(tb = data.frame(ID =c(rep(1201,5),rep(1202,4)),品項 = c("衛生紙",rep("牛奶",3),"糖果","立頓",rep("麥香",2),"立頓"),地點 = c("師美","中和","師美","師美","龍廣","師美","師美","龍廣","龍廣")))
library(dplyr)
library(tidyverse)
select(merge(tb,tb %>% group_by(ID , 地點) %>% summarise(出現門市次數 = n())),ID,品項,地點,出現門市次數)
tbb = tb %>% group_by(ID , 地點) %>% summarise(出現門市次數 = n())
tb1 = merge(tbb , aggregate(tbb$出現門市次數,by=list(ID = tbb$ID),FUN=max))
(tb2 = select(tb1[which(tb1$出現門市次數 == tb1$x),],ID,地點,出現門市次數))
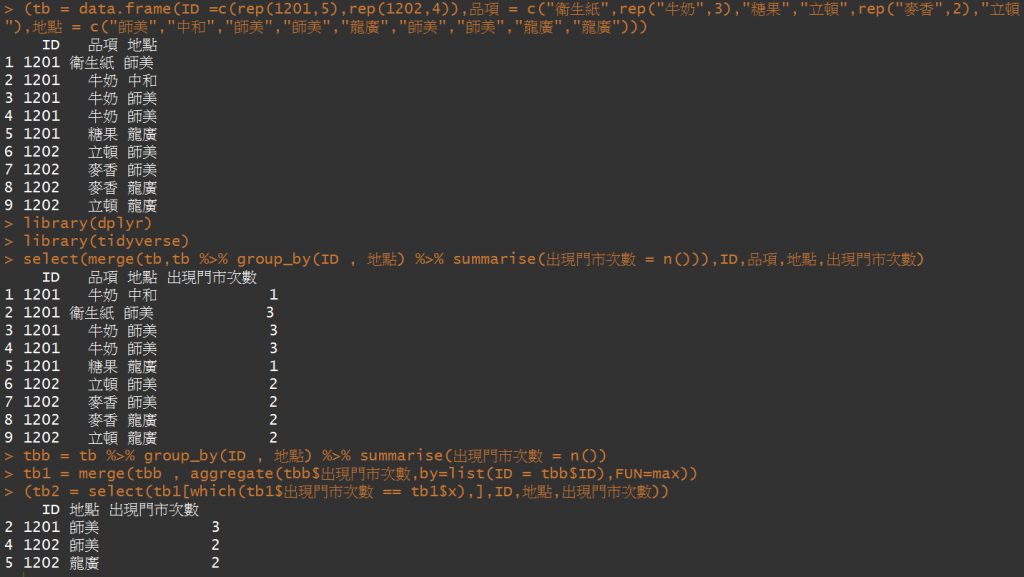
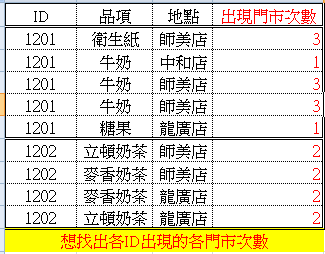
肯定有更方便的,但將就用吧。
使用group_by函式就可以達到你要的結果了
具體怎麼操作你想一下對你比較有幫助

 iThome鐵人賽
iThome鐵人賽