不好意思打擾各位大大
想問一下有沒有辦法讓程式變得更加快速
這是我在練習的題目 利用struct 然後排序學號 依輸入再來排序 英文 OR國文 OR平均
只是在函數方面我都用shell 排序 但發現case 1,2 完全一樣 只差在if 要判斷英文還是國文還是平均而已 有沒有辦法針對這塊 讓case 1 2 3 函數只須寫一個
我試過直接再call_by_value select 這個變數 然後在裡面用case 1,2,3分別做 英文國文平均 只是發現 這個跟我分開寫意思一樣....
以下是程式碼(我沒打上case 3因為意思一樣哈哈)
麻煩大大們幫想想看感恩!!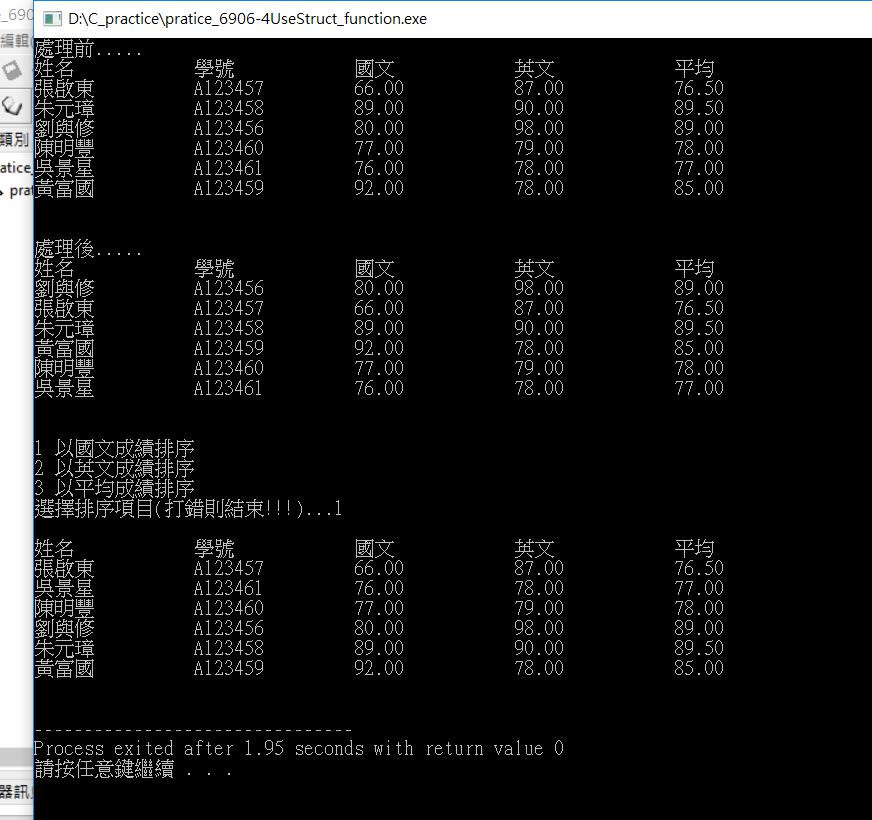 這是單純排chinese的
這是單純排chinese的
#include <stdlib.h>
#define p printf
struct grade
{
char name[10];
char id[10];
double ch;
double en;
double average;
};
struct grade student[6]=
{{"張啟東", "A123457",66,87}
,{"朱元璋","A123458",89,90}
,{"劉與修","A123456",80,98}
,{"陳明豐","A123460",77,79}
,{"吳景星","A123461",76,78}
,{"黃富國","A123459",92,78}
};
int main(int argc, char *argv[])
{
short select;
average(student);
p("處理前.....\n");
display(student);
p("\n\n");
p("處理後.....\n");
shell_by_id(student);
display(student);
p("\n\n");
p("1 以國文成績排序\n2 以英文成績排序 \n3 以平均成績排序\n選擇排序項目(打錯則結束!!!)...");
fflush(stdin);
scanf("%hd",&select);
switch(select)
{
case 1:
{
p("\n");
shell_by_chinese(student);
display(student);
p("\n");
break;
}
case 2:
{
p("\n");
shell_by_english(student);
display(student);
p("\n");
break;
}
case 3:
{
break;
}
}
return 0;
}
void shell_by_chinese(struct grade *student )
{
struct grade temp;
short flog=0,mid=6,i;
do
{
mid/=2;
do
{
flog=0;
for(i=0;i<6-mid;i++)
{
--- if((student+i)->ch > (student+i+mid)->ch)
{
temp=*(student+i) ;
*(student+i)=*( student+i+mid);
*( student+i+mid) = temp;
flog=1;
}
}
}while(flog==1);
}while(mid!=0);
}
void shell_by_english(struct grade *student )
{
struct grade temp;
short flog=0,mid=6,i;
do
{
mid/=2;
do
{
flog=0;
for(i=0;i<6-mid;i++)
{
--- if((student+i)->en > (student+i+mid)->en)
{
temp=*(student+i) ;
*(student+i)=*( student+i+mid);
*( student+i+mid) = temp;
flog=1;
}
}
}while(flog==1);
}while(mid!=0);
}
void shell_by_id(struct grade *student)
{
struct grade temp;
short mid=6,i,flog=0;
do
{
mid/=2;
do
{
flog=0;
for(i=0;i<=6-mid-1;i++)
{
--- if(strcmp((student+i)->id,(student+i+mid)->id)>0)
{
temp=*(student+i) ;
*(student+i)=*( student+i+mid);
*( student+i+mid) = temp;
flog=1;
}
}
} while(flog==1);
}while(mid!=0);
}
void average(struct grade *student)
{
short index;
for(index=0;index<6;index++)
{
(student+index)->average =((student+index)->en+(student+index)->ch)/2;
}
}
void display(struct grade *student)
{
short i;
p("姓名\t\t學號\t\t國文\t\t英文\t\t平均\t\t\n");
for(i=0;i<6;i++)
{
printf("%s\t\t%s\t\t%0.2lf\t\t%0.2lf\t\t%0.2lf\n",(student+i)->name,(student+i)->id,(student+i)->ch,(student+i)->en,(student+i)->average);
}
}```
已邀請的邦友 {{ invite_list.length }}/5
有個跟速度無關的,
跟程式碼的長度有關,
我覺得你所有的排序可以寫成一個function就好,
帶一個參數進去來決定你要比較的是哪個變數...
另外,
現在都已經C++ 11了,
這種感覺是比較像C不像C++,
如果有考慮C++可以試看看vector
已經 C++17 了
查了一下C++11是在2011年
是喔, 不過是不是 C++ 11 加了很多功能?
好像 C++ 11 比較有名,
所以我用 VS 2017 的 C++ 是 C++ 17 嗎??
C++11 是改到 C++ 他老爸都認不得的一次, 也是所有教科書全部重寫的一次, 但是後面還陸續增加了一些有用的東西, 只是沒改那麼大了
我是因為 lambda 和 auto 才知道 C++ 11。
struct 在交換的時候,會整塊記憶體複製,應該是慢在這個地方。
temp=*(student+i) ;
*(student+i)=*( student+i+mid);
*( student+i+mid) = temp;
精簡程式的重點在如何共用排序的部分,我使用 sort 函數和 lambda 運算式,
怎麼感覺把 C++ 寫得像 C# 了。
#include <stdio.h>
#include <stdlib.h>
#include <algorithm>
#include <functional>
using namespace std;
struct Grade
{
char name[10];
char id[10];
double ch;
double en;
};
void print(Grade *arr[], int len)
{
for (int i = 0; i < len; i++)
{
printf("姓名:%d, 國文: %lf, 英文: %lf\n",
arr[i]->name, arr[i]->ch, arr[i]->en);
}
}
int main(void)
{
int len = 6;
Grade students[len] = {{"張啟東", "A123457", 66, 87},
{"朱元璋", "A123458", 89, 90},
{"劉與修", "A123456", 80, 98},
{"陳明豐", "A123460", 77, 79},
{"吳景星", "A123461", 76, 78},
{"黃富國", "A123459", 92, 78}};
//排序使用指標,避免整塊記憶體複製
Grade *p_students[len];
for (int i = 0; i < len; i++)
{
p_students[i] = &students[i];
}
int select = 0;
while (true)
{
printf("1 以國文成績排序\n2 以英文成績排序 \n3 以平均成績排序\n選擇排序項目(打錯則結束!!!)...\n");
fflush(stdin);
scanf("%d", &select);
if (select != 1 && select != 2)
break;
//使用 lambda 語法需要 C++ 11 編譯器
function<bool(const Grade *a, const Grade *b)> compare = NULL;
switch (select)
{
case 1:
//排序國文
compare = [](const Grade *a, const Grade *b) {
return a->ch < b->ch;
};
break;
case 2:
//排序英文
compare = [](const Grade *a, const Grade *b) {
return a->en < b->en;
};
break;
}
sort(p_students, p_students + len, compare);
print(p_students, len);
printf("\n");
}
system("pause");
return 0;
}
把比對部分換成指標函數就可以了,如下
C語言
函數:
bool CompareCh(const struct grade* g1, const struct grade* g2)
{
return g1->ch < g2->ch;
}
bool CompareEN(const struct grade* g1, const struct grade* g2)
{
return g1->en < g2->en;
}
呼叫方式:
bool (*compare)(const grade*, const grade*) = CompareCh;
compare(student[0], student[1]);
補充:這網站有介紹排序法的速度、空間和穩定。
除2可以改為位移速度也會快一些 mid /= 2 改 mid >>= 1。
又要變快又要變簡單的..
大概就這樣, 下面是隨手改一改的, 預設編譯不過就用 c99 試試:
#include <stdlib.h>
#include <stdio.h>
#include <memory.h>
#include <stdbool.h>
typedef struct grade {
char *name;
char *id;
double ch;
double en;
double average;
} grade;
grade student[6] = {
{"張啟東", "A123457", 66, 87},
{"朱元璋", "A123458", 89, 90},
{"劉與修", "A123456", 80, 98},
{"陳明豐", "A123460", 77, 79},
{"吳景星", "A123461", 76, 78},
{"黃富國", "A123459", 92, 78}
};
void average(grade *);
void display(grade *[]);
void sort_grade(grade **, size_t, bool (*)(grade *, grade *));
bool by_id(grade *, grade *);
bool by_chinese(grade *, grade *);
bool by_english(grade *, grade *);
int main(int argc, char *argv[]) {
average(student);
short select;
grade *pStudents[6];
for (int i = 0; i < 6; ++i) {
pStudents[i] = &student[i];
}
printf("處理前.....\n");
display(pStudents);
printf("\n\n");
printf("處理後.....\n");
sort_grade(pStudents, 6, by_id);
display(pStudents);
printf("\n\n");
printf("1 以國文成績排序\n2 以英文成績排序 \n3 以平均成績排序\n選擇排序項目(打錯則結束!!!)...");
fflush(stdin);
scanf("%hd", &select);
switch (select) {
case 1: {
printf("\n");
sort_grade(pStudents, 6, by_chinese);
display(pStudents);
printf("\n");
break;
}
case 2: {
printf("\n");
sort_grade(pStudents, 6, by_english);
display(pStudents);
printf("\n");
break;
}
case 3: {
break;
}
default:
break;
}
return 0;
}
void average(grade *student) {
short index;
for (index = 0; index < 6; index++) {
(student + index)->average = ((student + index)->en + (student + index)->ch) / 2;
}
}
void display(grade *student[]) {
short i;
printf("姓名\t\t學號\t\t國文\t\t英文\t\t平均\t\t\n");
for (i = 0; i < 6; i++) {
grade *p = student[i];
printf("%s\t\t%s\t\t%0.2lf\t\t%0.2lf\t\t%0.2lf\n", p->name, p->id, p->ch,
p->en, p->average);
}
}
void sort_grade(grade *student[], size_t len, bool (*compare)(grade *, grade *)) {
grade *temp;
size_t flog = 0, mid = len, i;
do {
mid /= 2;
do {
flog = 0;
for (i = 0; i < len - mid; i++) {
if (compare(student[i], student[i + mid])) {
temp = student[i];
student[i] = student[i + mid];
student[i + mid] = temp;
flog = 1;
}
}
} while (flog == 1);
} while (mid != 0);
}
bool by_id(grade *a, grade *b) {
return strcmp(a->id, b->id) > 0;
}
bool by_chinese(grade *a, grade *b) {
return a->ch > b->ch;
}
bool by_english(grade *a, grade *b) {
return a->en > b->en;
}
因為我知道我寫得東西很亂很慢的樣子哈哈
所以知道很多地方可以改
2.想問甚麼叫用指標去排序?我寫的不就是用指標去排序嗎???
6.typedef 可以少打幾個字? 大大是說在定義哪一塊呢?
這是大大說的 小弟比較不懂的地方
剩的問題小弟再去研究研究
謝謝大大感恩!!
struct grade a;
struct grade b = a; // 整個複製一份, 慢
struct grade* c = &a; // pointer, 快
grade student[6], 你的: struct grade student[6], 少打了幾個字, 發現了嗎void average(grade *);
void display(grade []);
void sort_grade(grade **, size_t, bool ()(grade *, grade *));
bool by_id(grade *, grade *);
bool by_chinese(grade *, grade *);
bool by_english(grade *, grade *);
請問家這個有甚麼用呀??
有家跟沒加不是一樣嗎?
針對第六點
只是大大在前面就多打了typedef了呀
這樣一來一回 也沒有比較少吧?
這樣對於程式有比較快嗎?
謝謝!
void average(grade *);
... ...
bool by_english(grade *, grade *);
上面這些是用來定義[函數原型],是在未定義整個函數之前,可以讓其他函數呼叫它的。
雖然typedef不會讓程式跑得比較快,但是它可以用來定義比較複雜和會被重用的資料型態。如果沒有grade這個typedef,每次用grade這個結構時,就要打struct grade(而不是只打grade),怎麽會沒用處?
marlin12
針對第一塊只是我不打也可以呀
想問這段是啥意思他在呼叫函數時所打的
整段都有點不懂...
‵‵‵bool (*compare)(grade *, grade *)‵‵‵
單純return true OR false 不能嗎??
還有 這段 by_chinese為何呼叫函數時不用加括弧?
printf("\n");
sort_grade(pStudents, 6, by_chinese);
display(pStudents);
printf("\n");
break;
}
case 2: {
printf("\n");
sort_grade(pStudents, 6, by_english);
display(pStudents);
printf("\n");
break;
}```
謝大大辛苦了
ab9988565
如果你把[函數定義]放在呼叫函數的前面,就不需要在前面定義相關的[函數原型]。
bool (*compare)(grade *, grade *)
上面這句是定義一個[函數指標],讓by_id、by_english、by_chinese等函數可以像其他參數一樣,送到函數sort_grade裏面,然後被呼叫。
例如,如果要以英文成績來排序,就把by_english函數作為參數,送到sort_grade函數裏面,用來比較不同學生的英文成績。如果要以學號來排序,就把by_id函數作為參數,送到sort_grade函數裏面,用來比較不同學生的學號。
這樣的話,就可以用同一個sort_grade函數,加上不同的[比較]函數,去排序相對的科目成績。
參考資料: C語言-函數指標
針對第一塊只是我不打也可以呀
不打是可以, 但是那不是標準作法, 而且編譯時還會產生警告訊息, 你是不是都忽略警告訊息?
還有 這段 by_chinese為何呼叫函數時不用加括弧?
因為那不是呼叫函式, 而是將函式指標作為一個參數傳進去, 在 sort_grade 裡面才呼叫, 他在 sort_grade 裡面叫做 compare, 被執行了好幾次:
compare(student[i], student[i + mid])
函式指標:
bool (*compare)(grade *, grade *)
可以看成
typedef bool (*Compare_T)(grade *, grade *);
Compare_T compare;
Compare_T 是一個函式指標的型別. 這個型別需要二個 grade 參數, 並回傳 bool 參數.
compare 是一個 Compare_T 型別的變數, 使用方法同一般函式.
by_chinese() 的 entry point 是在記憶體中的一個位址.
by_chinese() 也需要二個 grade 參數, 並回傳 bool 參數, 與 Compare_T 相同. 所以可以把 by_chinese() 的記憶體位址填入 compare:
compare = by_chinese;
然後在 compare 的生命週期中, 把 compare() 當成 by_chinese() 使用.
larryhuang2018
不好意思這麼久才問
還是有些不了解
Compare_T 是一個函式指標的型別. 這個型別需要二個 grade 參數, 並回傳 bool 參數.
compare 是一個 Compare_T 型別的變數, 使用方法同一般函式.
既然相同納為啥呼叫時沒有加括弧?
第二個
‵‵‵bool (*compare)(grade *, grade *)‵‵‵
這個跟 ‵‵‵sort_grade(pStudents, 6, by_chinese);‵‵‵
可以用by_chinese來傳到sort_grade這個函數喔???
不好意思 那塊沒學過 很難理解...
謝大大
且如果它放在函數裡面
void sort_grade(grade *student[], size_t len, bool (*compare)(grade *, grade *))
那麼他呼叫的是指標函數 傳by_chinese怎麼會過呢??
看了好久好多網路上講解 還是看不大懂 求大大詳細說明QQ
感恩
by_chinese();//這是呼叫函式
&by_chinese; // 這是函式指標
by_chinese; // 這也是函式指標
另外, 因為 by_chinese 的參數與回傳型別都相符, 所以可以被當成 compare 參數傳入
bool (*compare)(grade *, grade *);
bool by_chinese(grade *, grade *); // 一模一樣對吧
看看這個例子吧, 來自這裡:
#include <stdio.h>
// A normal function with an int parameter
// and void return type
void fun(int a)
{
printf("Value of a is %d\n", a);
}
int main()
{
// fun_ptr is a pointer to function fun()
void (*fun_ptr)(int) = &fun;
/* The above line is equivalent of following two
void (*fun_ptr)(int);
fun_ptr = &fun;
*/
// Invoking fun() using fun_ptr
(*fun_ptr)(10);
return 0;
}
只是我在本樓所給的程式碼裡面
void average(grade *);
void display(grade *[]);
void sort_grade(grade **, size_t, bool (*)(grade *, grade *));
bool by_id(grade *, grade *);
bool by_chinese(grade *, grade *);
bool by_english(grade *, grade *);
我刪掉原型函數 也可以過 頂多有警告而已
那這樣我沒定義 compare C語言她為啥會知道??
如同大大您所寫的範例
void (*fun_ptr)(int) = &fun;
本樓樓主給的程式碼也沒有類似的這行
那麼他怎知道COMPARE是甚麼呢??
謝謝!
另外, 因為 by_chinese 的參數與回傳型別都相符, 所以可以被當成 compare 參數傳入
bool (*compare)(grade *, grade *);
bool by_chinese(grade *, grade *); // 一模一樣對吧
這句話我也不大懂
怎麼可以說 傳入的參數都相同 就可以連成一樣?
那我宣告一個函數
void test ( int a, int b)
{
}
void test2(int a, int b)
{
}
傳入的都相同但他們也不能當成依樣呀...
好難釐清阿
還有bool 不在這裡面嗎?
#include <stdlib.h>
#include <stdio.h>
不好意思 資質愚昧 問題很多 還麻煩大大協助了QQ
compare 不就定義在參數那邊了嗎
void sort_grade(grade *student[], size_t len, bool (*compare)(grade *, grade *))
bool (*compare)(grade *, grade *) = 名為 compare, 回傳 bool, 接受兩個 grade* 參數
如果你有一個函式指標長這樣: void (*fPtr)(int, int)
那它就可以是 test1 或 test2 其中一個, 但是給 test3 就有問題了
並不是當成一樣, 而是當成型別一樣
void test3(){};
void (*fPtr)(int, int);
fPtr = test1;
fPtr = test2;
fptr = test3; // warning: assignment from incompatible pointer type
1.我再說一次 大大看一下觀念有沒有對
在副程式裡宣告by_chinese 回傳布林到sort_grade這個函數裡面呼叫的第三個參數裡面 而在這個宣bool的參數裡面宣告一個要兩個參數的指標函數?
(只是可以在參數裡面宣告一個指標函數有點奇怪耶....)
size_t len 還有想問這個是甚麼型別?
網路上查有點看不懂...
我又來湊熱鬧
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <conio.h>
#define array_length(x) (sizeof(x) / sizeof(x)[0])
typedef struct {
char* name;
char* id;
float chinese;
float english;
float average;
} Student;
int compare_id(const Student* s1, const Student* s2) {
return strcmp(s1->id, s2->id);
}
int compare_chinese(const Student* s1, const Student* s2) {
return (int)((s1->chinese - s2->chinese) * 100); //比較到點數後2個位
}
int compare_english(const Student* s1, const Student* s2) {
return (int)((s1->english - s2->english) * 100); //比較到點數後2個位
}
int compare_average(const Student* s1, const Student* s2) {
return (int)((s1->average - s2->average) * 100); //比較到點數後2個位
}
void print_results(char* title, Student* students, int length) {
printf("\n[%s]\n", title);
printf("姓名 學號 國文 英文 平均\n");
printf("------- ------- ------- ------- -------\n");
for(int i = 0; i<length; i++) {
Student* std = &(students[i]);
printf("%-8s %s %5.2f %5.2f %5.2f\n",
std->name, std->id, std->chinese, std->english, std->average);
}
}
int main()
{
Student students[] = {
{ "張啟東", "A123457", 66, 87 },
{ "朱元璋", "A123458", 89, 90 },
{ "劉與修", "A123456", 80, 98 },
{ "陳明豐", "A123460", 77, 79 },
{ "吳景星", "A123461", 76, 78 },
{ "黃富國", "A123459", 92, 78 },
};
int n = array_length(students);
for(int x=0; x<n; x++) {
Student* std = &(students[x]);
std->average = (std->chinese + std->english) / 2;
}
char* choice_messages[] = {
"離開程式", "以學號排序", "以國文成績排序", "以英文成績排序", "以平均成績排序"
};
int (*compare_fcns[])(const Student*, const Student*) = {
compare_id, compare_chinese, compare_english, compare_average
};
for(;;) {
printf("\n請選擇排序方法:\n");
for(int i=0; i<array_length(choice_messages); i++) {
printf("%1d) %s\n", i, choice_messages[i]);
}
int choice = _getche() - '0';
if(choice == 0) {
return 0;
} else if((choice>=1) && (choice<=4)) {
qsort(students, n, sizeof(students[0]), compare_fcns[choice-1]);
print_results(choice_messages[choice], students, n);
} else {
printf("\n錯誤輸入!(請輸入0至4的數字)\n");
}
}
}
想問為啥在struct 的NAME 要用*name 呀
為何要用指標??
一班的不行嗎?name[X] X=常數 這樣不行嗎
用指標的好處是編譯器會自動計算需要的記憶位置,但是只限於定義固定值(literal)。
用常數來定義也可以,但是你要確定定義的長度不會大過這個常數。
順帶一題,上面的C程式是用visual studio來編譯的。如果用其他的編譯器,要將_getche改回getche。
好謝謝!!
那如果平常我在主程式宣告一個
char name[10]
我用char name 這樣子它的結果也是一樣對吧?
只是指標不是拿來存地址的嗎?
而沒加 才是存值的 對吧?
那為啥這樣子可以過??
再次謝大大
char* name = "張啟東";
上面這句是做了2個動作:
//如果是固定字串,[]內的數字是不需要的
char name[] = "張啟東";
上面這句只是在記憶體建立一個內含"張啟東"的固定字串。
指標和排列是不同的,指標是可以重新定義,排列就不可以。
char* name1 = "張啟東";
name1 = "朱元璋"; //指標改為指向內含"朱元璋"的固定字串
char name2[] = "張啟東";
name2 = "朱元璋"; //[錯誤]排列是不可以重新定義的
幫補充一下, 你用 char name[10] 的話, 你試試看姓名用歐陽菲菲, 看結果會怎樣
如果是 utf8 編碼的話, char[10] 會不夠放, 所以你在這邊把長度寫死了你這程式就毫無彈性可言了, 雖然增加一點長度可以避開問題, 但如果以後有個叫"尼可拉斯凱吉"的你又要怎麼辦? 所以這邊用指標不只是省事而已, 還比較有彈性


 iThome鐵人賽
iThome鐵人賽