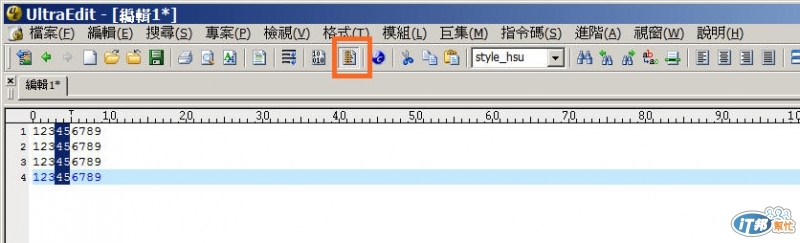
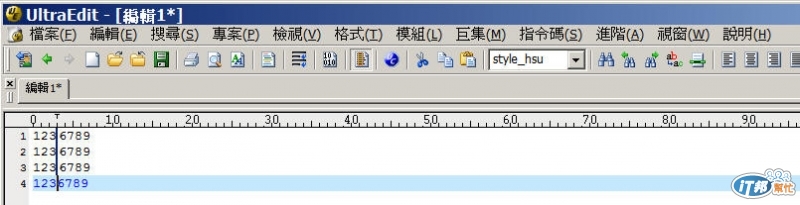
請問一下如下面的文字要重新排除了一個一個移,是否有別的方式可以比較快的處理,或是用程式寫也可以??筆數少還可以移,多了真受不了~
例
001abCDE0102
002asDFG0202
005dfGGH0105
寫成
001CDE01
001CDE02
002DFG02
002DFG02
005GGH01
005GGH05
像這樣的
已邀請的邦友 {{ invite_list.length }}/5
既然是 Windows, 用 powershell 好了, Windows7 有內建, XP需要另外安裝
把原始資料放在 data.txt 裡面, 然後開啟 powershell, cd 到你 data.txt 所在位置
以下是指令與結果:
<pre class="c" name="code">
cat .\data.txt | %{$_ -replace '^([0-9]+)..(.*)$','$1$2'} | %{$p1=([regex]::matches($_,'^\w{6}')|%{$_.Value});[regex]::matches($_,'(\d+)$')|%{$_.Value -split "(\w{2})"}|?{$_}|%{echo $p1$_}} > result.txt
產生:
001CDE01
001CDE02
002DFG02
002DFG02
005GGH01
005GGH05
要排序的話:
<pre class="c" name="code">
cat .\data.txt | %{$_ -replace '^([0-9]+)..(.*)$','$1$2'} | %{$p1=([regex]::matches($_,'^\w{6}')|%{$_.Value});[regex]::matches($_,'(\d+)$')|%{$_.Value -split "(\w{2})"}|?{$_}|%{echo $p1$_}} | sort > result.txt
會產生:
001CDE01
001CDE02
002DFG02
002DFG02
004GGH01
004GGH05
005GGH01
005GGH05
那個 004 是我放進去測排序的
指令有點長, 大致上做的事情是:
0. 用 cat 讀取 data.txt 裡面的原始資料
順便說, 這個指令還可以處理更多後面的數字, 例如 001abCDE0102030405, 會跑出五筆來
不過在這個情況下會出錯: 001abCD30102, 我把倒數第五的E換成3, 會切成 30 10 2 三筆
我資料長度是固定的,
(\W{3})取前三個字元,=$1
兩個..跳過兩個字元,
(\W{3})再取三個字元,=$2
(\W{2})取二個字元,=$3
(\W{2})再取二個字元=$4
把S1+S2+S3
換行
再S1+S2+S4
這樣理解是否正確?可是如果其中有空白字元,會不會出問題?
正確
如果有空白字元的話, 你可以先用記事本的搜尋取代先處理掉
或是一併在 script 處理:
<pre class="c" name="code">
cat .\data.txt | %{$_ -replace '\s', ''} | %{$_ -replace '^(\w{3})..(\w{3})(\w{2})(\w{2})$',"`$1`$2`$3`n`$1`$2`$4"} > result.txt
那個 -replace '\s', '' 就是把所有的空白字元, 包含 tab 之類的都先刪掉
這樣子就算原始資料長成這樣也ok:
<pre class="c" name="code">
001 a bCD E0102
002asDFG0202
00 5dfG GH01 05
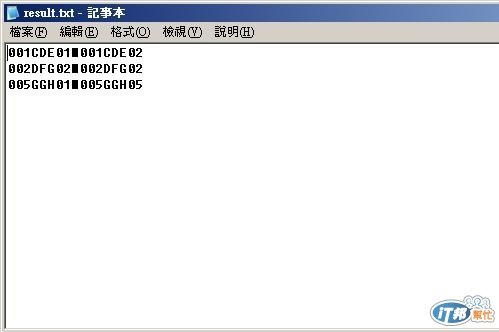
cat .\data.txt | %{$_ -replace '\s', ''} | %{$_ -replace '^(\w{3})..(\w{3})(\w{2})(\w{2})$',"
$1$2$3n$1$2`$4"} > result.txt
我使用這個測試下去,輸出結果為上,應用在讀入文字檔的程式中不會有問題嗎?
另外如果是像這樣的空白要如何作呢?用上面的會出現錯誤格式
001abCDE0102
002asDFG0202
005dfGGH0105
004 CDE0102
009abCFE02
008abCQE 01
補充:空格現我作的都是兩格,像這種含空白字數均相同的資料,語法是否有可補的地方?
第一個換行的問題, win7的記事本顯示沒問題, 所以我以為 xp 的記事本也ok
你把 "$1$2$3n$1$2$4" 改成 "$1$2$3rn$1$2`$4" 應該就都正常了
第二個問題, 會出現錯誤不是因為空白的關係, 而是你的格式變了
例如 004 CDE0102, 004後面應該還有兩個小寫字母
還有 008abCQE 01, CQE後面應該有四位數字
如果要考慮這種情況的話, 就比較複雜一些
懶一點的作法, 就是不管最後是一組還是兩組數字, 都先切割成兩行資料
最後再篩選出長度大於等於 8 的:
<pre class="c" name="code">
cat .\data2.txt | %{$_ -replace '\s', ''} | %{$_ -replace '^(\d{3}).?.?([A-Z]{3})(\d{2})(\d{2})?$',"`$1`$2`$3`r`n`$1`$2`$4"} | %{$_ -split "`r?`n"} | ?{$_.length -ge 8}
10284323提到:
像這種含空白字數均相同的資料,語法是否有可補的地方?
%{$_ -replace '\s', ''} 已經濾掉所有的空格以及tab了, 所以你要用多少空格都沒影響, 數量相同或不同都一樣
如果這需求不常用,那就如 hon2006 所述,直接以可直行編輯的 editor 來改即可。
如 Ultraedit (要錢的)、RJ TextEd (免錢的) 等。
如果這需求常用,那就考慮使用 sed 之類的工具來處理。若你自己有 Linux 環境,那就把檔案放到 Linux 中,在命令列中下此命令即可
<pre class="c" name="code">sed 's/^\(...\)..\(.....\)..$/\1\2/' < 原檔.txt | sort > 新檔.txt
PS. 若沒 Linux 就下載 UnxUtils 到 windows 來用 sed 與 sort。
<pre class="c" name="code">
$ cat t1.txt
001abCDE0102
002asDFG0202
005dfGGH0105
$ cut -c 1-3 t1.txt > t2.txt
$ cut -c 6-12 t1.txt > t3.txt
$ paste -d '' t2.txt t3.txt > t4.txt
$ cut -c 1-8 t4.txt > t5.txt
$ cut -c 1-6 t4.txt > t6.txt
$ cut -c 9-10 t4.txt > t7.txt
$ paste -d '' t6.txt t7.txt > t8.txt
$ cat t5.txt t8.txt > t9.txt
$ sort t9.txt > t10.txt
001CDE01
001CDE02
002DFG02
002DFG02
005GGH01
005GGH05
步驟並沒有最佳化.
把檔案用 excel 打開
用幾行簡單的VBA 指令可以作到
for i= 1 to 65535 '' 或你最多會有幾筆
if sheets(1).cells(i,1)="" then END
ss=sheets(1).cells(i,1)
ss1=left(ss,3) & mid(ss,6,3) & mid(ss,9,2)
sheets(2).cells(2*(i-1)+1,1)=ss1
ss2=left(ss,3) & mid(ss,6,3) & mid(ss,11,2)
sheets(2).cells(2*(i-1)+2,1)=ss2
next
但如果你的字串長度可能會變, 程式可能需要改下