想請問一下,在文字編輯器中(例如:EmEditor),尋找取代時下達:
[^(我們)]
可以選擇到文字字串中,「我們」以外的文字內容,進而取代(等於是刪除)。
但我不想連「們我」、「我」、「們」,這樣的組合都排除在外,(想一起包含進去,取代刪除)
應該如何修改上面的指令內容呢?
已邀請的邦友 {{ invite_list.length }}/5
可以選擇到文字字串中,「我們」以外的文字內容,進而取代(等於是刪除)。
跑兩次: 一次跑 [^(我)], 另一次跑 [^(們)]
....別打我, 我來亂的.....
raytracy提到:
跑兩次: 一次跑 [^(我)], 另一次跑 [^(們)]
這樣跑過[^(我)],也不會有「們」留下來吧 :)
其實把括弧拿掉就好了阿...
<pre class="c" name="code">[^我們]
搜尋取代內容為:[^我們]時,
一樣會把**「們我」、「我」、「們」**
排除在外的,我試了很多次,就是想找出一個解決的辦法。
是不是可以設定兩種以上的「篩選條件」?
就用 | (or)阿
你還是沒回答我的問題= =~
看不懂你到底要幹嘛
我若要在這個文件中,刪掉「我們」以外的內容,(就是不要一個一個刪,因為文件是範例,真實的檔案不只這樣)。
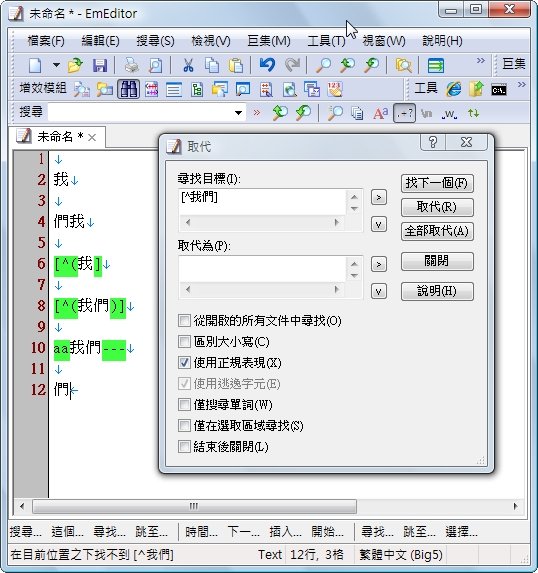
如果會這個語法,那我在檔案中,想快速刪掉某些關鍵字以外的內容,就可以達成。
從你的截圖及你相要的結果,
是圖中只會留 第 8,10 行有「我們」一行兩個字外,
其他1到12行就只是有空行(^$)嗎?
所以你最終的意圖是,
只把「我們」這詞留在原行數裡的第一格,
其他東西都刪掉嗎?
是的!
如果這樣的話,假設 we 檔案內容是:
<pre class="c" name="code">
這是我們的一些自們我
們們就有我好是們又○我
上面空有們我 們我我們
用 awk 執行:
<pre class="c" name="code">awk '{if (/我們/) {print "我們"} else {print ""}}' we
獲得結果為:
<pre class="c" name="code">
我們
我們
符合你的需要嗎?
如果 檔案中有 兩個或兩個 以上的「我們」的話,
上述的 awk script 只會印出一個「我們」,
如果要一行有幾個「我們」就要印出幾個「我們」的話,
用perl的一行指令就可搞定:
<pre class="c" name="code">perl -ne 'if ($count = ($_ =~ s/我們/ZZ/g)) {print "我們" x"$count"."\n"} else {print "\n"}' we
不好意思,這如果在「EmEditor」的使用下,應該下的指令是什麼呢?
其實自己並不是資訊系,程式並不完全瞭解,
使用這個功能是用來作文獻研究的。
在你的 regex 裡,
剛好是碰到易混淆的地方:
[abc] 跟 (a|b|c)
好像功能是一樣,
但 ^ 不 match 的只能用在 [] 裡。
^ 是一種:
A negated character class is simple a notational convenience for a normal character class that matches everything not listed.
所以,
[quoe][^x] doesn't mean "match unless there is an x," but rather "match if there is something that is not x." The difference is subtle, but important. The first concept matches a blank line, for example, while, in reality, [^x] does not.[/quote]
這是從 Mastering Regular Expressions第15頁抄來的。
新版是第三版,這段內容沒什麼變。
引上述這段話我不大會說明,
但從你所要獲得的結果,
想要用 [^(我們)] 這語法,可以理解意圖,
但從上述的說明,覺得應是行不通。
所以用 awk 或 perl 的處理,就能得到你想要的結果。
這兩個工具在 linux 幾乎都有內建。
在 windows 環境下可以:
安裝 Gawk for Windows
下載 此壓縮檔
只要把壓縮檔裡 bin 裡的 awk.exe 複製到 C:\Windows 下,就可在 CMD 裡執行 awk 了。
windows 版的 perl 可安裝 這安裝檔
搜尋一下 sed, awk, perl 的使用介紹及範例,
因看您的 blog 是要大量處理文字的東西,
圖形界面的編輯器在 regular expression 上的處理有限,
可試試了解 sed, awk, perl 所能做到的程度。
大力推 sed, awk, perl;
並簡單舉例為何在您處理的議題好用。
以您在:
搜尋「\d」與「[^\d]」這篇文的範例:
http://blog.yam.com/ebag/article/28828908
ebag的內容為:
<pre class="c" name="code">書斷 唐・張懷瓘 5
捲上 杉村邦彥譯 10
古文 18
大篆 25
籀文 27
小篆 28
八分 30
隸書 34
章草 38
行書 43
飛白 46
草書 49
分別以這三個工具來達到圖型界面編輯器做到的結果:
<pre class="c" name="code">sed -e 's/ \([0-9]*\)$/(\1) \1/g' ebag
perl -ne 'if ($_ =~ s/(.*) (\d+)$/$1($2) $2/) {print "$_";}' ebag
基本上 awk 是這樣也可得您要的結果:
<pre class="c" name="code">awk '{print $1"("$2") "$2}' ebag
但 不適用,因為前兩行空格為間隔的三個分欄,
與第三行以下只有兩欄,
如果每一行都只有兩分欄的話,
awk 最易用。
