各位前輩好~
因最近公司主機老舊廠商已無維護,
深怕哪天掛個幾台就GG了,
所以最近有汰舊換新的念頭,
但不知道該怎麼測試新機器跟舊機器的效能落差,
不知道是否有類似windows跑分之類的方式能顯示呢?
謝謝!
已邀請的邦友 {{ invite_list.length }}/5
想要測效能的目的是甚麼? 難不成您預期新機會跑得比舊機差?
然後, 你的舊機曾經測過效能嗎?
如果沒有測過的話, 要拿甚麼基準來跟新機比較?
最後, 你要先確定想測甚麼數據? 要測到多細多深?
數據測出來, 結果要出現甚麼值才是你可以接受的?
要測 TCP packet 的 drop rate 嗎?
要測 Kernel 的 softirq ratio 嗎?
I/O 要測 4K block 還是 128K block?
我可以列出上千個項目讓你測試, 問題是:
你的伺服器運轉, 影響最關鍵的數據項目是甚麼?
你怎麼知道哪個數據多高或多低才是可以接受的?
這世上沒有完美的數據, 對某家公司的 ERP 來說, 或許:
A=100, B=50, C=1 是最佳值,
但對另外一家公司的 ERP 來說, 或許:
A=20, B=120, C=50 才是最佳值,
因為 Workload 特性不同, 要求的配合參數也會不同
還有, 你能忍受那些不完美的數據到甚麼程度?
請在任何一台系統內下個 netstat -s 的指令, 你會看到:
Ip:
661234105 total packets received
0 forwarded
0 incoming packets discarded
661233500 incoming packets delivered
636935235 requests sent out
41 outgoing packets dropped
80 dropped because of missing route
1098 reassemblies required
501 packets reassembled ok
Icmp:
18785 ICMP messages received
94 input ICMP message failed.
ICMP input histogram:
destination unreachable: 3045
echo requests: 15738
echo replies: 2
16523 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 783
echo request: 2
echo replies: 15738
IcmpMsg:
InType0: 2
InType3: 3045
InType8: 15738
OutType0: 15738
OutType3: 783
OutType8: 2
Tcp:
316660 active connections openings
81405 passive connection openings
284707 failed connection attempts
778 connection resets received
66 connections established
555028662 segments received
1190626405 segments send out
59592 segments retransmited
0 bad segments received.
571646 resets sent
Udp:
106072196 packets received
360 packets to unknown port received.
42 packet receive errors
106935547 packets sent
InCsumErrors: 42
IgnoredMulti: 47208
UdpLite:
TcpExt:
11 resets received for embryonic SYN_RECV sockets
114 ICMP packets dropped because they were out-of-window
47472 TCP sockets finished time wait in fast timer
5470 packets rejects in established connections because of timestamp
5403800 delayed acks sent
3672 delayed acks further delayed because of locked socket
Quick ack mode was activated 19276 times
45284470 packets directly queued to recvmsg prequeue.
836669095 bytes directly in process context from backlog
352545420637 bytes directly received in process context from prequeue
388059178 packet headers predicted
47533993 packets header predicted and directly queued to user
12885676 acknowledgments not containing data payload received
291619868 predicted acknowledgments
24753 times recovered from packet loss by selective acknowledgements
Detected reordering 64 times using FACK
Detected reordering 19 times using SACK
Detected reordering 89 times using time stamp
518 congestion windows fully recovered without slow start
477 congestion windows partially recovered using Hoe heuristic
23317 congestion windows recovered without slow start by DSACK
740 congestion windows recovered without slow start after partial ack
TCPLostRetransmit: 24
1 timeouts after SACK recovery
31275 fast retransmits
8143 forward retransmits
568 retransmits in slow start
2035 other TCP timeouts
TCPLossProbes: 17478
TCPLossProbeRecovery: 19
19320 DSACKs sent for old packets
1 DSACKs sent for out of order packets
46940 DSACKs received
2 DSACKs for out of order packets received
53 connections reset due to unexpected data
12 connections reset due to early user close
18 connections aborted due to timeout
TCPDSACKIgnoredOld: 99
TCPDSACKIgnoredNoUndo: 7895
TCPSpuriousRTOs: 366
TCPSackShifted: 14827
TCPSackMerged: 31714
TCPSackShiftFallback: 181941
TCPRetransFail: 1
TCPRcvCoalesce: 4338729
TCPOFOQueue: 958371
TCPOFOMerge: 1
TCPChallengeACK: 18
TCPSpuriousRtxHostQueues: 125
TCPAutoCorking: 1039190
TCPFromZeroWindowAdv: 672
TCPToZeroWindowAdv: 672
TCPWantZeroWindowAdv: 138245
TCPSynRetrans: 255
TCPOrigDataSent: 1044440082
TCPHystartTrainDetect: 664
TCPHystartTrainCwnd: 16513
TCPHystartDelayDetect: 9
TCPHystartDelayCwnd: 351
TCPACKSkippedSynRecv: 15
TCPACKSkippedSeq: 3
TCPKeepAlive: 3099160
IpExt:
InMcastPkts: 6818558
OutMcastPkts: 7202245
InBcastPkts: 47208
InOctets: 6176389756857
OutOctets: 3132774262145
InMcastOctets: 4503556472
OutMcastOctets: 3468997300
InBcastOctets: 5775112
InNoECTPkts: 1263469138
請問看了以上數據, 您知道哪一個代表效能低落的狀態?
如果你分辨不出狀態的話, 測出一大堆數據, 有意義嗎?
如果你發現, 查詢一筆紀錄, 原本要花 1秒, 現在變成 2秒;
請問: 這是誰的效能變差了?
CPU 變差? RAM 變差? 網卡變差? Switch 變差? 還是 Storage?
還是根本就是程式沒寫好:
遇到不同條件時, 查詢效能會不一樣? (上周才有人發問的)
如果平常沒有建立現有系統的基準監測值,
又要如何知道新機跟舊機的差異, 會影響多少?
所以先反問: 您平時都在監測舊機的那些效能數據?
如果平常都沒有在監測的話, 那又何必擔心新機呢?
反正新機不可能比舊機更差啊, 您覺得有沒有說錯?
這是今天我某一台伺服器裡面, 10 顆 CPU 的監測圖,
請問, 您看過之後, 覺得這是正常的? 還是異常的?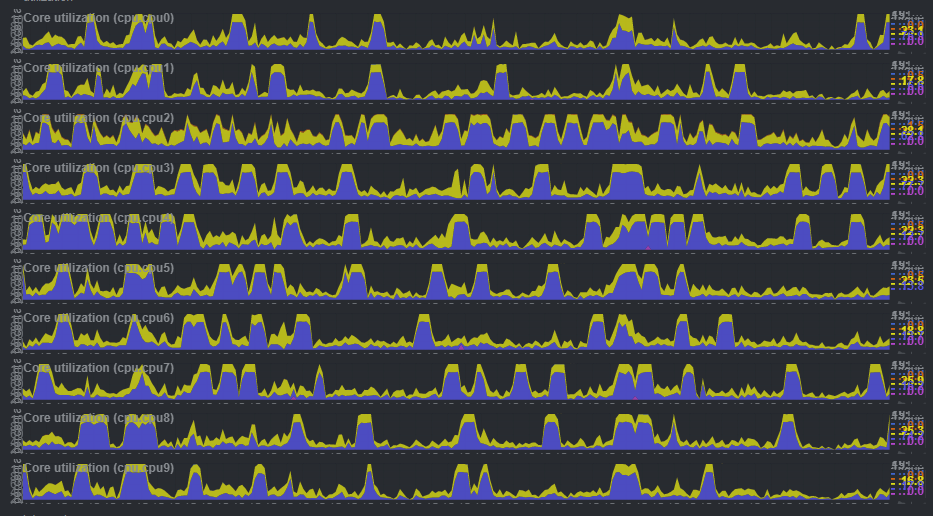
我可以明確的說: 這是異常的.............可是, 為什麼?
因為我天天在看這張圖, 他以前不是這種形狀, 今天突然變這樣, 就算沒去細看每一個數值, 我都可以警覺到: 他有甚麼奇怪的事情發生了? 再比對我的工作日誌, 就可以很清楚知道: 我在甚麼時間點, 做了甚麼事情, 導致他變成這個結果.
但是, 我如果沒有長期觀測舊的監測圖, 又怎知這是異常?
據此, 若這張圖由你家伺服器產出的話, 是異常還是正常?
這是我某一台 MySQL 資料庫的每日統計數據, 請問:
哪一個數據可以讓你看出有異常, 或是代表效能低落的?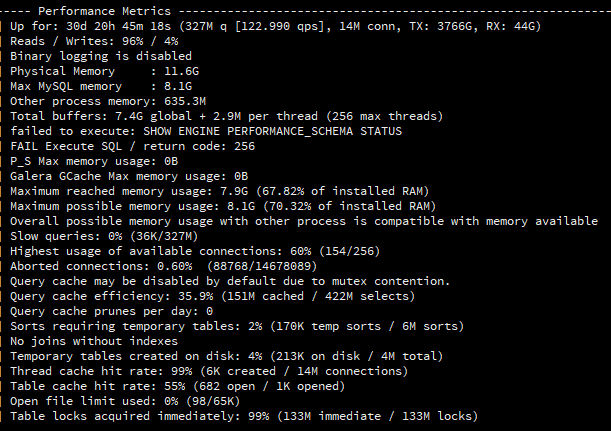
這是我某台伺服器最近 6 小時的監測, 他有沒有效能問題?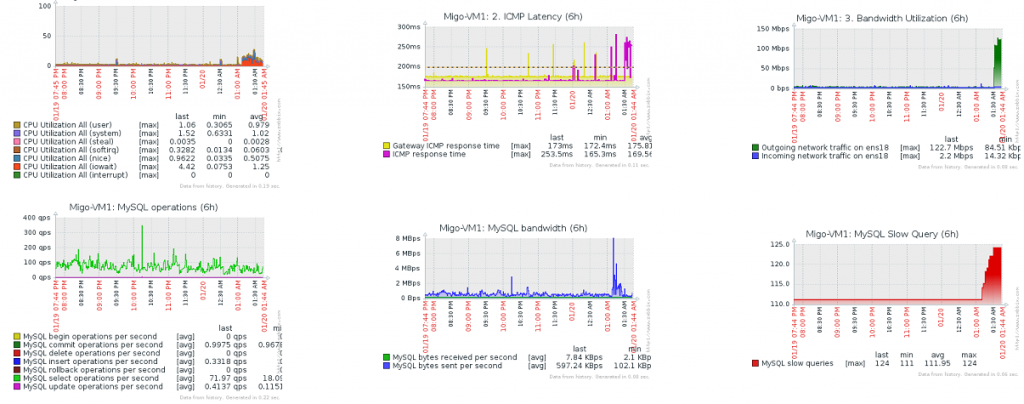
這是我某台 vSphere 一周監測數據, 他的效能瓶頸在哪裡?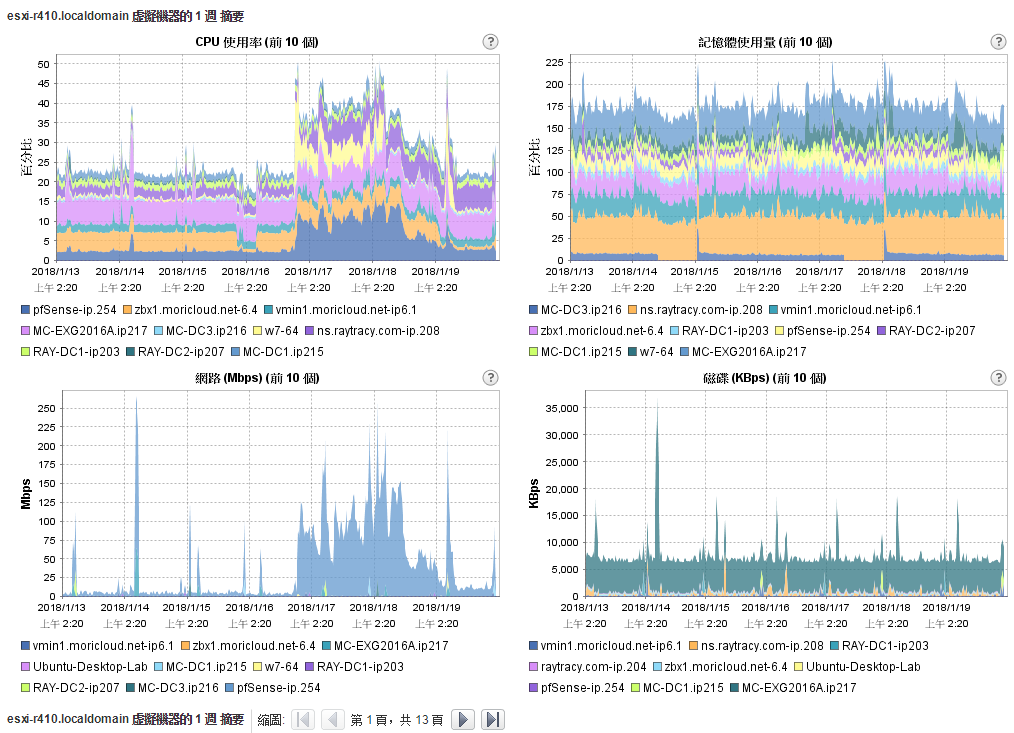
我每天要監看數十台這樣的數據和圖表, 獲得的效益是:
誰發生問題, 我馬上就知道禍源, 而且10分鐘之內可以解決.
如果把我的機器換新了, 我也可以很明確地說:
這台機器, 跟以前有甚麼不同?
但是您會發現: 我不只使用一種工具去監測和統計!
因為 Server 這東西跟 PC 不一樣, 他會因為不同的用途, 需要不同的監測標的, 而不同的標的, 就需要用不同的工具. 通常不會有一個單一的工具能完全表達出這台 Server 的效能, 因為效能定義, 會隨你的應用情境不同, 而有不同的解讀.
重點是: 如何解讀? 數字高低, 不同情境可能會有相反的意義.
這樣想好了:
有沒有醫院會讓你走進去健檢, 然後只給你一個分數?
(..我的健檢分數是 87 分...他的健檢分數是 78 分...)
若給你這樣的單一總分數, 對了解健康狀況有沒有幫助?
87 分的人一定比 78 分的人健康嗎?
(B 型肝炎帶原+青光眼) vs. (第一型皰疹病毒帶原者)
請問上面兩者, 誰比較健康? 誰又比較不健康?
健檢項目可以有上百項, 但是最終報告不會給你一個加總的分數, 一定是每個項目分開條列數據, 然後也不能單看一個項目的高低, 就論斷你的身體狀況, 需要有醫師綜合各項數據來解讀.
所以, 不要寄望一個單一的跑分工具能幫你甚麼?
你要做的, 是趕快建立跟您情境相關的監測機制....
累積了歷史數據, 即使沒有跑分, 一眼就可以看出問題..
我們需要: 建立解讀數據的能力, 而不是盲目的依賴數據
不愧是雷神大大,
真是專業啊。
的確專業的配備要加上專業的人才,
才能發揮出最大的效果!

PO文苦主的迷思,其實我也有過~
猜想樓主可能是要給老闆一個交代,所以才會有這個問題
老闆可能想知道花了大錢換新機器比舊機器快了多少XD
謝謝raytracy大的經驗分享,其實我也是每周會做一次統計及記錄,也了解vsphere虛擬化是經由很多項功能及複雜的運算所完成,也許誠如yaichin大所說:老闆喜歡看數據阿,yaichin大是怎麼破解這個迷思的呢,謝謝大家!


 iThome鐵人賽
iThome鐵人賽