。
不過在此前,Nginx在公司內部系統已經穩定地使用了幾年應該有了。Nginx真的是一個很好、很穩定的工具。那是什麼原因,逐步將新舊服務的架構中Nginx換成了APISIX?
會接觸到Apache APISIX,作爲楔子的原因,是我想更進一步實際看看斷路器的機制。Nginx似乎也有相關辦法[^1] [^2],不過在中文文件上,APISIX看起來更容易入門。
[^1]: GitHub - nginx-circuit-breaker
[^2]: Nginx 中实现熔断降级
隨者接觸到APISIX,也開始發現更多新東西。除了限流,印象中可觀測性相關的OpenTelemetry和SkyWalking工具也是此時開始接觸,此外也逐漸發現一些使用APISIX的優點。
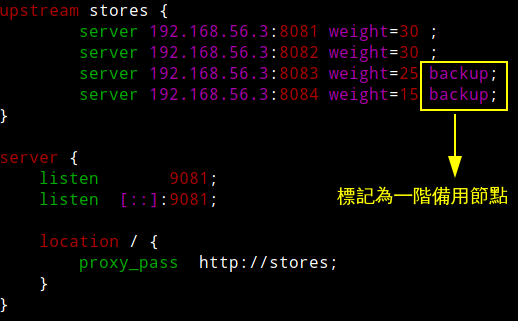
在「百貨公司-負載平衡」的一章例子中,除了Nginx同樣地可以分配不同上游權重外,還可以設定第二階、第三階的使用節點,這在Nginx相對是受限的。
(nginx範例)
upstream stores {
server 192.168.56.3:8081 weight=30 ;
server 192.168.56.3:8082 weight=30 ;
server 192.168.56.3:8083 weight=25 backup;
server 192.168.56.3:8084 weight=15 backup;
}
server {
listen 9081;
listen [::]:9081;
location / {
proxy_pass http://stores;
}
}
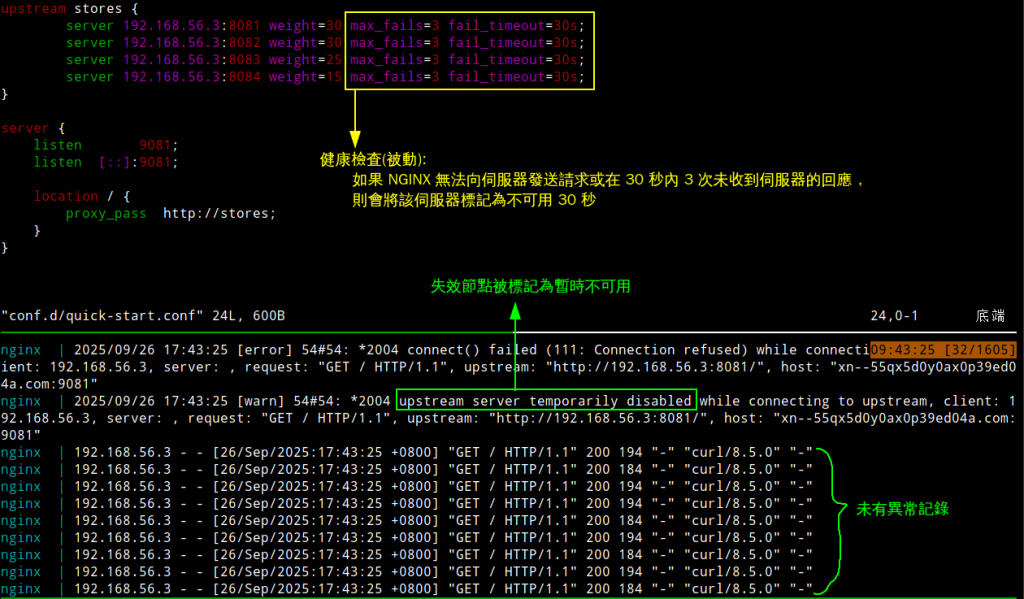
在「健康檢查」一章,提供了主動檢查和被動檢查的方式。初階的Nginx僅提供被動檢查:
(nginx範例)
upstream stores {
server 192.168.56.3:8081 weight=30 max_fails=3 fail_timeout=30s;
server 192.168.56.3:8082 weight=30 max_fails=3 fail_timeout=30s;
server 192.168.56.3:8083 weight=25 max_fails=3 fail_timeout=30s;
server 192.168.56.3:8084 weight=15 max_fails=3 fail_timeout=30s;
}
server {
listen 9081;
listen [::]:9081;
#server_name localhost;
location / {
proxy_pass http://stores;
}
}
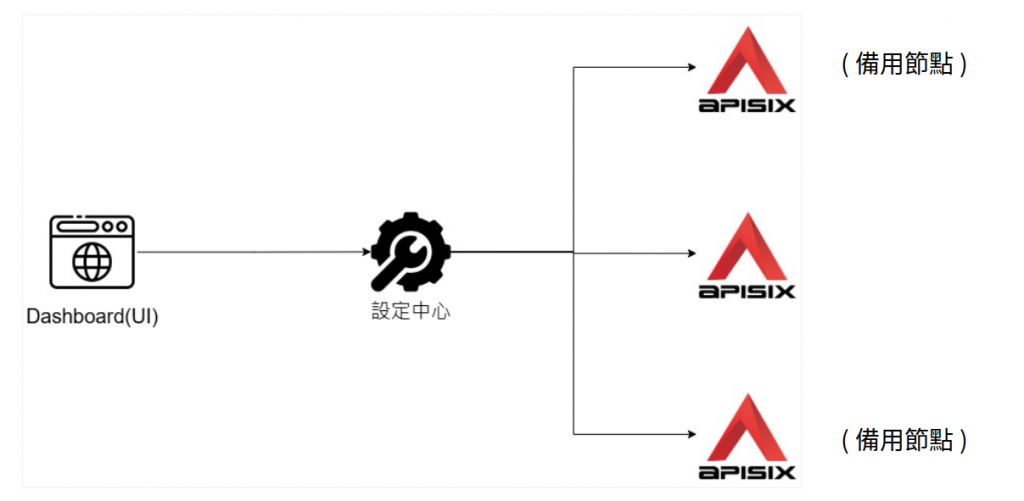
此外,在實際應用環境,為了避免「單點失效」,並不會只準備一個Nginx服務節點。也就是說每次的路由變更,都需要在每一個服務節點進行調整。儘管依然可以利用Ansible等類似工具,做到一次一起調整。但APISIX本身設計上有包含類似設定中心的概念,且Admin API可以更動態的將變更套用到多個服務節點。
最後最後...其實還是有一些私心原因,但讓我留到系列最後再來揭祕。


 iThome鐵人賽
iThome鐵人賽