我們這 30 天學過:
那今天,我們要把這些都整合起來!
做出一個可以「用說的、看圖、回話」的 AI 小幫手!
from openai import OpenAI
from fastapi import FastAPI, Form
from fastapi.responses import FileResponse
import base64
client = OpenAI(api_key="YOUR OPENAI KEY")
app = FastAPI()
@app.post("/ask")
async def ask_ai(prompt: str = Form(...), mode: str = Form("chat")):
"""
mode 可以是:
- chat:對話回覆
- image:生成圖片
- voice:生成語音回覆
"""
if mode == "chat":
# Chat 模式
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
)
answer = resp.choices[0].message.content
return {"mode": "chat", "response": answer}
elif mode == "image":
# 圖片生成模式
result = client.images.generate(
model="gpt-image-1",
prompt=prompt,
size="1024x1024"
)
image_base64 = result.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
output_path = "ai_output.png"
with open(output_path, "wb") as f:
f.write(image_bytes)
return FileResponse(output_path, filename="ai_output.png")
elif mode == "voice":
# 語音生成(TTS)
tts = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="alloy",
input=prompt
)
output_path = "ai_voice.mp3"
tts.stream_to_file(output_path)
return FileResponse(output_path, filename="ai_voice.mp3")
else:
return {"error": "無效的 mode 參數,請用 chat / image / voice"}
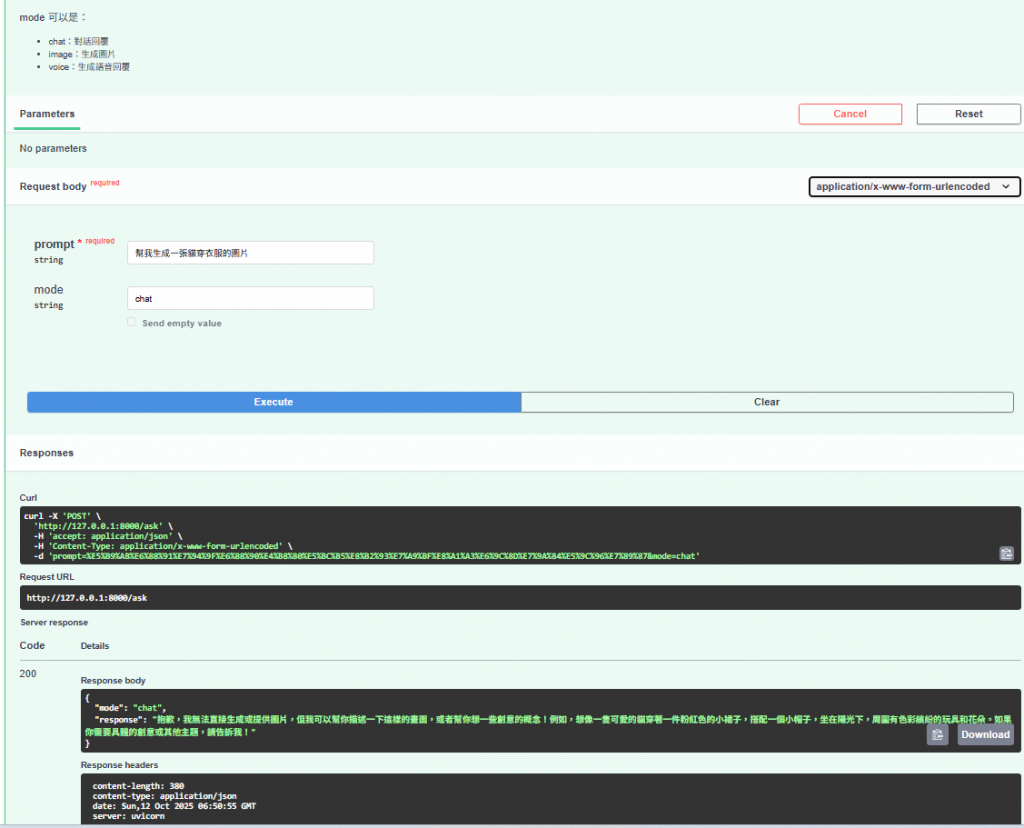

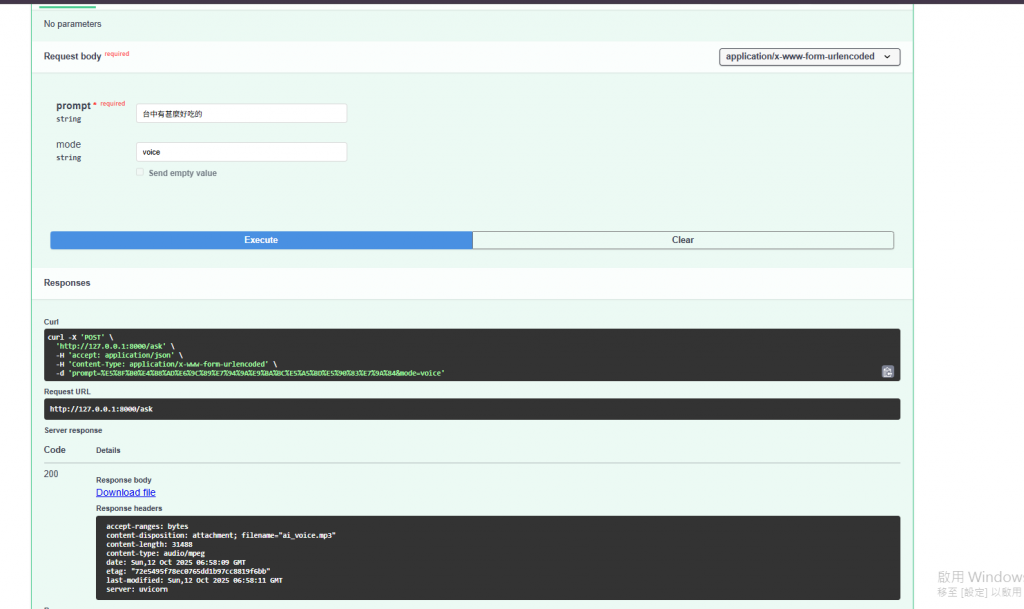
今天我們把過去 20 多天學的技能串起來,打造了一個可以「看圖、講話、畫圖」的 AI 小幫手。
它雖然只是幾十行程式,但已經能回文字、能生成圖像、也能講出聲音
你做的,不只是範例程式,而是你第一個真正能用的「AI 助理原型」!


 iThome鐵人賽
iThome鐵人賽