你丟了一句「你好 Hello」給 GPT-5——7 個字元。但模型實際處理的是 2 個 Token,而你的帳單也是按 Token 收費的。
與此同時,你的電腦把這句話存成 12 個位元組(Byte)。
等等,所以位元組、字元、單詞和 Token 到底差在哪?為什麼 AI 不直接讀位元組?為什麼同樣一句話,中文比英文更貴?
這篇文章會從最底層開始,一步步帶你搞懂:從硬碟上的位元組,到 AI 實際在處理的 Token,整條路到底發生了什麼事。
位元組(Byte) 是電腦儲存資料的最小單位。1 個位元組 = 8 個位元(bit)= 一個 0 到 255 之間的數字。
當你把文字存檔的時候,電腦會依照 UTF-8 編碼標準,把每個字元轉換成位元組:
| 字元 | UTF-8 位元組 | 位元組數 | 十六進位 |
|---|---|---|---|
H |
72 | 1 | 48 |
e |
101 | 1 | 65 |
你 |
228, 189, 160 | 3 | e4 bd a0 |
好 |
229, 165, 189 | 3 | e5 a5 bd |
🚀 |
240, 159, 154, 128 | 4 | f0 9f 9a 80 |
規律很清楚:
所以「你好 Hello」存起來就是 12 個位元組:
你 好 空格 H e l l o
e4 bd a0 e5 a5 bd 20 48 65 6c 6c 6f
(3 Bytes)(3 Bytes)(1) (1) (1) (1) (1) (1) = 12 Bytes
位元組是電腦儲存文字的方式。但 AI 模型並不會直接讀位元組喔。
同一段文字,其實有四種不同粒度的拆法:
英文範例:"Hello, World"
| 層級 | 拆分結果 | 數量 | 說明 |
|---|---|---|---|
| Byte | 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 |
12 | 原始儲存單位 |
| 字元 | H e l l o , ␣ W o r l d |
12 | 人類看得懂的字母 |
| 單詞 | Hello, World |
2 | 用空格切 |
| Token | Hello , World |
3 | AI 實際處理的單位 |
中文範例:「你好世界」
| 層級 | 拆分結果 | 數量 | 說明 |
|---|---|---|---|
| Byte | e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c |
12 | 每個漢字 3 Bytes |
| 字元 | 你 好 世 界 |
4 | 一個字就是一個字元 |
| 單詞 | 你好 世界 |
2 | 依語意切詞 |
| Token | 你好 世界 |
2 | 取決於 tokenizer |
核心重點:Token 不是位元組,不是字元,也不是單詞。 它是一種介於字元和單詞之間的「子詞」單位,是效率和覆蓋率的最佳平衡點。
既然位元組和單詞比較簡單直覺,為什麼 AI 偏偏要搞出 Token 這個東西?因為兩個極端都有嚴重的問題。
「Hello」是 5 個位元組,一篇 1000 字的文章大約 5000 個位元組,一本小說就是 50 萬個位元組。
AI 模型需要計算序列中每個位置之間的關係(就是大家常聽到的 Attention 注意力機制),計算量隨序列長度呈平方成長(O(n²))。序列長度變 2 倍 → 計算量變 4 倍。
如果直接用位元組,序列會比 Token 長 3~4 倍,AI 跑起來的成本會貴到爆。
光是英語常用詞就超過 17 萬個,再加上技術名詞、人名、URL、程式碼和其他語言的詞彙,詞彙表可能膨脹到數百萬。
超大的詞彙表代表:
Token 把文字拆分成子詞單元(subword units)——比位元組大,比單詞小:
"unbelievable" → ["un", "bel", "ievable"] (3 個 Token)
"tokenization" → ["Token", "ization"] (2 個 Token)
"Hello" → ["Hello"] (1 個 Token —— 夠常見,保留完整)
"你好" → ["你好"] (1 個 Token —— 高頻詞組合在一起)
這樣既能保證短序列(處理效率高),又能維持小詞彙表(大約 10~20 萬條就夠),而且不會碰到未知詞(任何文字都能拆成已知的子詞片段)。
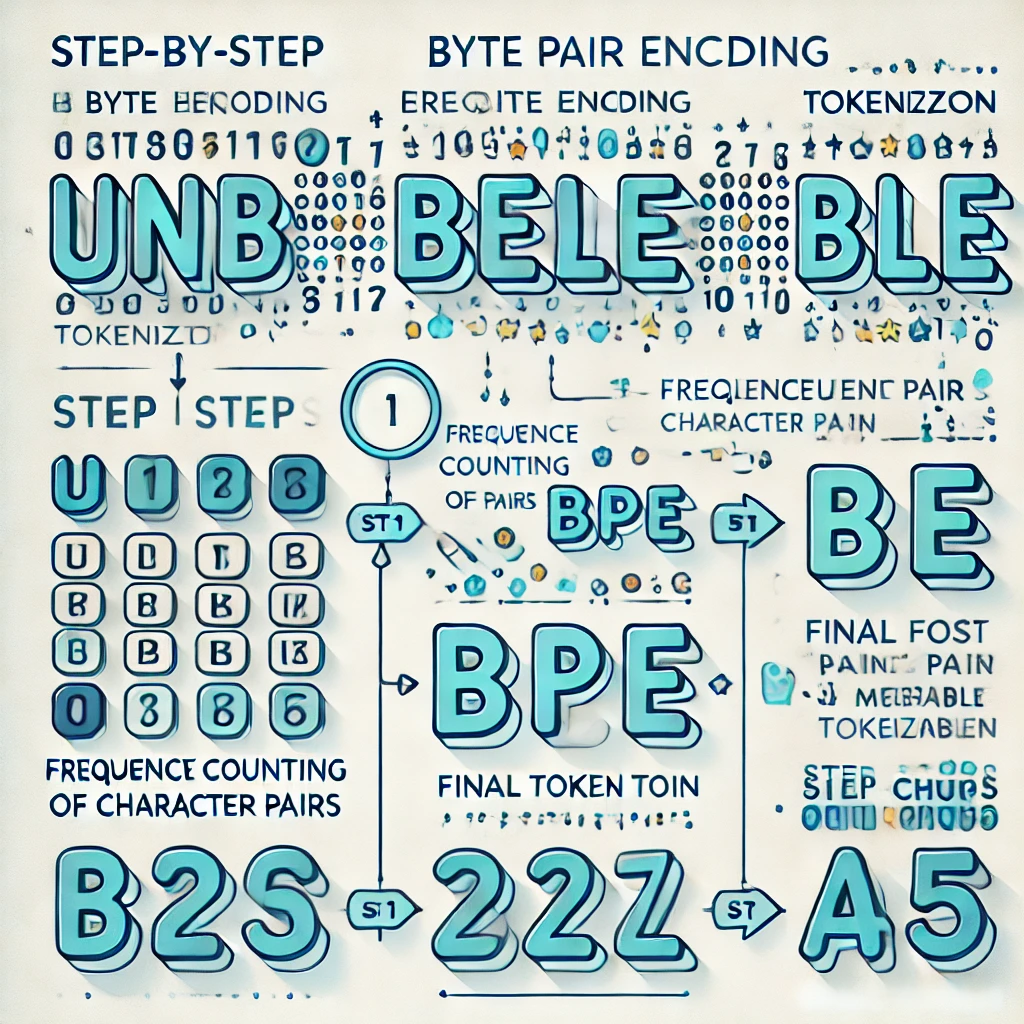
幾乎所有主流大模型都用 BPE(Byte Pair Encoding,字節對編碼) 演算法來建立 tokenizer。原理其實沒有想像中複雜:
把訓練語料中的所有文字拆成最小單位:
"low" → ["l", "o", "w"]
"lower" → ["l", "o", "w", "e", "r"]
"newest" → ["n", "e", "w", "e", "s", "t"]
掃描所有相鄰字元對,找出出現次數最多的:
("l", "o") 出現 2 次 ← 最高頻!
("o", "w") 出現 2 次
("e", "w") 出現 1 次
...
把所有 ("l", "o") 替換為新的 Token "lo":
"low" → ["lo", "w"]
"lower" → ["lo", "w", "e", "r"]
不斷統計、合併,直到詞彙表達到目標大小(通常 5~20 萬)。
經過大量合併後,「the」、「Hello」、「你好」這些高頻詞會變成單一的 Token,而罕見詞則會被拆成多個子詞片段。
你可以用 OpenAI 的 tiktoken 套件來看 GPT-5 實際的分詞結果:
import tiktoken
# o200k_base 是 GPT-4o / GPT-5 使用的 tokenizer
enc = tiktoken.get_encoding("o200k_base")
text = "你好 Hello"
tokens = enc.encode(text)
token_strings = [enc.decode([t]) for t in tokens]
print(f"原文: {text}")
print(f"UTF-8 位元組數: {len(text.encode('utf-8'))}")
print(f"Token 數 ({len(tokens)}): {token_strings}")
print(f"Token ID: {tokens}")
原文: 你好 Hello
UTF-8 位元組數: 12
Token 數 (2): ['你好', ' Hello']
Token ID: [177519, 32949]
12 個位元組壓縮成了 2 個 Token!這就是 BPE 的威力——高頻詞組會被合併成單一 Token,大幅縮短序列長度。
每個 AI 模型家族都有自己的 tokenizer 和詞彙表。同一段文字在不同模型上的 Token 數可能不同:
| 文字 | cl100k_base (GPT-4) | o200k_base (GPT-4o/5) | UTF-8 Bytes |
|---|---|---|---|
| Hello, how are you today? | 7 | 7 | 25 |
| Explain quantum computing | 7 | 6 | 41 |
| 你好,請用中文解釋一下什麼是token | 15 | 9 | 47 |
| こんにちは、トークンとは何ですか? | 12 | 10 | 51 |
| Python fibonacci 函式(5行) | 28 | 28 | 92 |
關鍵發現:GPT-5 的 tokenizer(o200k_base)對中文和日文的效率有顯著提升 🎉——同一句中文,GPT-4 要 15 個 Token,GPT-5 只需要 9 個,省了 40%。
Claude 用的是自家研發的 tokenizer,Gemini 則用 SentencePiece。不同模型處理同一段文字的 Token 數不一樣,這代表同樣的 prompt 在不同模型上花的錢也不同。
AI API 是按 Token 計費的,不是按位元組也不是按字數。而且不同語言的 Token 效率差異很大:
| 語言 | 文字 | Token 數 | Bytes 數 | Bytes/Token |
|---|---|---|---|---|
| 英文 | "Hello, how are you today?" | 7 | 25 | 3.6 |
| 中文 | "你好,今天怎麼樣?" | 5 | 27 | 5.4 |
| 日文 | "こんにちは" | 1 | 15 | 15.0 |
| 韓文 | "안녕하세요" | 2 | 15 | 7.5 |
| 程式碼 | def fibonacci(n): (5行) |
28 | 92 | 3.3 |
在 GPT-5 的 tokenizer 下,日文其實是 Token 效率最高的語言——「こんにちは」把 15 個位元組壓縮成了 1 個 Token,超猛。
假設你用 GPT-5(輸入 $1.25/百萬 Token)處理 100 萬字元的文字:
| 語言 | 約 Token 數 | 費用 |
|---|---|---|
| 英文 | ~33 萬 | $0.41 |
| 中文 | ~50 萬 | $0.63 |
| 中英混合 | ~40 萬 | $0.50 |
中文文字比英文貴大約 50%——因為平均每個漢字消耗的 Token 比較多。
不同模型有不同的 tokenizer、不同的價格、不同的能力。最划算的選擇可能跟你想的不一樣。
用統一的 API 閘道(Gateway),你可以用同一把 Key 測試多個模型,同時比較品質和成本:
from openai import OpenAI
client = OpenAI(
api_key="your-crazyrouter-key",
base_url="https://crazyrouter.com/v1"
)
# 同一個 prompt 測試多個模型
for model in ["gpt-5", "gpt-5-mini", "deepseek-v3.2", "claude-sonnet-4"]:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "用兩句話解釋什麼是 tokenization"}],
max_tokens=100
)
usage = response.usage
print(f"{model}: {usage.prompt_tokens} 輸入 / {usage.completion_tokens} 輸出")
透過 Crazyrouter 一把 API Key 就能呼叫 627+ 模型,輕鬆找到最適合你的語言和使用場景的高 CP 值模型。
2024 年底,Meta 發表了 BLT(Byte Latent Transformer)——一種直接處理原始位元組的模型架構,完全跳過了 tokenizer。
現實狀況:Token 至少還會稱霸 3~5 年。搞懂它的運作原理,是每個 AI 開發者的必備技能。
| 屬性 | Byte | 字元 | 單詞 | Token |
|---|---|---|---|---|
| 是什麼 | 儲存最小單位 | 人類可讀符號 | 按空格/語意分割 | AI 處理的子詞單位 |
| 大小 | 固定 1 Byte | 1-4 Bytes (UTF-8) | 不固定 | 不固定 |
| "Hello" | 5 | 5 | 1 | 1 |
| "你好" | 6 | 2 | 1 | 1 |
| "unbelievable" | 12 | 12 | 1 | 3 |
| 用在哪 | 電腦儲存 | 人類閱讀 | 搜尋引擎 | AI 模型 |
| API 計費? | 否 | 否 | 否 | 是 |
不是喔。Byte 是電腦的原始儲存單位(1 Byte = 8 bits),Token 是 AI 模型處理的最小文字單位。「Hello」是 5 個 Bytes 但只有 1 個 Token;「你好」是 6 個 Bytes 也只有 1 個 Token。Byte 和 Token 之間的對應關係取決於語言和具體的 tokenizer。
效率問題。「Hello」用 Byte 表示是長度 5 的序列,用 Token 表示只有長度 1。一篇千字文章的 Byte 級序列會長 3~4 倍。Transformer 的注意力機制計算量是 O(n²),序列越長成本爆得越兇。
不會。GPT-5 用 o200k_base tokenizer,GPT-4 用 cl100k_base,Claude 用自家的 tokenizer。同一句中文可能在 GPT-4 上是 15 個 Token,在 GPT-5 上只要 9 個。這代表同一個 prompt 在不同模型上的費用也會不同。
兩個原因:第一,中文字元在 UTF-8 裡每個佔 3 Bytes(英文只有 1 Byte);第二,就算用了最新的 tokenizer,中文字元的壓縮效率還是不如英文。同樣語意的一句話,中文通常比英文多消耗大約 50% 的 Token。
五個實戰技巧:
max_tokens 限制輸出長度搞懂 Byte 與 Token 的差別,是控制 AI 成本的第一步。更多開發者指南和最新模型定價資料,歡迎逛逛 Crazyrouter 部落格。
 xujfcn
xujfcn

 iThome鐵人賽
iThome鐵人賽