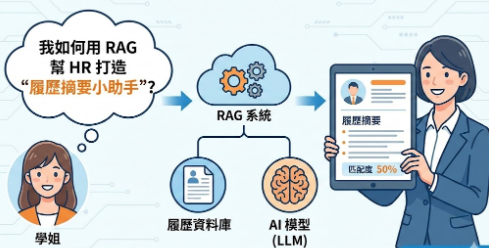
最近在醫院辦公室,聽到人資單位的學姐在感嘆:
「如果 AI 這麼厲害,能不能幫我們看履歷啊?每天點開幾十份 PDF,光是看,眼力真的很吃緊。」
這句話給了我靈感。身為軟體開發者,我們常在追求強大的模型或複雜的架構,但對於非技術端的同事來說,需求其實很簡單:「能不能在我問問題時,AI 幫我從那堆 PDF 裡找到正確答案?」
這就是 RAG (Retrieval-Augmented Generation) 發揮價值的完美場景。今天我想嘗試利用 LangChain (LCEL) 與 Local LLM,快速搭建一個小工具。
在開發這個 Demo 時,我設定了幾個核心目標:
all-MiniLM-L6-v2 Embedding 模型,在一般辦公電腦上就能流暢運行。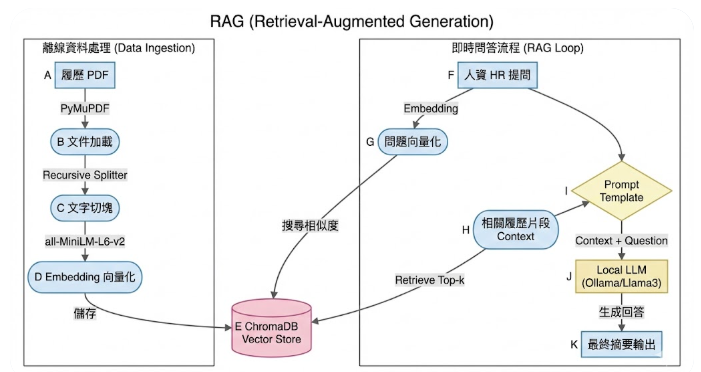
RAG 的核心邏輯非常直觀:「讀取資料 -> 切片 -> 向量化 -> 檢索 -> 生成」。
我們利用 PyMuPDFLoader 讀取 PDF 內容,並透過 Chroma 建立向量資料庫。這就像是幫 HR 的履歷表建立了一套「超級索引」。
# Embedding & Vector DB 建立
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# 初始化 Embedding 模型
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 將讀取到的文件存入向量資料庫
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever()
這是我最喜歡的部分。LCEL 讓開發者可以用 | 符號像 Pipeline 一樣串接流程。我定義了一個「專業人資專員」的 Prompt,確保 AI 的回答精準且專業:
「你是一個專業的人資專員。請根據 context 回答問題,不要瞎掰。」
# 定義處理鏈 (LCEL 語法)
# (檢索資料) -> (放入 Prompt) -> (丟給 LLM) -> (轉成字串)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
當我輸入:「這份履歷的主角有哪些技術專長?」時,AI 會迅速從 PDF 中抓取出關鍵字並以條列式呈現。對於 HR 同事來說,這意味著:
pdf檔案記得要放再跟程式同個路徑
linux指令:
#記得在電腦終端機 先安裝ollama 並且拉llama3 模組下來
sudo snap install ollama
ollama pull llama3
Python:
# rag_demo.py (LCEL 版本 - 更穩定、更現代)
import sys
import os
# 1. 確保載入正確的模組
try:
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_ollama import OllamaLLM
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
except ImportError as e:
print("環境錯誤!請確認您是使用 'poetry run python rag_demo.py' 執行。")
print(f"詳細錯誤: {e}")
sys.exit(1)
# --- 1. Data Pipeline ---
print("正在讀取 PDF 並建立向量資料庫...")
# 請確保您的資料夾下有一個 manual.pdf,或者換成您有的任何 pdf 檔名
if len(sys.argv) > 1:
pdf_path = sys.argv[1]
else:
pdf_path = "zhi.pdf" # 預設檔名
if not os.path.exists(pdf_path):
print(f"找不到檔案: {pdf_path}")
print("請放入一個 PDF 檔案,或是將檔名改成 manual.pdf")
# 為了測試,這裡我們建立一個假的文字資料,以免您因為沒 PDF 卡關
from langchain_core.documents import Document
print("--> 找不到 PDF,切換為【測試模式】,使用假資料...")
documents = [
Document(
page_content="科技業 PM 轉身成為數位行銷人,熱衷學習的業餘插畫家 & 程式設計師。"
),
Document(page_content="在研究所畢業後原任職於科技業,從事產品管理的工作。"),
Document(page_content="自己對於數位行銷領域的熱情,因此在任職一年後毅然轉職到數位行銷公司。"),
]
else:
loader = PyMuPDFLoader(pdf_path)
documents = loader.load_and_split()
# Embedding & Vector DB
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever()
print("資料庫就緒!")
# --- 2. RAG Setup (使用 LCEL 語法) ---
# LCEL 是 LangChain 的新標準,使用 | 符號串接,不依賴舊的 chains 模組
llm = OllamaLLM(model="llama3")
# 定義 Prompt 模板
template = """你是一個專業的人資專員。請根據以下的 context (上下文) 回答使用者的問題。
如果 context 裡沒有答案,請直接說不知道,不要瞎掰。
Context:
{context}
Question:
{question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 定義處理鏈: (檢索資料) -> (放入 Prompt) -> (丟給 LLM) -> (轉成字串)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# --- 3. 互動迴圈 ---
while True:
query = input("\n請輸入問題 (輸入 'q' 離開): ")
if query.lower() == "q":
break
print("AI 思考中...")
# 執行 RAG
result = rag_chain.invoke(query)
print(f"\n[AI 回答]: {result}")
這套 RAG 框架不僅能用在履歷,未來也能應用在醫院內部的 SOP 規範 或 合約摘要 中。如果你也對 AI 落地應用感興趣,歡迎追蹤我的筆記。
 howardnote945
howardnote945

 iThome鐵人賽
iThome鐵人賽