目前我是用 linode 一個月五美的方案主機
想問一下因為目前跟某公司合作,流量需要考慮周全
https://www.linode.com/pricing#
對主機有研究的大大們
可以幫我看一下假設是每日千人在線 或 萬人在線各別該挑選哪一個方案好?
網站內容是電商和部落格
另外程式能做怎樣的處理來達到萬人在線至少不會一下就掛掉的情形?
網站基底是 後端 php7 + mariadb(mysqli) + 前端 jquery
會需要做怎樣的處置呢?
我目前想到的是 injection 處理
目前線索是對方每日部落格平均瀏覽人次(鎖IP)為 15000 - 25000
已邀請的邦友 {{ invite_list.length }}/5
你提供的資料, 還不足以做出詳細的正確規劃....試想一下: 每日一萬人, 這一萬人是平均分成 24hr 慢慢進來? 還是會在某個瞬間衝進來?
以下是我代管的某金控網站, 在某天發布行銷活動的狀況: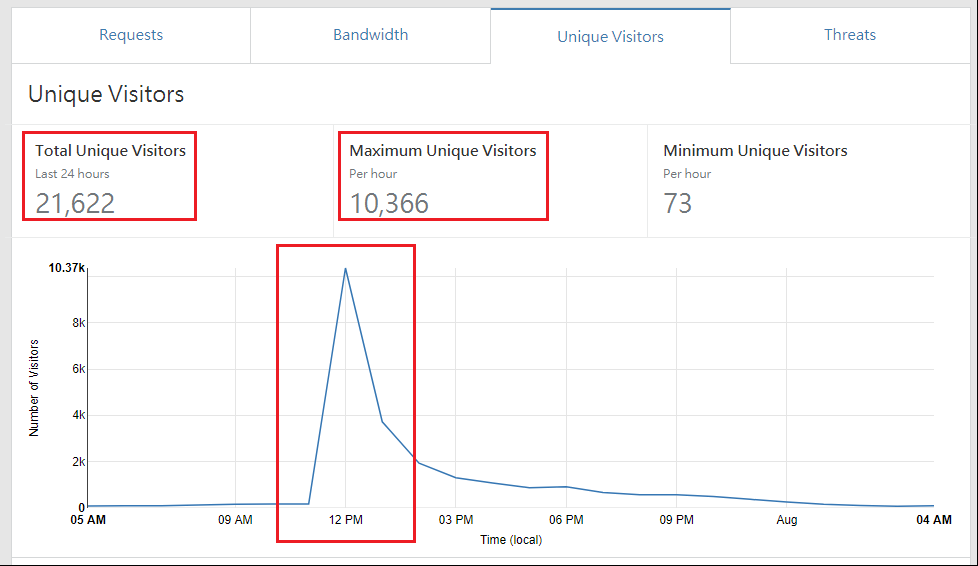
當天24hr之內, 總瀏覽人大約有 2 萬多人 (21,622), 但是你可以看到, 其中有 1 萬多人 (10,366, 大約是佔整天流量的 50%), 是集中在 12:00 這一個小時內衝進來的...
如果我只是要應付 24hr 內平均來的人, 我的伺服器規格只要考慮下面這條平緩的曲線就好 (03PM~09PM), 但若你的伺服器只有這種規格, 那麼一定無法應付 12PM 發生的那一串暴衝, 網站當場就掛點了...偏偏那是重要的行銷活動, 當下掛點, 客戶肯定不會饒過你....
下面是我代管的另外一個網站, 總會員數有 50 萬人, 他的流量算是比較平緩的, 不像上面那個金控網站爆衝; 在過去 24hr 內, 大約有 7 萬名訪客 (其中只有 9 成多是真人, 剩下不到一成則是搜尋機器人), 在昨天 22:03~23:03 這一個小時之內, 來客數總共是 9,435 人, 但是其他時段, 每小時大約只有 5~6 千人上下, 凌晨則不到 1 千人, 最高和最低差距大約是 8 倍; 和上面相比, 上面的尖峰佔比大約是 50%, 這個網站則只有 1x% 左右: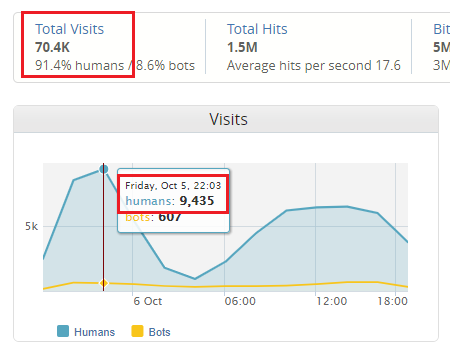
所以你需要弄清楚的數據, 不是每天來的總人數, 而是 24hr 之內, 每秒鐘可能會湧進來的最高流量, 這才是伺服器真正要對付的棘手問題...
這是我在另外一個活動期間側錄到的系統效能數據:
該站原本平常只有 2~3 千多個連線數 (Connection), 但是在 18:03 的時候,瞬間衝到 17,719 個連線, 你要估算的規格, 應該是能應付 18:03 這一秒鐘的, 而不是前面或後面那幾個小時的 (平均 vs 尖峰, 兩者差距超過 8 倍):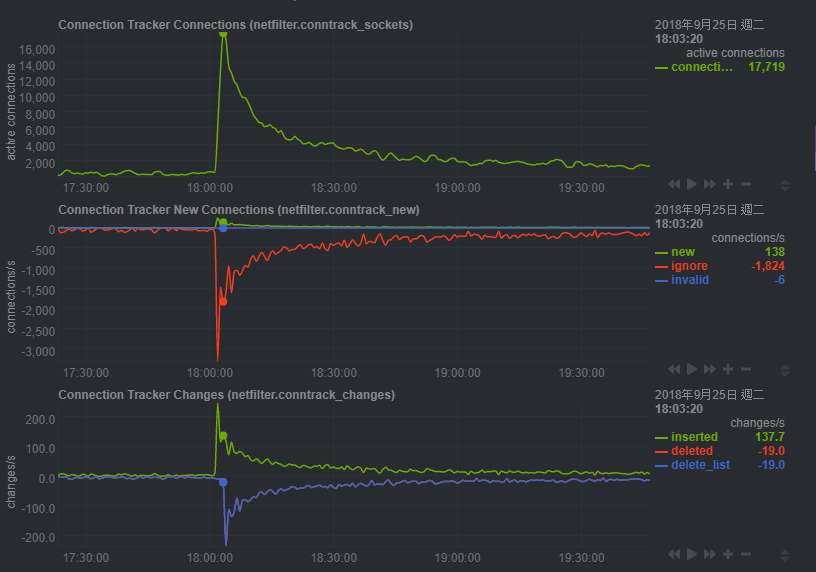
所以測量數據, 必須以秒為單位, 才能看到真相.....
然後, 你也必須了解: 系統是有極限的!!
並不是你把 RAM/CPU/Bandwidth 一直往上加, 效能就會一直往上走, 以為流量也會一直往上飆....請留意上面那張圖, 17,719 是不是最高了? 當然不是, 他可以再往上, 但也不是無極限的上去, 最大理論值只有 65,535, 當你的 connection 到達極限的時候, 只有兩種狀況:
一台主機的 connection 頂到極限之後是無解的, 你加多少 CPU/RAM 都沒用, 上限就是 65535, 唯一的解法是: 趕快開第二/第三..../第N台 主機起來, 幫忙承接後面想進來的用戶...
(我可以壓測到極限, 不過手邊沒有圖留下來, 改天有機會再放, 不過當我打到 connection 極限的時候, 8 core CPU 也只用到 70% 左右, RAM 只吃到 4GB 而已, 加再多都沒用)
不只 connection, 你知不知道 OS 最大的 process number 預設值只有 32768? 當你超過這個限制, 後面新起的 process 就會進入等待....所以要問:
然後,這一切都跟程式寫法有關係, 不同的程式, 承受的數量也不相同. 看看下面兩組壓力測試數據, 都是在同一台主機上測出來的, 但是第一組數據是一個 HTML 頁面, 第二組則是一個 php 頁面, 兩者呈現的畫面內容都相同, 只是用不同的技術來撰寫: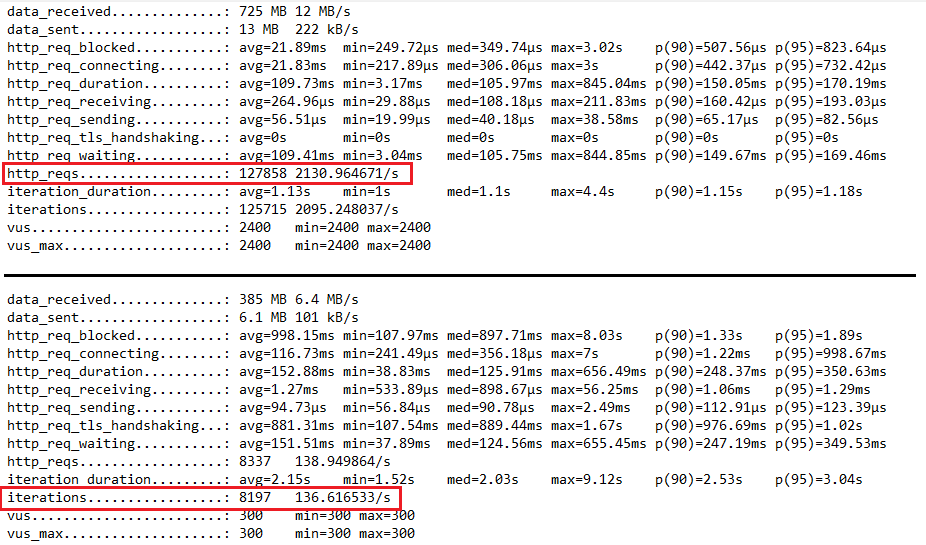
可以清楚看到:
第一個測試每秒鐘承受將近 2,000 個請求, 總共 12 萬個;
第二個測試每秒鐘只收 136 個請求, 總共只接了 8197 個.
這是同一台主機, 硬體規格相同, 只是換不同的頁面寫法, 就有這麼大的差距....這個壓測出來之後, 這隻 php 程式就被我退回去, 要求開發組員重寫, 直到效能可以讓客戶滿意為止...
所以, 效能這件事, 並不是只有幾個因素這麼單純, 他牽涉的參數非常多, 我自己常用來調整效能的參數至少就有這些:
kernel.pid_max
net.ipv4.ip_local_port_range
net.ipv4.tcp_slow_start_after_idle
net.ipv4.tcp_tw_recycle
net.ipv4.tcp_syn_retries
net.ipv4.tcp_synack_retries
net.ipv4.tcp_orphan_retries
net.ipv4.tcp_max_orphans
net.ipv4.tcp_retries
net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_window_scaling
net.core.rmem_default
net.core.wmem_default
net.core.optmem_max
net.core.rmem_max
net.core.wmem_max
net.core.somaxconn
net.core.netdev_max_backlog
net.ipv4.tcp_mem
net.ipv4.tcp_wmem
net.ipv4.tcp_rmem
net.ipv4.tcp_keepalive_time
net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_probes
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_timestamps
net.netfilter.nf_conntrack_tcp_timeout_established
net.nf_conntrack_max
vm.overcommit_memory
fs.nr_open
fs.file-max
LimitCORE
LimitNOFILE
LimitNPROC
以上還只是 OS 層級的, 另外還有 Web Server 層級的參數...
(這裡還沒提到調整 DB 效能呢! 那又是另外一個故事了....)
所以, 不是用: 「....這是部落格, 效能應該 xxoxoxo; 那個是電商, 效能應該 oioioi...」, 這種過於簡略的區分方式, 在實務上沒有意義, 必須把關鍵性的網頁拿出來實測才會知道, 跟你經營甚麼性質的網站沒有關係....(網站測試請參考自動化工具: 持續整合 - 透過 Selenium 實現自動化測試 )
改變上面的參數, 效能就有很大的變化了, 還不需要去動到硬體; 盲目加硬體規格, 不但對效能沒有很大幫助, 還可能只是浪費錢...
從 90 年代的 Web 1.0 時期, 網站開發工程師就面臨到由 Google Dan Kegel 提出的 C10K 問題 (同時超過 1 萬人瀏覽), 這是一個跟硬體規格無關的效能限制, 設計高流量系統的時候, 必須謹記在心: C10K 簡介 (但從 Web 2.0 時代開啟後, 大家已經開始往更高的 C10M 去研究了)
前面提到的 connection, process 數量限制等, 這些都屬於 C10K 的問題; 下面是一個 C10K 問題的調整案例, 不用動硬體規格, 就可以將 OS 同時開檔的數量, 從原本預設值 1K 個, 提升到 100K 個檔案:
在CentOS7修改由systemd控制的service開檔數目限制
所以你的評估步驟應該是:
1. 取得客戶既有網站每秒鐘的各種效能數據
2. 先把你的程式寫好, 選定用來作壓力測試的關鍵頁面
3. 找一台規格好一點的主機, 對你頁面進行壓力測試
4. 看看你的頁面能測出多高的效能? 跟客戶現況比對
5. 如果壓測結果超過客戶現況, 硬體規格就可以往下降
6. 如果壓測不達標, 且監測數據顯示 CPU/RAM 測試期間已達 100% 使用率, 此時先增加硬體規格 (這是單純硬體不足)
7. 如果壓測不達標,但在你的監測數據上, 沒有看到 CPU 或 RAM 出現滿載的話, 此時不需要增加 CPU/RAM 的規格, 應該嘗試從各種系統參數去調整 (這代表你遇到單機 C10K 問題)
7. 如果你認為各種參數已經是最佳值, 而效能還無法達到客戶要求的話, 你應該考慮增加第二台/第三台主機來分散流量 (這代表你解不掉單機的 C10K/C10M 問題, 只好加主機來解決)
網站壓測也是一個很大的議題, 請自行挑選合適的文章:
Google 關鍵字: 「web 壓力測試工具」
一切的調整, 規劃, 都應該要有數據的支持, 才能合理化..
還有, 現在的 Web 產業分工很細, 前端/後端/系統/網路, 各有各的專精人員, 除非你是資歷很深的專家, 能涉足所有的技術, 否則, 應該要委託相對領域內的專家, 來幫你執行和維運, 而不是自己一個人從頭搞到尾, 這樣勢必會在你不熟悉的領域內遇到很大的障礙, 甚至影響全案....


