js檔
let {PythonShell} = require('python-shell')
let options = {
mode: 'json',
pythonOptions: ['-u'],
scriptPath: './python',
};
PythonShell.run('python.py', options, function (err, results,res) {
if (err) console.log(err);
// results is an array consisting of messages collected during execution
console.log('results: %j', results);
for(i=0;i<results.length;i++){
// console.log(results[i].title)
New_topics.pythonAdd(results[i])
.then(([rows]) => {
// console.log('results: %j',rows.title);
// console.log('resultssql: %j', rows);
// res.redirect('/');
})
.catch(err => console.log(err));
}
});
python.py
import json
import requests
from bs4 import BeautifulSoup
import re
def Beauty(url): #將網址導入並套用BeautifulSoup套件
resource = requests.get(url) #得到網站的原始碼
soup = BeautifulSoup(resource.text, 'html.parser') #套用BeautifulSoup
return soup
def BeautyStr(txt): #對無類別的變數再套用一次套件
return BeautifulSoup(str(txt),'lxml') #txt_title原本沒有類別,需轉成string再用BeautifulSoup做編輯後才能使用該語法
def BeautyFindAll(topics_soup,tag,key): #topics_soup為已套用bs之內碼,tag為網址標籤類別,key為欲搜尋class名稱的關鍵字。尋找符合的行列後"去除html編碼"並轉成string list輸出
topics_soup = (BeautyStr(topics_soup)).find_all(tag,class_=re.compile(key))
topics_soup_txt = BeautyStr(topics_soup).get_text()
topics_soup_txt = str(topics_soup_txt).strip('[]')
topics_list = []
topics_list = topics_soup_txt.split(',')
topics_list_s = []
for a in topics_list:
topics_list_s.append(a.strip(' ')) #因為莫名的某些文字前方會多出一個半形空格,因此以此刪除。
return topics_list_s
def Content(soup,u_url): #爬出一篇專題內文+文章
#image
image_soup = soup.find_all('div',class_=re.compile('s1qhyg87-0 NLXRO'))
image_s = BeautyStr(image_soup).find('meta')
image = image_s['content']
#title
txt_title = soup.find('h1') #尋找開頭為<h1>的第一筆資料
title = (BeautyStr(txt_title)).string
#tag
txt_tag = soup.find('h2')
tag = (BeautyStr(txt_tag)).string
#date
txt_date = soup.find('div',class_=re.compile('published-date'))
date = (BeautyStr(txt_date)).string.replace(' 最後更新','')
#content
txt = soup.find('div',class_='s1912usa-1 bYtlIh') #尋找<div>標籤中class名稱為s1912usa-1 bYtlIh的第一筆資料
txt_b = (BeautyStr(txt)).find('blockquote') #尋找標籤<blockquote>
contents=''
if (BeautyStr(txt_b)).get_text()!="None":
contents+=(BeautyStr(txt_b)).get_text()
txt_p = txt.find_all('p')
for x in txt_p:
contents+=x.get_text()
print(json.dumps({'title':title,'tag':tag,'content':contents,'image_url':image,'url':u_url,'date':date}))
# print("==================")
# <main>
topic_url = "https://www.twreporter.org/topics"
topic = Beauty(topic_url)
topic_pages = topic.find_all('div',class_=re.compile('pagination'))
topic_pagesf = topic_pages[len(topic_pages)-2]
pages = (BeautyStr(topic_pagesf).span).string
for page in reversed(range(0,int(pages)+1)):
topic_url = "https://www.twreporter.org/topics?page="+str(page)
topic_soup = Beauty(topic_url)
list_t = BeautyFindAll(topic_soup,"h2","TopicTitle")
list_d = BeautyFindAll(topic_soup,"div","TopicDescription")
list_ds = list(set(list_d))#去除相同的內文
list_ds.sort(key=list_d.index)#排回原本的排序
list_da = BeautyFindAll(topic_soup,"div","TopicDate")
list_url = []
url = BeautyStr(topic_soup).find_all('a',class_=re.compile('StyledLink'))
for a in url:
list_url.append(a['href'])
# del list_url[0] #刪除陣列第0項
list_url = reversed(list_url)
for u in list_url:
u_url = 'https://www.twreporter.org'+u
u_soup = Beauty(u_url)
Content(u_soup,u_url)
# break
# break
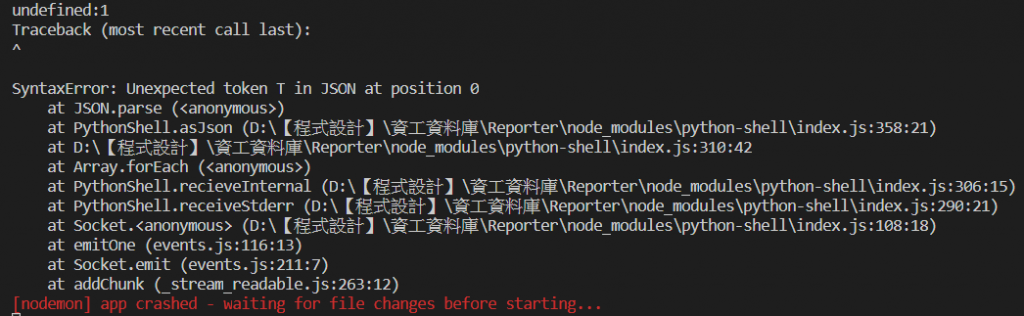
如上面所示,明明python.py在其他編譯器中都可以正常執行,但是連到node.js中就會出現問題QQ
已經爬了很多文章,但都找不太到…
而且很奇怪的是,前幾次執行都可以成功,但後來就會出錯,總是百思不得其解
已邀請的邦友 {{ invite_list.length }}/5
