💡 這不是理論,是一個真實的晚上 10 點故障處理全記錄。
上週四晚上 22:15,我正準備睡覺,手機開始震動。
Teams 訊息:
🔥 CRITICAL: API Gateway 5xx rate > 5%
🔥 CRITICAL: Response time > 3s
🔥 CRITICAL: User service health check degraded
⚠️ INFO: Multiple endpoints showing timeouts
又來了。
看到 "API Gateway 5xx + timeout"
第一反應是:「是誰在搞!🔥」
然後開始推測:
但光看告警訊息,無法直接判斷。
需要開電腦 查 logs 才知道。
要確認這些細節:
這些需要:
以前:逐一登入系統手動查(30-40 分鐘)
現在:我決定試試 AI 協作...
整個對話記錄是這樣:
我:
「收到 API Gateway 5xx 錯誤告警(提供截圖)
幫我調查這個問題」
Claude:
「我透過 OpenSearch MCP 查詢到:
關鍵發現:
所有錯誤的 response 都包含 "upstream request timeout"
這表示不是 API Gateway 的問題
而是後端的 User Service 回應太慢
要我追蹤到 User Service 的 logs 嗎?」
我心裡想:
不到 1 分鐘,就查完所有 logs 並分析出關鍵資訊。
以前光是寫 Query DSL 就要 5 分鐘。
我:
「對,幫我追蹤看看」
Claude:
「我用 correlation-id 追蹤到 User Service 的 logs:
找到問題了!
User Service 有大量錯誤:
同時發現關鍵 metrics:
完整的故障鏈:
這是典型的 slow query 導致 connection pool 用盡。
要我查這種問題以前怎麼處理的嗎?」
我心裡想:
如果是手動追蹤,光是複製 correlation-id、切換系統、查詢,就要 15 分鐘。
AI 不到 1 分鐘就完成,還直接給我完整的故障鏈分析。
我:
「查一下歷史案例」
Claude:
「從 Jira 找到 2 個類似案例:
PROJ-5678 (2 個月前)
PROJ-4123 (4 個月前)
從 error pattern 來看:
這次比較像 PROJ-5678(slow query 問題)
要我整理當時的處理步驟嗎?」
我心裡想:
PROJ-5678 那次我還記得。
但如果沒有 AI 提醒,我可能要翻找 10 分鐘才想起來。
我:
「給我處理建議」
Claude:
「根據 PROJ-5678 的處理經驗,當時的做法是:
SRE 的處理步驟:
保留現場
先評估,並恢復服務
通知團隊
後續由 DBA + RD 處理:
建議執行:
kubectl rollout restart deployment/user-service -n production
要我產生完整的執行步驟嗎?」
我心裡想:
這些步驟跟 PROJ-5678 當時處理的一樣。
但如果沒有 AI 提醒,我可能要翻找好久才想起來。
我:
「產生完整步驟」
Claude:
「執行步驟如下:
# Step 1: 緊急重啟(恢復服務)
kubectl rollout restart deployment/user-service -n production
# Step 2: 監控狀態
kubectl rollout status deployment/user-service -n production
# Step 3: 確認恢復
watch -n 2 'kubectl get pods -n production | grep user-service'
# Step 4: 觀察 metrics
觀察以下指標:
- 5xx rate 應該下降到 < 1%
- Response time 應該恢復到 < 500ms
- Connection pool usage 應該降到 < 60%
# Step 5: 後續追蹤
- 聯絡 DBA 分析 slow query
- 準備加 index 或優化 query
執行完成後告訴我結果。」
我執行指令。
服務在 3 分鐘內恢復。
我:
「服務已恢復,幫我產生 Incident Report」
Claude:
「Incident Report 初稿如下:
# Incident Report: API Gateway 504 Timeout
## Summary
- 發生時間: 2025-01-XX 22:05 - 22:30
- 影響範圍: User Service APIs
- 嚴重程度: High
- 調查時間: 15 分鐘
- 恢復時間: 5 分鐘
## Timeline
22:05 - 開始出現 504 timeout
22:10 - 錯誤率逐漸上升
22:15 - 告警觸發
22:17 - 開始調查
22:21 - 找到根因(slow query + connection pool 滿)
22:24 - 查詢歷史案例
22:28 - 執行重啟
22:30 - 服務恢復
## Root Cause
表面症狀: API Gateway 回傳 504 Gateway Timeout
實際根因: Database slow queries 導致 connection pool 用盡
故障鏈:
1. Database 有 slow queries(> 5s)
2. Slow queries 長時間佔用 connection
3. Connection pool 逐漸被佔滿(95% usage)
4. 新請求拿不到 connection → connection wait timeout
5. User Service 無法處理請求
6. API Gateway 等不到回應 → 504
## Investigation Method
1. 查詢 API Gateway logs → 發現 upstream timeout
2. 用 correlation-id 追蹤 → 找到 User Service logs
3. 發現 "Failed to acquire connection" + connection pool 滿
4. 查詢 Jira 歷史 → 找到類似 slow query 案例
5. 從歷史案例學習處理方式
## Resolution
緊急處理(SRE):
- 重啟 User Service 釋放 connection pool
- 服務立即恢復
- 保留現場資料(metrics 截圖、logs)
後續改善(DBA + RD):
- [ ] DBA 分析並優化 slow queries
- [ ] 考慮加 index
- [ ] RD 優化 application 層查詢邏輯
- [ ] SRE 增加 slow query 監控告警
## Lessons Learned
- ✅ Correlation-id 追蹤快速定位根因
- ✅ Connection pool monitoring 很重要
- ⚠️ 需要加強 slow query 預警機制
完成!」
我看了一下報告。
時間軸、根因、處理步驟,全部都有。
我只需要補充一些細節就好。
整個調查過程:15 分鐘
寫報告:5 分鐘
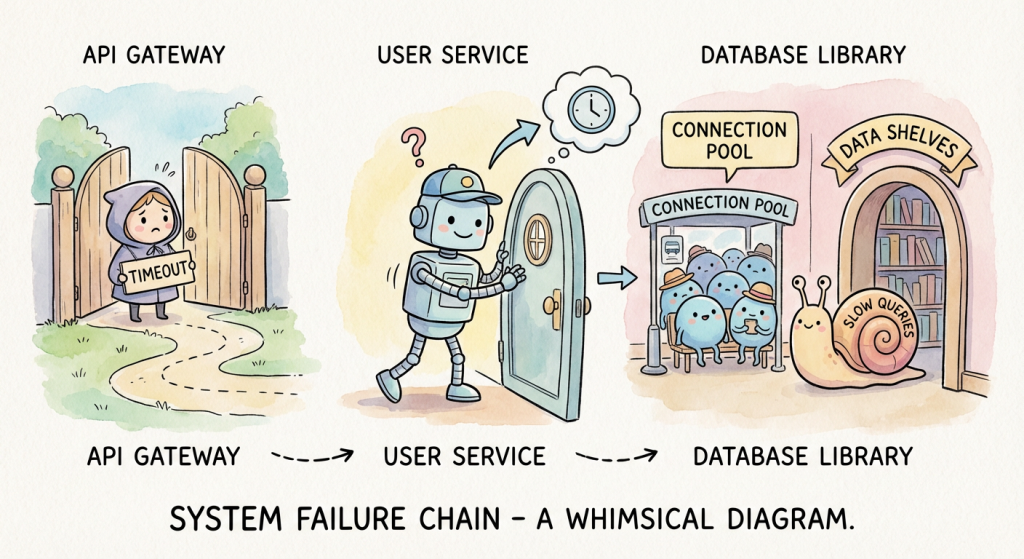
這次的故障傳遞路徑:
這就是為什麼需要 correlation-id 追蹤。
錯誤在 API Gateway,但根因在 Database。
以前:手動複製 correlation-id、切換系統、查詢(15 分鐘)
現在:告訴 AI「追蹤到後端」,自動完成(< 1 分鐘)
錯誤在 API Gateway,根因在 Database。
AI 自動串聯整個故障鏈。
以前:去 Jira 搜尋、逐一閱讀、回想細節(20-25 分鐘)
現在:AI 找出類似案例 + 整理處理步驟(< 2 分鐘)
我可能會忘記 PROJ-5678。
但 AI 不會。
以前:回想過程、整理時間軸、寫 Root Cause(30 分鐘)
現在:AI 根據對話自動產生(5 分鐘)
省下 70 分鐘的「查詢」和「整理」時間。
你可能會問:「這技術上怎麼做的?」
核心是:Claude + MCP (Model Context Protocol)
(第一篇已經介紹過 MCP 的概念了)
這個案例用到的 MCP:
重點是:
你不需要寫代碼整合這些系統。
只要安裝好 MCP Server,就能用自然語言查詢。
(詳細的設定方式,第三、四篇會手把手教你)
這個案例也展現了 SRE 的真實工作:
不是一個人解決所有問題
而是「快速找到根因 + 協調團隊」
這次的分工:
SRE(我):
DBA:
RD:
AI 協作讓我能:
整個 Incident 處理更順暢。
處理完這次 Incident,我有幾個體會:
以前知道要追蹤,但常常懶得做(太麻煩)。
現在有 AI 幫忙,變得很簡單。
我開始養成習慣:每次都追蹤到底。
這次如果沒找到 PROJ-5678,可能要多花很多時間。
知識重用的價值,比我想像的大。
這也讓我更願意寫 Post-Mortem。
AI 能幫我查資料。
但「決定要重啟還是等 DBA」是我的判斷。
SRE 的核心能力是「判斷」,不是「記住所有指令」。
從收到告警到寫完報告,整整 15 分鐘。
關鍵是:AI 幫你處理「重複性查詢」,你專注在「判斷」和「決策」。
第三篇:OpenSearch MCP 設定
手把手教你如何安裝、設定、查詢 logs
第四篇:Atlassian MCP 設定
一次設定 Jira + Confluence,重用歷史經驗
看完就能實作。
如果你對這個案例有問題,或想分享你的 Incident 處理經驗,歡迎留言交流!
本文是「SRE × AI 實戰系列」的第 2 篇,共計 10 篇。
 打雜的花園鰻
打雜的花園鰻

 iThome鐵人賽
iThome鐵人賽