
這兩年,AI Agent 幾乎變成生成式 AI 世界裡最熱門的詞之一,但越熱門的詞,往往也越容易被混用,有些人說 Agent 是會呼叫工具的大模型,有些人說 Agent 是能自己規劃並執行多步驟任務的系統,還有些人甚至把各種自動化流程都叫做 Agent。當同一個詞開始承載太多不同意思時,第一件該做的事就不是急著追逐它,而是先把 Agent 的定義理解清楚。
AI Agent 之所以在這個時間點快速升溫,並不是因為 Agent 這個概念突然誕生,而是因為大語言模型讓它第一次變得足夠通用、足夠靈活,也足夠接近真實應用。當模型開始能理解目標、維持上下文、調用工具,甚至執行多步驟流程時,Agent 就不再只是 AI 教科書裡的古老概念,他開始變成可以被真正建構出來的系統。這股變化也不只是感覺而已,McKinsey 在 2025 年的調查顯示,23% 的受訪企業已在部分業務中擴大部署 agentic AI,另有 39% 已開始實驗 AI agents。
正因為 Agent 非常火熱,它才需要被重新理解,否則我們很容易還沒搞清楚它是什麼,就先把各種能力、想像與期待都投射上去。所以在談 Agent system 之前,這篇文章想先退一步:從最基本的問題開始,先弄清楚 Agent 到底是什麼、它怎麼運作、又是怎麼一路演化到今天的。
Agent 不是一個只負責回應輸入的模型,而是在目標約束下,能持續觀察環境、做出決策、採取行動,並根據結果調整自己的系統,它的關鍵不在於「說了什麼」,而在於能不能在迴圈裡把事情往前推。
這也是 Agent 和 Model 最本質的差別,Model 的核心能力是預測與生成;它可以很聰明,但它本身不等於一個會完成任務的系統,Agent 則是把模型放進一個更完整的運作框架裡:
有目標、有上下文、有工具、有記憶,也有讓它能反覆觀察、判斷、行動的控制迴圈。
換句話說,模型負責產生判斷,Agent 負責在迴圈中決策與行動, 它會在 loop 中持續運作,直到滿足結束條件。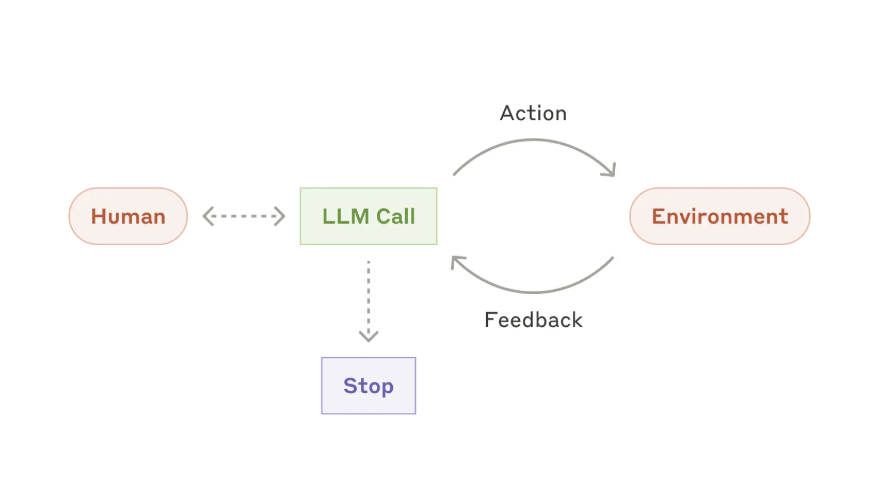
而 Agent 和 Workflow 也不一樣,Workflow 通常是人先把路徑設計好,系統照著既定步驟往下跑;Agent 則是在目標給定之後,由模型根據環境與回饋動態決定下一步。Workflow 是由預先定義的 code path 去編排 LLM 與工具,agent 則是由 LLM 動態主導自己的流程與工具使用, 因此不是所有多步驟、會調工具的東西,都算是 Agent。
Agent 的核心其實就是一個 loop,它不是先想完、再一次做完,而是在與環境互動的過程中,不斷接收資訊、做出判斷、採取行動,再根據結果修正下一步。你可以把它看作 ReAct 所提出的循環概念:reasoning → action → observation,所以 Agent 本身的核心迴圈如下: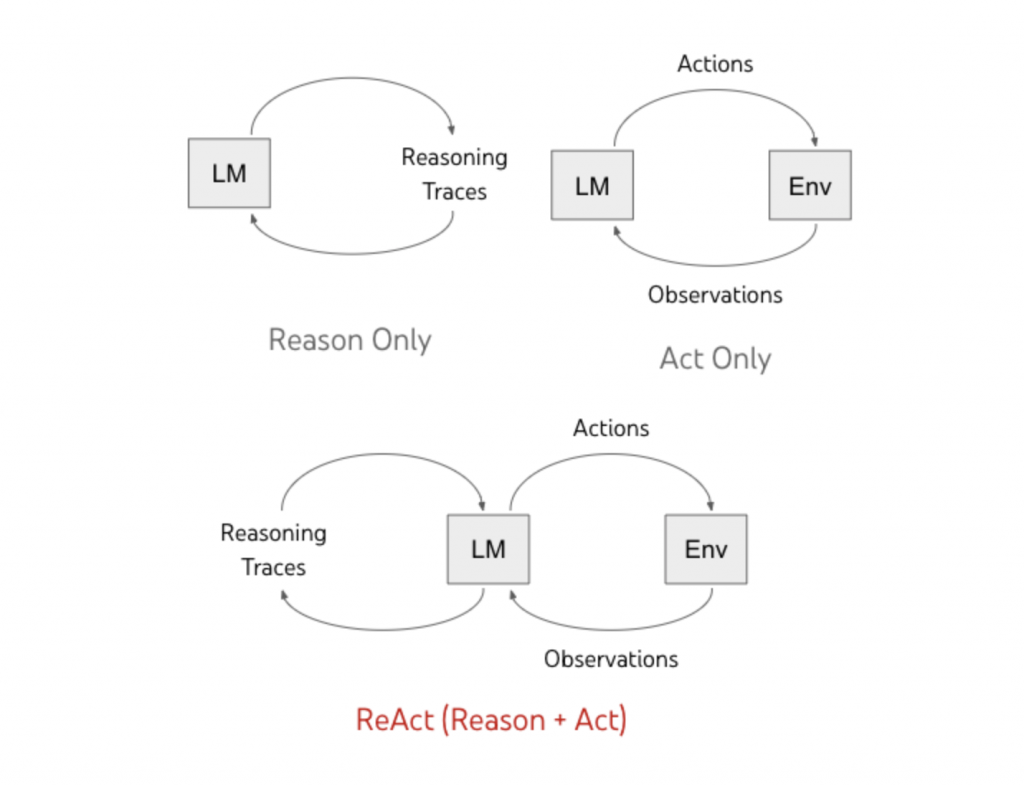
ReAct 很經典地把 Agent 與環境互動的循環顯性化,模型不是靜態地回答問題,而是在 reasoning、action 與 observation 之間反覆往返,若再往上抽象一層,我們可以把這個 agent loop 理解成四個更一般化的步驟:Sense、Plan、Act、Learn。
這個 loop 就是 Agent 和一般模型應用最本質的差別,模型負責產生輸出,Agent 則要在回饋中持續推進任務,理解這個骨架之後,後面談 Agent 的演化、類型與系統設計才會更好理解。
Agent 不是 LLM 時代才突然冒出來的概念,它一直都是 AI 裡很核心的一條路線。
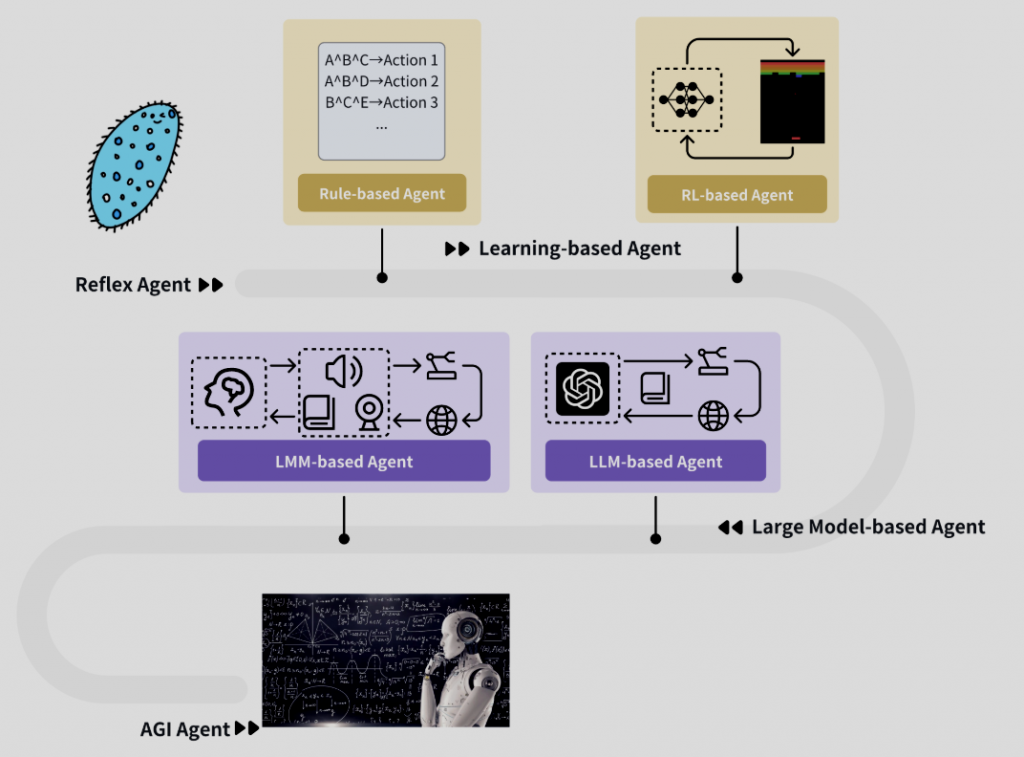
最早的 agent 很像 reflex 或 rule-based agent,它們接受到刺激,就會按照既定規則做出反應,這類系統在環境單純時很好用,但面對複雜情境時很快就會失去彈性。
再往後,agent 開始走向 learning-based,系統不再完全依賴手寫規則,而是從資料與回饋中調整行為,而 RL-based agent 則更進一步,透過獎勵與懲罰來學習策略。
到了今天,large model-based agents 讓這條路線重新爆紅,當 agent 以 LLM 為核心時,它不只會回應文字,還能規劃步驟、使用工具等,再往前一步,LMM-based agents 則把能力延伸到多模態資訊,至於 AGI agent,則更像是遠方的方向,就不是本文的重點了。
在 LLM 時代,大家都稱它 agent,但實際上,不同 agent 在任務範圍、存在時間、互動方式與所處環境上,可能差非常多。也就是說,理解 agent,不能只知道「它是不是 agent」,還要知道它是沿著哪些設計軸被做出來的?
有些 agent 是 ephemeral 的,任務完成就結束;有些則是 persistent 的,會保留狀態、記憶與長期目標,在多輪互動中持續運作。有些 agent 是 narrow-purpose 的,只專注在單一任務;有些則朝 general-purpose 發展,希望在不同任務之間保持通用性。前者通常更容易控制,後者則更靈活,但也更難設計。
agent 也可能是 disembodied 的,只在數位環境中讀取資訊、呼叫工具與操作軟體;也可能是 embodied 的,能接收真實世界的感測訊號,進一步影響實體環境。放到 LMM 與機器人結合的脈絡來看,這條界線會變得很重要。
如果再往下看,agent 還可以分成 single-agent 與 multi-agent。相關 survey 甚至會直接從這些差異去整理 LLM-based agents,例如 single-agent 與 multi-agent 在 memory、modality、toolsets 與應用場景上就有明顯不同。這些差別不是枝節,而是會直接影響 agent 的能力邊界與系統複雜度。
上一節談的是 agent 的設計空間,接著從實務角度來看,我們還可以再問另一個問題:不同 agent 通常是怎麼運作的?
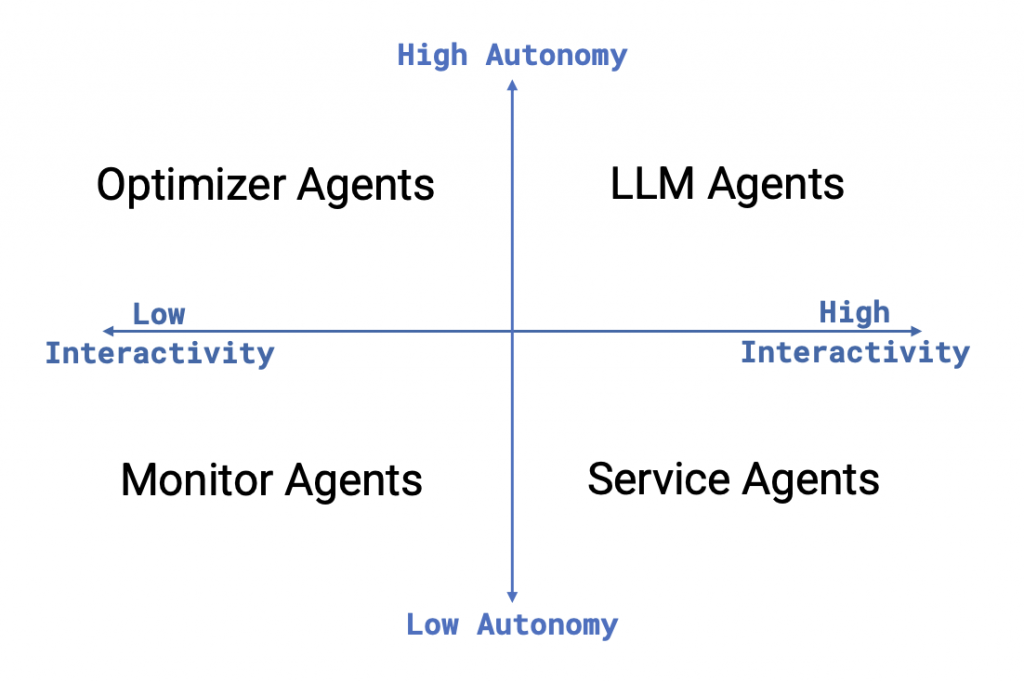
從此圖的兩條軸來看,一條是 interactivity,也就是它和人互動的頻率與強度;另一條是 autonomy,也就是它能否在少量指示下自行推進任務。沿著這兩條軸,我們可以把常見的 agent 粗略分成四種。
這不是什麼嚴格的學術分類,而是一種很實用的觀察方式,可以幫助我們把「agent 是什麼」再往前推一步,看到 agent 在真實應用裡到底會呈現出什麼樣子。理解這些運作型態之後,後面再談 agent 的能力邊界、幻覺與系統設計,會更容易抓到重點。
走到這裡,我們已經知道 agent 不是單純會回答問題的模型,而是一種能感知、規劃、行動並持續更新的系統,也正因為它看起來更像「在做事」、更像「在思考」,人們往往會不自覺地高估它。Agent 的危險,不只在於它可能犯錯,更在於它很容易讓人以為自己已經理解了更多、探索了更多、看得更客觀了,很多時候,這些感覺本身就是一種錯覺。
第一種錯覺,是把預測得準誤認成理解得深,當 AI 能夠做出高準確率的判斷、給出看起來合理的推理、甚至把答案一步一步講出來時,人很容易產生一種感覺:既然它表現這麼好,那它大概真的「懂了」。但事實上,會預測、會擬合、會產生看似連貫的解釋,不等於真的掌握了背後機制。這種錯覺在 agent 身上更強,因為 agent 不只是回答,還會規劃、會呼叫工具、會採取行動,因此人更容易把「行為上的流暢」誤認成「理解上的完整」。
第二種錯覺,是把探索得快誤認成探索得廣,Agent 的確可以比人類更快地試路徑、查資料、跑工具、展開多步驟流程,這會讓人產生另一種直覺:既然它做了這麼多事,應該已經把可能性都看過一輪了。但很多時候,它只是沿著某種既定表示方式、既定工具鏈、既定目標函數,在一小塊空間裡高效率地移動。它探索的是可被它表示、可被它存取、可被它評估的部分,這不代表他能看到整個問題空間。也就是說,速度變快了,不代表視野真的變寬了。
第三種錯覺,是把機器生成誤認成沒有觀點,AI 看起來不像人在說話,沒有情緒、沒有立場、也沒有明顯偏好,因此人很容易把它當成某種中立鏡子。但 agent 從來不是在真空中運作,它會受到訓練資料、提示設計、工具可用性、記憶機制、評估方式與系統目標的共同塑形。所以它不是「沒有觀點」,而是帶著一種由資料與設計共同形成的觀點。很多時候,偏差不是消失了,而只是被包裝得更平滑、更像自然推論。
以上三種錯覺放在一起,會導致一個很關鍵的結果:AI 可能讓我們產出更多,卻不一定讓我們理解更多。它確實能把研究、分析、搜尋與執行流程推得更快,但越是這樣,我們越要警惕,不要把流暢的表現直接等同於完整的理解,也不要把自動化的過程直接等同於客觀的答案。
這也正是為什麼,真正高性能的 AI application,最後比拼的往往不只是模型本身,而是整個系統如何設計,問題不再只是「模型夠不夠強」,而是:
當你讀到這時,你就會從「模型崇拜」慢慢走向「系統設計」,而這,正是理解 agent 重要的一步。
Agent 真正重要的地方,不在於它比 chatbot 更酷,也不在於它能多調幾個工具,真正重要的是,我們如何運用它來設計 AI application。
當 AI 開始感知、規劃、行動與更新時,能力就不再只是藏在模型參數裡,而是分散在整個系統之中,你應該要開始思考:記憶怎麼設計、工具怎麼接、回饋怎麼進來、流程怎麼被控制、結果怎麼被驗證、風險又在哪裡被攔下。
這也是為什麼,很多人以為自己在做 Agent,最後真正卡住的卻不是模型,而是系統,在設計的過程中,你可能卡在 memory、tool use、evaluation、control flow、guardrails,或是卡在整個應用怎麼被組裝起來。
這篇文章詳細的說明了 Agent 的核心概念、運作方式、演化脈絡與常見誤解,為的是讓你能準備好開始理解 Agent Systems。
 Lucien
Lucien
