AI 協調者(orchestrators)雖然備受矚目,但當部署變得延遲且成本高昂時,開發者往往會忽略一個秘密武器:ADK 回呼掛鉤(callback hooks)。回呼掛鉤的設計模式與最佳實務,能讓開發者將邏輯從 Agent 重構至回呼掛鉤中,藉此增加觀察能力、降低成本與延遲,並動態修改工作階段狀態(session state)。
本文探討如何在 ADK Agent 的各個階段建立回呼掛鉤,以展示以下設計模式:
ADK 提供六種類型的回呼掛鉤,分別在 Agent 執行前後、模型執行前後以及工具執行前後被呼叫。
| 回呼類型 | 說明 |
|---|---|
| beforeAgentCallback | 在 Agent 的新週期開始前呼叫 |
| afterAgentCallback | 在 Agent 週期完成後呼叫 |
| beforeModelCallback | 在呼叫 LLM 之前呼叫 |
| afterModelCallback | 在 LLM 回傳回應後呼叫 |
| beforeToolCallback | 在工具被呼叫之前呼叫 |
| afterToolCallback | 在工具被呼叫之後呼叫 |
當我使用 ADK Web 進行本機測試與除錯時,首要任務是正確性。在 Agent 部署到 QA 環境之前,效能與 Token 使用量的優先級較低。
當產品經理與 QA 團隊發現明顯的延遲與高昂成本時,他們會通知我。接著,我檢查 Agent 以識別效能瓶頸,以及可由回呼掛鉤或應用程式程式碼處理的具決定性(deterministic)步驟。
在我的子 Agent 中使用回呼掛鉤具有幾個關鍵優勢:
| 類型 | 優點 |
|---|---|
| 短路(Short Circuit) | 呼叫 beforeModelCallback 驗證工作階段資料,並在資料無效時跳過 LLM 流程 |
| 關注點分離 | 在 beforeAgentCallback 中重設工作階段資料,使工具保持精簡並專注於業務邏輯 |
| 觀察能力 | 在 beforeAgentCallback 與 afterAgentCallback 中加入紀錄,以記錄效能指標 |
| 動態狀態管理 | 建立可重用的 afterToolCallback 來遞增驗證嘗試次數,並將回應狀態修改為 FATAL_ERROR |
協調者將專案描述路由到 sequentialEvaluationAgent。sequentialEvaluationAgent 由專案(project)、反模式(anti-patterns)、決策(decision)、建議(recommendation)、稽核(audit)、上傳(upload)、合併(merger)與電子郵件(email)子 Agent 組成。
在 project、anti-patterns、decision、recommendation 與 merger 子 Agent 中,我實作了回呼掛鉤來展示其功能與實用性。
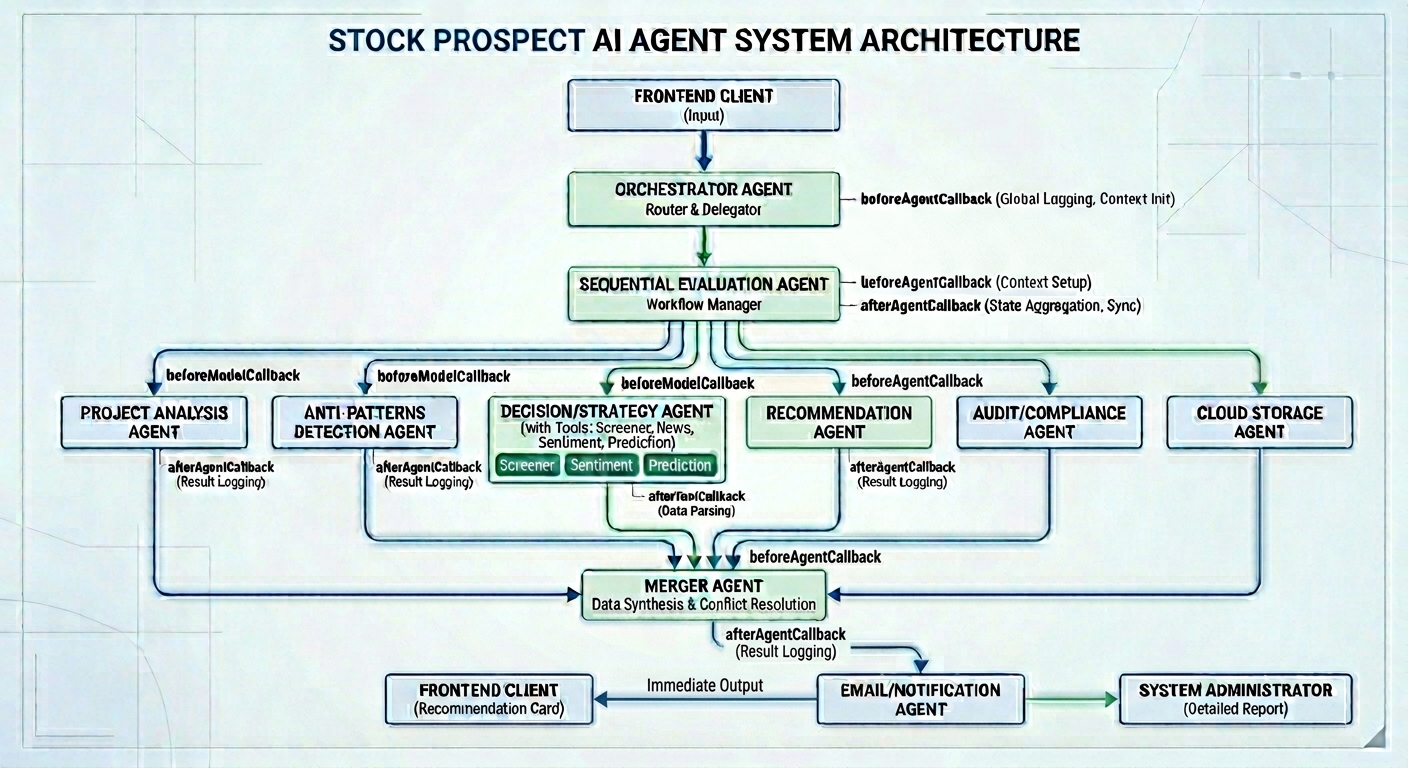
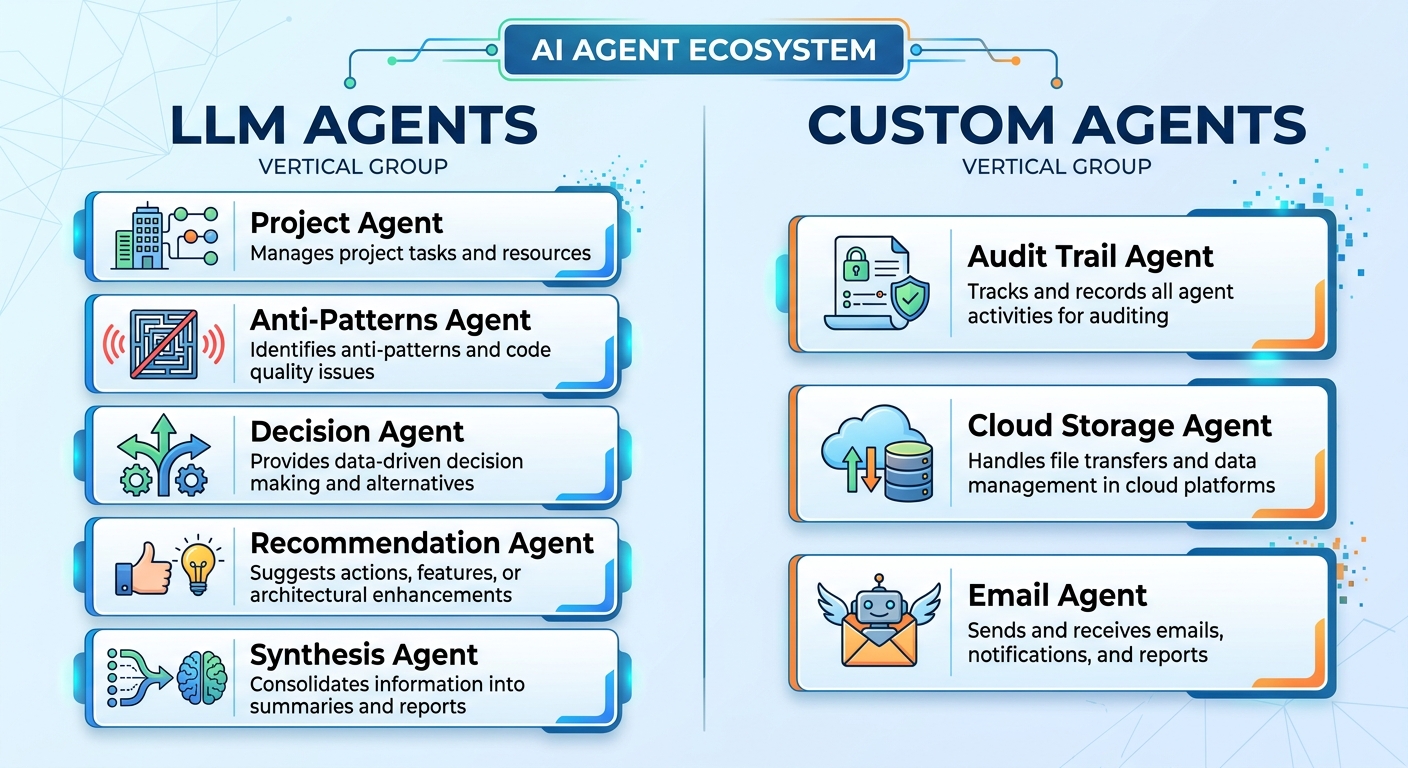
Google ADK 代表 Agent 開發工具包(Agent Development Kit)。它是一個開源的 Agent 框架,能讓開發者以便利的方式建置與部署 AI Agent。
專案、反模式、決策、建議與綜合 Agent 均為 LLM Agent。這些 Agent 需要 Gemini 進行推理並生成文字回應。
稽核軌跡(Audit Trail)、雲端儲存與電子郵件 Agent 則與外部 API 或資源整合,觸發具決定性的動作。
注意:由於地區可用性,我使用了 Vertex AI 中的 Gemini 進行身分驗證。Gemini 目前在香港無法直接使用;因此,我改用 Vertex AI 中的 Gemini。
npm i --save-exact @google/adk
npm i --save-dev --save-exact @google/adk-devtools
npm i --save-exact nodemailer
npm i --save-dev --save-exact @types/nodemailer rimraf
npm i --save-exact marked
npm i --save-exact zod
我安裝了建置 ADK Agent、將 Markdown 字串轉換為 HTML,以及在本地測試中向 MailHog 發送電子郵件所需的依賴項目。
固定依賴項目的版本可確保企業級應用程式在開發與正式環境中的版本一致。
將 .env.example 複製到 .env 並填入憑證:
GEMINI_MODEL_NAME="gemini-3.1-flash-lite-preview"
GOOGLE_CLOUD_PROJECT="<Google Cloud Project ID>"
GOOGLE_CLOUD_LOCATION="global"
GOOGLE_GENAI_USE_VERTEXAI=TRUE
# SMTP 設定 (MailHog)
SMTP_HOST="localhost"
SMTP_PORT=1025
SMTP_USER=""
SMTP_PASS=""
SMTP_FROM="no-reply@test.local"
ADMIN_EMAIL="admin@test.local"
SMTP_HOST、SMTP_PORT、SMTP_USER、SMTP_PASS 是在本機電子郵件測試中設定 MailHog 所必需的。
SMTP_FROM 是發件人電子郵件地址,在本機測試中可以是任何字串。
ADMIN_EMAIL 是接收 EmailAgent 發送之郵件的管理員電子郵件地址。在我的案例中,這是一個環境變數,因為它是唯一的收件者。如果另一個情境需要向客戶發送電子郵件,則應移除此環境變數。
以下是我在實務中實作這四種回呼設計模式的方法。
使用的回呼:beforeAgentCallback 與 afterAgentCallback
agentStartCallback 將當前時間(以毫秒為單位)儲存在工作階段狀態的 start_time 變數中。
import { SingleAgentCallback } from '@google/adk';
export const START_TIME_KEY = 'start_time';
export const agentStartCallback: SingleAgentCallback = (context) => {
if (!context || !context.state) {
return undefined;
}
context.state.set(START_TIME_KEY, Date.now());
return undefined;
};
agentEndCallback 從工作階段狀態獲取開始時間並計算持續時間。接著,它使用 console.log 記錄效能指標。此回呼回傳 undefined,以便任何子 Agent 始終能流向順序工作流程中的下一個。
export const agentEndCallback: SingleAgentCallback = (context) => {
if (!context || !context.state) {
return undefined;
}
const now = Date.now();
const startTime = context.state.get<number>(START_TIME_KEY) || now;
console.log(
`Performance Metrics for Agent "${context.agentName}": Total Elapsed Time: ${(now - startTime) / 1000} seconds.`,
);
return undefined;
};
接著,我在子 Agent 中呼叫這兩個回呼掛鉤,以瞭解它們執行所需的時間。以下範例顯示我如何記錄 project 子 Agent 的效能指標。
export function createProjectAgent(model: string) {
const projectAgent = new LlmAgent({
name: 'ProjectAgent',
model,
beforeAgentCallback: agentStartCallback,
instruction: (context) => {
... LLM instruction ....
},
afterAgentCallback: agentEndCallback,
...
});
return projectAgent;
}
使用的回呼:beforeAgentCallback
協調者在 Agent 生命週期開始前重設工作階段狀態中的變數。
export const AUDIT_TRAIL_KEY = 'auditTrail';
export const RECOMMENDATION_KEY = 'recommendation';
export const CLOUD_STORAGE_KEY = 'cloudStorage';
export const DECISION_KEY = 'decision';
export const PROJECT_KEY = 'project';
export const ANTI_PATTERNS_KEY = 'antiPatterns';
export const MERGED_RESULTS_KEY = 'mergedResults';
export const PROJECT_DESCRIPTION_KEY = 'project_description';
export const VALIDATION_ATTEMPTS_KEY = 'validation_attempts';
const resetNewEvaluationCallback: SingleAgentCallback = (context) => {
if (!context || !context.state) {
return undefined;
}
const state = context.state;
// 清除所有先前的評估資料
state.set(PROJECT_KEY, null);
state.set(ANTI_PATTERNS_KEY, null);
state.set(DECISION_KEY, null);
state.set(RECOMMENDATION_KEY, null);
state.set(AUDIT_TRAIL_KEY, null);
state.set(CLOUD_STORAGE_KEY, null);
state.set(MERGED_RESULTS_KEY, null);
state.set(VALIDATION_ATTEMPTS_KEY, 0);
console.log(
`beforeAgentCallback: Agent ${context.agentName} has reset the session state for a new evaluation cycle.`,
);
return undefined;
};
協調者在 beforeAgentCallback 中將變數設置為 null。在 prepareEvaluationTool 中,協調者僅將 description 替換為新的專案描述。
const prepareEvaluationTool = new FunctionTool({
name: 'prepare_evaluation',
description: 'Stores the new project description to prepare for a fresh evaluation.',
parameters: z.object({
description: z.string().describe('The validated project description from the user.'),
}),
execute: ({ description }, context) => {
if (!context || !context.state) {
return { status: 'ERROR', message: 'No session state found.' };
}
// 為 ProjectAgent 設定新的描述
context.state.set(PROJECT_DESCRIPTION_KEY, description);
return { status: 'SUCCESS', message: 'Description updated.' };
},
});
工具邏輯更有效率,且 Token 使用量也隨之減少。
export const rootAgent = new LlmAgent({
name: 'ProjectEvaluationAgent',
model: 'gemini-3.1-flash-lite-preview',
beforeAgentCallback: resetNewEvaluationCallback,
instruction: `
... LLM instruction ....
`,
tools: [prepareEvaluationTool],
subAgents: [sequentialEvaluationAgent],
});
協調者使用 resetNewEvaluationCallback 重設工作階段變數,並使用 prepareEvaluationTool 替換專案描述。最後,sequentialEvaluationAgent 開始 Agent 流程以推導決策並生成建議。
前提條件:子 Agent 使用工具調用(tool calling)來執行動作
使用的回呼:afterToolCallback
使用案例是遞增工作階段狀態中 validation_attempts 的值。諮詢 AI 後,project 與 decision 子 Agent 的 afterToolCallback 階段是遞增該值的理想位置。因此,我定義了一個 meta 函式來建立一個 afterToolCallback 以遞增驗證嘗試次數。
export const VALIDATION_ATTEMPTS_KEY = 'validation_attempts';
export const MAX_ITERATIONS = 3;
import { AfterToolCallback } from '@google/adk';
import { VALIDATION_ATTEMPTS_KEY } from '../output-keys.const.js';
import { MAX_ITERATIONS } from '../validation.const.js';
export function createAfterToolCallback(fatalErrorMessage: string, maxAttempts = MAX_ITERATIONS): AfterToolCallback {
return ({ tool, context, response }) => {
if (!tool || !context || !context.state) {
return undefined;
}
const toolName = tool.name;
const agentName = context.agentName;
const state = context.state;
if (!response || typeof response !== 'object' || !('status' in response)) {
return undefined;
}
// [1] 動態狀態管理
const attempts = (state.get<number>(VALIDATION_ATTEMPTS_KEY) || 0) + 1;
state.set(VALIDATION_ATTEMPTS_KEY, attempts);
// [2] 回應修改
const status = response.status || 'ERROR';
if (status === 'ERROR' && attempts >= maxAttempts) {
context.actions.escalate = true;
return {
status: 'FATAL_ERROR',
message: fatalErrorMessage,
};
}
};
}
在 project 與 decision 子 Agent 中,我呼叫 createAfterToolCallback 來建立各自的 afterToolCallback 以遞增驗證嘗試次數。
const projectAfterToolCallback = createAfterToolCallback(
`STOP processing immediately. Max validation attempts reached. Return the most accurate data found so far or empty strings if none.`,
);
const decisionAfterToolCallback = createAfterToolCallback(
`STOP processing immediately and output the final JSON schema with verdict: "None".`,
);
接著,我在 project 子 Agent 的 afterToolCallback 階段呼叫 projectAfterToolCallback。
export function createProjectAgent(model: string) {
const projectAgent = new LlmAgent({
name: 'ProjectAgent',
model,
beforeAgentCallback: agentStartCallback,
instruction: (context) => {
... LLM instruction ....
},
afterToolCallback: projectAfterToolCallback,
afterAgentCallback: agentEndCallback,
tools: [validateProjectTool],
...
});
return projectAgent;
}
接著,我在 decision 子 Agent 的 afterToolCallback 階段呼叫 decisionAfterToolCallback。
export function createDecisionTreeAgent(model: string) {
const decisionTreeAgent = new LlmAgent({
name: 'DecisionTreeAgent',
model,
beforeAgentCallback: [resetAttemptsCallback, agentStartCallback],
instruction: (context) => {
... instruction of the LLM flow ...
},
afterToolCallback: decisionAfterToolCallback,
afterAgentCallback: agentEndCallback,
tools: [validateDecisionTool],
...
});
return decisionTreeAgent;
}
前提條件:子 Agent 使用工具調用來執行動作
使用的回呼:AfterToolCallback
同一個 AfterToolCallback 也會在驗證嘗試次數超過最大迭代次數時修改回應。
當狀態為 ERROR 且 validation_attempts 的值達到至少 maximum_iterations 時,context.actions.escalate 旗標會設為 true,以跳出迴圈。此外,狀態會變更為 FATAL_ERROR 並回傳自定義的致命錯誤訊息。
這是避免不必要的 LLM 執行的重要設計模式。
使用的回呼:beforeModelCallback。
在我的子 Agent 中,我執行此回呼以驗證工作階段資料。當滿足特定條件時,回呼會立即回傳內容,以跳過隨後的 LLM 流程。
如果 project Agent 能將專案描述分解為任務(task)、問題(problem)、約束(constraint)與目標(goal),Agent 將立即回傳分解結果。否則,Agent 會提示 Gemini 使用推理來執行分解。
import { SingleBeforeModelCallback } from '@google/adk';
const beforeModelCallback: SingleBeforeModelCallback = ({ context }) => {
const { project } = getEvaluationContext(context);
const { isCompleted } = isProjectDetailsFilled(project);
if (isCompleted) {
return {
content: {
role: 'model',
parts: [
{
text: JSON.stringify(project),
},
],
},
};
}
return undefined;
};
接著,將 beforeModelCallback 掛鉤到 project 子 Agent 的 beforeModelCallback 階段。
export function createProjectAgent(model: string) {
const projectAgent = new LlmAgent({
name: 'ProjectAgent',
model,
description:
'Analyzes the user-provided project description to extract and structure its core components, including the primary task, underlying problem, ultimate goal, and architectural constraints.',
beforeAgentCallback: agentStartCallback,
beforeModelCallback,
instruction: (context) => {
const { projectDescription } = getEvaluationContext(context);
if (!projectDescription) {
return '';
}
return generateProjectBreakdownPrompt(projectDescription);
},
afterToolCallback: projectAfterToolCallback,
afterAgentCallback: agentEndCallback,
tools: [validateProjectTool],
outputSchema: projectSchema,
outputKey: PROJECT_KEY,
disallowTransferToParent: true,
disallowTransferToPeers: true,
});
return projectAgent;
}
decision Agent 在 beforeModelCallback 中驗證 verdict 屬性。如果 verdict 不是 None,回呼會立即回傳有效的決策。若 verdict 為 None,回呼會檢查專案分解與反模式。當提供專案分解與反模式時,回呼會回傳 undefined 以觸發 LLM 流程。否則,decision Agent 就沒有有效的輸入來推導結論。回呼在此邊緣情況下會回傳 None。
import { SingleBeforeModelCallback } from '@google/adk';
const beforeModelCallback: SingleBeforeModelCallback = ({ context }) => {
const { decision } = getEvaluationContext(context);
if (decision && decision.verdict !== 'None') {
return {
content: {
role: 'model',
parts: [
{
text: JSON.stringify(decision),
},
],
},
};
}
const { project, antiPatterns } = getEvaluationContext(context);
const { isCompleted } = isProjectDetailsFilled(project);
if (isCompleted && antiPatterns) {
return undefined;
}
return {
content: {
role: 'model',
parts: [
{
text: JSON.stringify({
verdict: 'None',
nodes: [],
}),
},
],
},
};
};
接著,將 beforeModelCallback 掛鉤到 project 子 Agent 的 beforeModelCallback 階段。
export function createDecisionTreeAgent(model: string) {
const decisionTreeAgent = new LlmAgent({
name: 'DecisionTreeAgent',
model,
beforeAgentCallback: [resetAttemptsCallback, agentStartCallback],
beforeModelCallback,
instruction: (context) => {
... instruction of the LLM flow ...
},
afterToolCallback: decisionAfterToolCallback,
afterAgentCallback: agentEndCallback,
tools: [validateDecisionTool],
outputSchema: decisionSchema,
outputKey: DECISION_KEY,
disallowTransferToParent: true,
disallowTransferToPeers: true,
});
return decisionTreeAgent;
}
recommendation Agent 使用 beforeModelCallback 來檢查專案分解、反模式與結論(verdict)。有兩種情況需要 LLM 生成建議。第一種情況是有效的專案分解、反模式以及非 None 的結論。第二種情況是不完整的專案分解與 None 結論。LLM 被指示描述專案分解中缺失的欄位,以及該缺失欄位對於獲得有效決策的重要性。對於其他情況,回呼會立即回傳靜態建議並跳過隨後的 LLM 流程。
function constructRecommendation(recommendation: string) {
return {
content: {
role: 'model',
parts: [
{
text: JSON.stringify({
text: recommendation,
}),
},
],
},
};
}
const beforeModelCallback: SingleBeforeModelCallback = ({ context }) => {
const { project, antiPatterns, decision } = getEvaluationContext(context);
const { isCompleted } = isProjectDetailsFilled(project);
const isDecisionNone = decision && decision.verdict === 'None';
if ((isCompleted && antiPatterns && decision && decision.verdict !== 'None') || (!isCompleted && isDecisionNone)) {
return undefined;
} else if (isCompleted && isDecisionNone) {
return constructRecommendation(
'## Recommendation: Manual Review Required\n\n**Status:** Abnormal Case Detected\n\nThe provided project is complete and valid, but the decision tree could not reach a conclusive verdict (Result: `None`).\n\n**Possible Reasons:**\n- The requirements fall outside of known architectural patterns.\n- There are conflicting constraints and goals that cannot be resolved automatically.\n\n**Next Steps:**\n- Review and refine the constraints or goals.\n- Escalate for manual architectural review.',
);
}
return constructRecommendation(
'## Recommendation: Data Required\n\n**Status:** Abnormal Case Detected\n\nNo decision is reached.',
);
};
與之前的 project 與 decision Agent 類似,beforeModelCallback 函式被掛鉤到 recommendation Agent 的 beforeModelCallback 階段。
export function createRecommendationAgent(model: string) {
const recommendationAgent = new LlmAgent({
name: 'RecommendationAgent',
model,
beforeModelCallback,
beforeAgentCallback: agentStartCallback,
instruction: (context) => {
const { project, antiPatterns, decision } = getEvaluationContext(context);
const { isCompleted, missingFields } = isProjectDetailsFilled(project);
if (project) {
if (!isCompleted && decision && decision.verdict === 'None') {
console.log('RecommendationAgent -> generateFailedDecisionPrompt');
return generateFailedDecisionPrompt(project, missingFields);
} else if (isCompleted && antiPatterns && decision && decision.verdict !== 'None') {
console.log('RecommendationAgent -> generateRecommendationPrompt');
return generateRecommendationPrompt(project, antiPatterns, decision);
}
}
return 'Skipping LLM due to missing data.';
},
afterAgentCallback: agentEndCallback,
outputSchema: recommendationSchema,
outputKey: RECOMMENDATION_KEY,
disallowTransferToParent: true,
disallowTransferToPeers: true,
});
return recommendationAgent;
}
這些是該 Agent 採用的回呼設計模式。在下一節中,我將描述如何啟動 Agent 以在終端機中觀察記錄訊息。
我從 Docker Hub 取得了最新版本的 MailHog Docker 映像檔,並在本機啟動它以接收測試電子郵件並顯示在 Web UI 中。docker-compose.yml 檔案包含設定配置。
services:
mailhog:
image: mailhog/mailhog
container_name: mailhog
ports:
- '1025:1025' # SMTP port
- '8025:8025' # HTTP (Web UI) port
restart: always
networks:
- decision-tree-agent-network
networks:
decision-tree-agent-network:
SMTP 埠號為 1025,Web UI 埠號的 URL 為 http://localhost:8025。
docker compose up -d
在 Docker 中啟動 MailHog。
將指令碼新增到 package.json 以建置並啟動 ADK Web 介面。
"scripts": {
"prebuild": "rimraf dist",
"build": "npx tsc --project tsconfig.json",
"web": "npm run build && npx @google/adk-devtools web --host 127.0.0.1 dist/agent.js"
},
npm run web 以啟動 API 伺服器。http://localhost:8000。One of my favorite tech influencers just tweeted about a 'breakthrough in solid-state batteries.' Find which public company they might be referring to, check that company’s recent patent filings to see if it’s true, and then check their stock price to see if the market has already 'priced it in'.
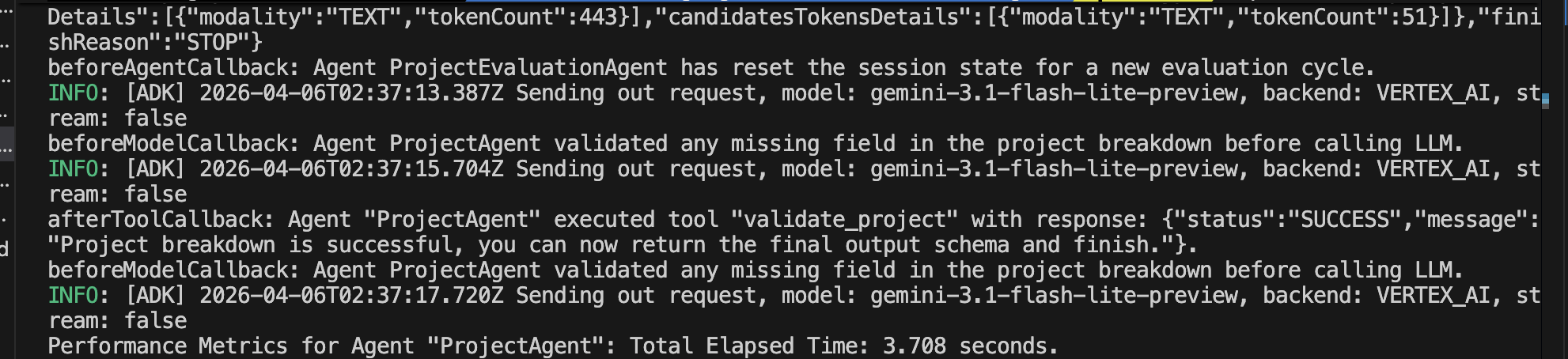
beforeAgentCallback 與 afterAgentCallback 來記錄效能指標。它們還使用 beforeModelCallback 在呼叫 LLM 生成回應之前驗證工作階段資料。此外,決策 Agent 在 afterToolCallback 中遞增驗證嘗試次數,並在嘗試次數超過或等於最大迭代次數時將狀態修改為 FATAL_ERROR。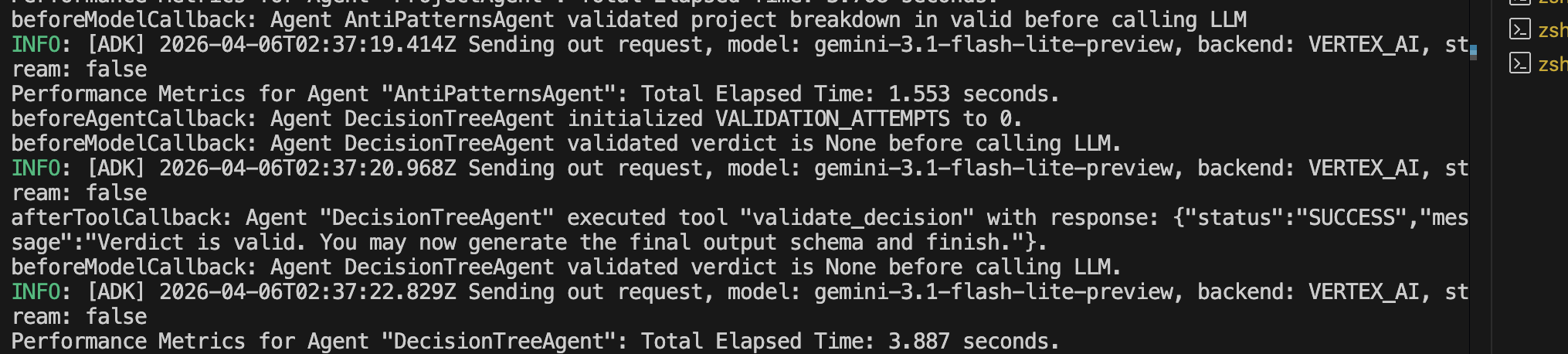
beforeAgentCallback 與 afterAgentCallback 來記錄效能指標。建議 Agent 還使用 beforeModelCallback 在呼叫 LLM 生成建議之前驗證工作階段資料。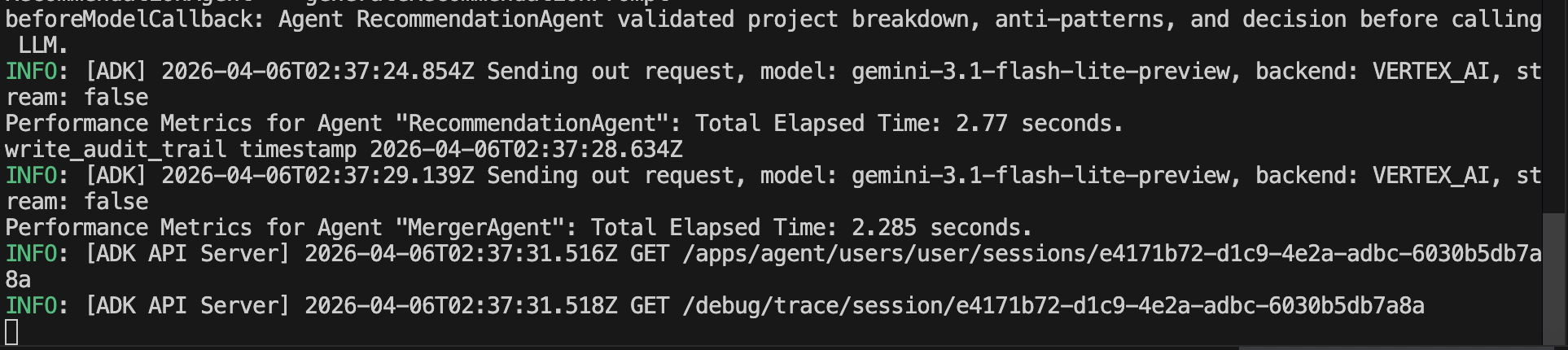
ADK 支援適用於不同使用案例的生命週期回呼掛鉤。在本文中,我介紹了在 beforeAgentCallback 與 afterAgentCallback 中記錄效能指標。我將協調者的重設工作階段狀態邏輯重構至 beforeAgentCallback 中,使工具保持精簡且更具成本效益。afterToolCallback 則在驗證重試迴圈中的次數超過最大迭代次數時,向更高級別的 Agent 呈報(escalate)並修改回應狀態為 FATAL_ERROR。當有條件地跳過 LLM 呼叫時,beforeModelCallback 會立即回傳自定義內容。如此一來,Agent 就不會為流程增加不必要的時間,也不會消耗 Token。
重點在於:遵循 Agent 各個階段的回呼設計模式與最佳實務,以記錄效能指標、降低成本與延遲,並修改回應。
 Connie
Connie
