/recommend_ab 可根據時間自動切換模型。前面幾天我們已經註冊了 baseline 模型:
現在要補上內容式(Content-Based)模型:
有了這兩個模型,我們才能進行真正的 A/B 測試比較。
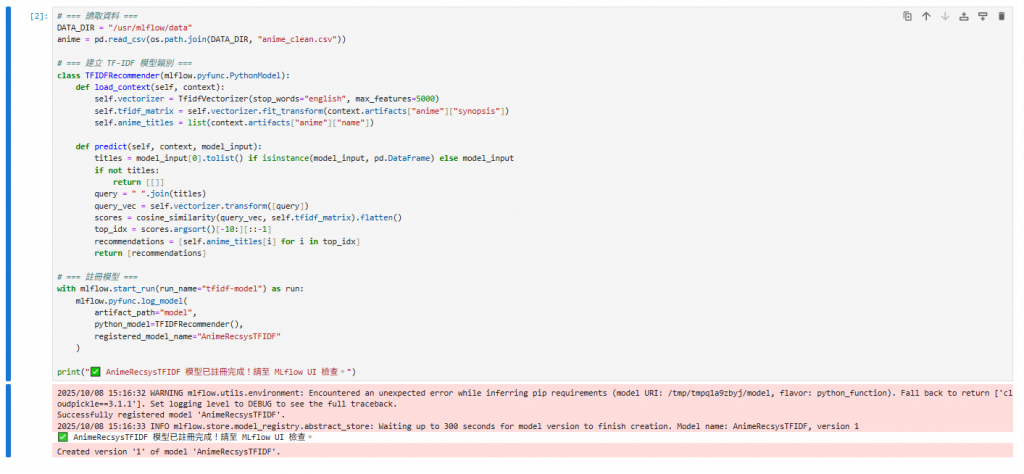
day25_register_tfidf.ipynb 並註冊模型📓 Notebook 名稱:day25_register_tfidf.ipynb
import mlflow
import mlflow.pyfunc
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import os
# === 連線到 MLflow Server ===
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-tfidf")
# === 載入資料 ===
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
# 儲存一份到 artifacts 資料夾
ARTIFACT_DIR = "./artifacts"
os.makedirs(ARTIFACT_DIR, exist_ok=True)
anime_path = os.path.join(ARTIFACT_DIR, "anime.csv")
anime.to_csv(anime_path, index=False)
# === 定義 TF-IDF 模型 ===
class TFIDFRecommender(mlflow.pyfunc.PythonModel):
def load_context(self, context):
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
anime_path = context.artifacts["anime"]
self.anime = pd.read_csv(anime_path)
self.vectorizer = TfidfVectorizer(stop_words="english", max_features=3000)
self.tfidf_matrix = self.vectorizer.fit_transform(self.anime["genre"].fillna(""))
self.anime_titles = self.anime["name"].fillna("").tolist()
def predict(self, context, model_input):
query = " ".join(model_input[0].tolist())
q_vec = self.vectorizer.transform([query])
sims = cosine_similarity(q_vec, self.tfidf_matrix).flatten()
top_idx = sims.argsort()[-10:][::-1]
recommendations = [self.anime_titles[i] for i in top_idx]
return [recommendations]
# === 註冊模型 ===
with mlflow.start_run(run_name="tfidf-with-artifact") as run:
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=TFIDFRecommender(),
artifacts={"anime": anime_path},
registered_model_name="AnimeRecsysTFIDF"
)
print("✅ AnimeRecsysTFIDF 模型重新註冊完成,並附帶 anime.csv!")
# === 可選:自動切換 Stage ===
from mlflow.tracking import MlflowClient
client = MlflowClient()
latest = client.get_latest_versions("AnimeRecsysTFIDF")[0]
client.transition_model_version_stage("AnimeRecsysTFIDF", latest.version, stage="Staging")
print(f"✅ 模型版本 v{latest.version} 已切換至 Staging。")
執行後可在 MLflow UI 的 Models 頁面看到:
| Model Name | Stage | Version | Description |
|---|---|---|---|
| AnimeRecsysTFIDF | None (待切換) | v1 | TF-IDF 相似度模型 |
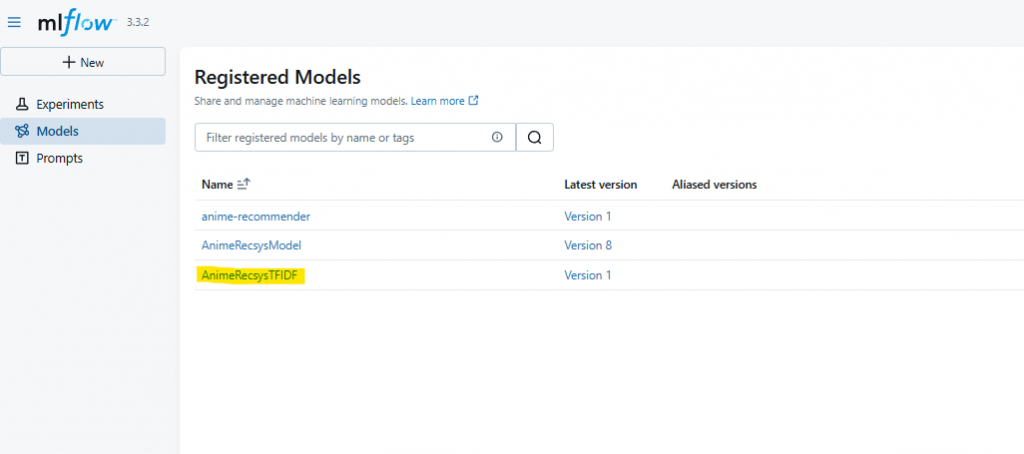
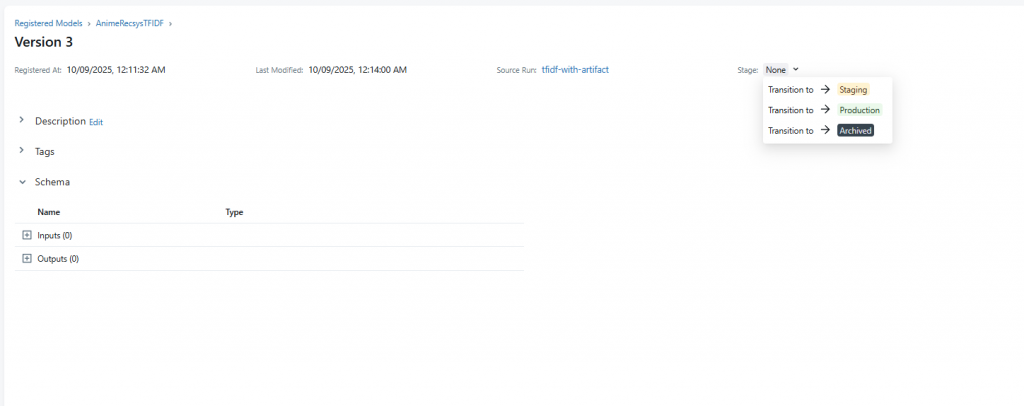
現在要手動在 UI 或用 client.transition_model_version_stage 把 TFIDF 設為 Staging
切換成Staging之後,接續後面動作。
📂 檔案:src/api/main.py
新增 /recommend_ab 端點與時間分流邏輯。
import mlflow
import mlflow.pyfunc
from fastapi import FastAPI, HTTPException, Query
from pydantic import BaseModel, ValidationError
import pandas as pd
import os
import csv
from datetime import datetime
app = FastAPI(
title="Anime Recommender API",
description="FastAPI + MLflow 企業級推薦系統",
version="2.3.0"
)
# === Health Check ===
@app.get("/health")
def health_check():
return {"status": "ok", "message": "FastAPI is running 🚀"}
# === 輸入格式定義 ===
class RecommendRequest(BaseModel):
user_id: str
anime_titles: list[str]
class ABEvent(BaseModel):
user_id: str
model_name: str
model_version: int
recommended_title: str
clicked: bool
timestamp: datetime = datetime.utcnow()
# === 設定 MLflow ===
mlflow.set_tracking_uri("http://mlflow:5000")
model_cache = {} # 模型快取,避免重複載入
def get_model(model_name: str):
"""依照模型名稱載入模型,若不存在則回傳 404"""
if model_name not in model_cache:
model_uri = f"models:/{model_name}/Staging"
print(f"📦 Loading {model_uri} ...")
try:
model_cache[model_name] = mlflow.pyfunc.load_model(model_uri)
except Exception:
raise HTTPException(status_code=404, detail=f"Model '{model_name}' not found in Registry.")
return model_cache[model_name]
# === 推薦 API ===
@app.post("/recommend")
def recommend(request: RecommendRequest, model_name: str = Query("AnimeRecsysModel")):
try:
if not request.anime_titles:
raise HTTPException(status_code=400, detail="anime_titles cannot be empty.")
model = get_model(model_name)
df = pd.DataFrame(request.anime_titles)
result = model.predict(df)
return {
"model_name": model_name,
"input": request.anime_titles,
"recommendations": result[0]
}
except ValidationError as ve:
raise HTTPException(status_code=422, detail=ve.errors())
except HTTPException as he:
raise he
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal Error: {str(e)}")
# === 時間分流邏輯 ===
def choose_model_by_time():
"""偶數秒 → baseline;奇數秒 → TF-IDF"""
sec = datetime.utcnow().second
return "AnimeRecsysModel" if sec % 2 == 0 else "AnimeRecsysTFIDF"
# === A/B 測試端點 ===
@app.post("/recommend_ab")
def recommend_ab(request: RecommendRequest):
"""根據時間自動分流"""
if not request.anime_titles:
raise HTTPException(status_code=400, detail="anime_titles cannot be empty.")
model_name = choose_model_by_time()
model = get_model(model_name)
result = model.predict(pd.DataFrame(request.anime_titles))
print(f"🧠 User={request.user_id} 使用模型: {model_name}")
return {
"endpoint": "/recommend_ab",
"user_id": request.user_id,
"model_name": model_name,
"recommendations": result[0],
"timestamp": datetime.utcnow().isoformat()
}
# === AB Test 紀錄 API ===
@app.post("/log-ab-event")
def log_ab_event(event: ABEvent):
LOG_DIR = "/usr/mlflow/workspace/logs"
os.makedirs(LOG_DIR, exist_ok=True)
log_path = os.path.join(LOG_DIR, "ab_events.csv")
try:
file_exists = os.path.isfile(log_path)
with open(log_path, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
if not file_exists:
writer.writerow(["timestamp", "user_id", "model_name", "model_version", "recommended_title", "clicked"])
writer.writerow([
event.timestamp.isoformat(),
event.user_id,
event.model_name,
event.model_version,
event.recommended_title,
event.clicked
])
return {"message": "Event logged successfully ✅", "event": event.dict()}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Failed to write log: {e}")
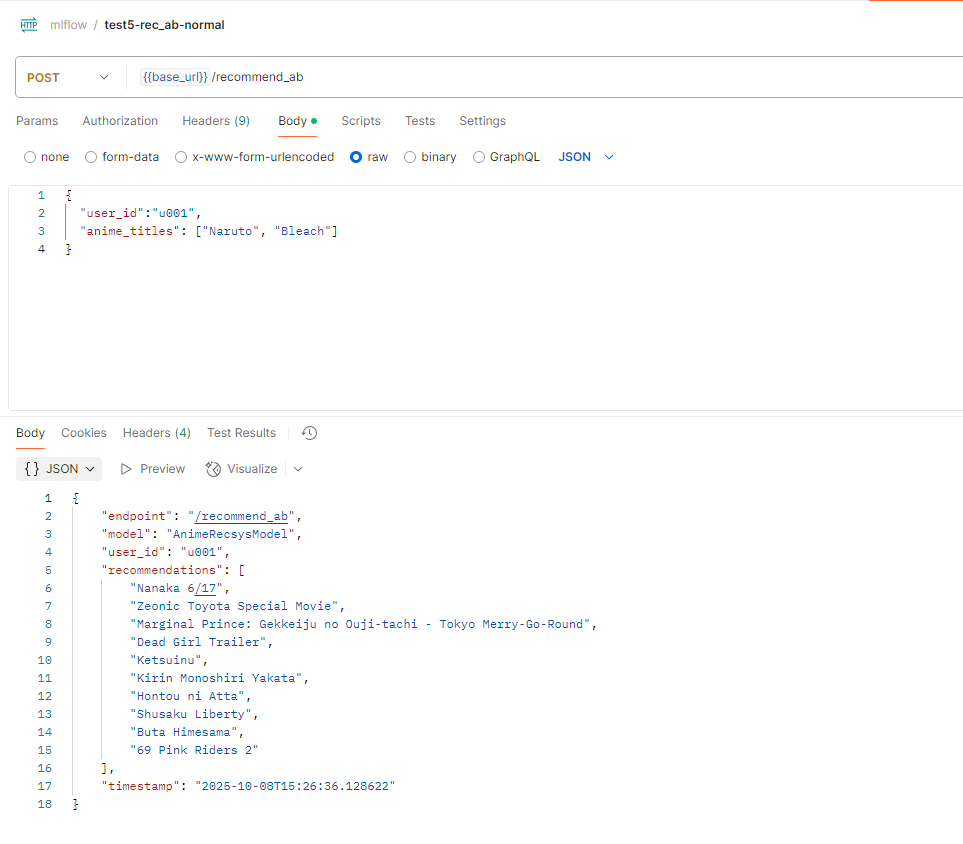
用 Postman 測試 /recommend_ab:
URL: http://127.0.0.1:8000/recommend_ab
Body:
{
"user_id": "user_001",
"anime_titles": ["Naruto"]
}
結果會隨秒數切換:
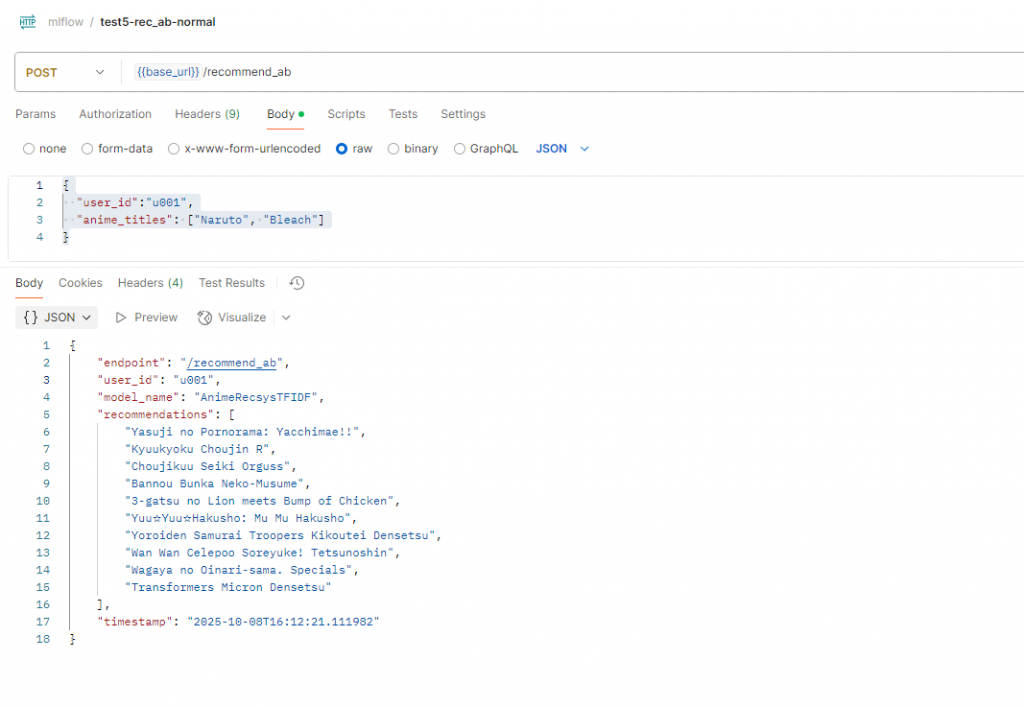
| 項目 | 說明 |
|---|---|
| Notebook | day25_register_tfidf.ipynb 註冊 AnimeRecsysTFIDF |
| FastAPI | 新增 /recommend_ab 以時間戳進行分流 |
| 測試結果 | 兩模型皆可呼叫並回傳推薦清單 |
| 下一步 | 後續將整合 Streamlit 前端展示 A/B 模型結果 |
明天我們將:

