繼昨天的監督式機器學習模型後,我們今天來談談非監督式學習模型 - 分群模型。
相對於監督式學習是要將訓練的資料提供給模型的同時也會提供其相對應的答案(e.g. 什麼樣的情形會產生什麼樣的數值、什麼樣的情形會產生什麼樣的類別),非監督式學習不會提供相對應的答案。
為什麼選擇分群模型呢?
答案很簡單。。因為這是我目前工作上有建過且成功上線運作的模型。
分群模型最耳熟能詳的應該就是 K-means 了吧。
按距離因素進行分群。
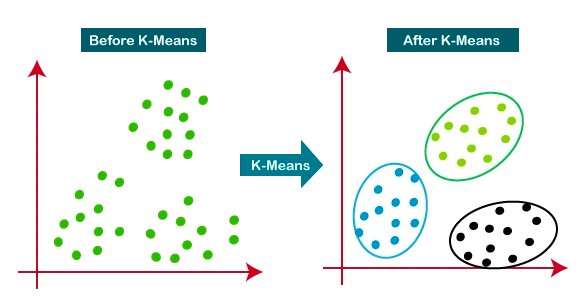
(image from : https://www.analyticsvidhya.com/blog/2021/04/k-means-clustering-simplified-in-python/)
在查找資料時才發現有一些模型要再花時間 study 一下了 : Deep Embedded Clustering, BIRCH, GMM。
但今天想特別談的是非監督式學習的挑戰。。
因為在監督式學習使用的預測模型我可以得出可使用的結果了,但在使用分群模型時,假如我想要找的群它有特定的特徵,但是每次要跑的時候都會分成不同的分群編號,那我要如何進行自動化佈署呢?
這是我目前面臨的問題。。也就是每次要跑的時候都還需要人力的介入進行判斷自己要的是哪一群,再將結果進行下一步運用。
這點如果有路過的大大看到,也歡迎一起交流啊 ~

