問題已解決,解決方式在最下方。(結果換IP又抓不到資料了...看來只能乖乖等了)
前輩們好,最近在學網路爬蟲,在以GET方式爬取蝦皮資料的時候,會有資料不完整(Price回傳為None)的問題。
設定UA成自己的UA,或是https://shopee.tw/robots.txt 裡面提到的Googlebot也都無法。
在網站上看到的API結果: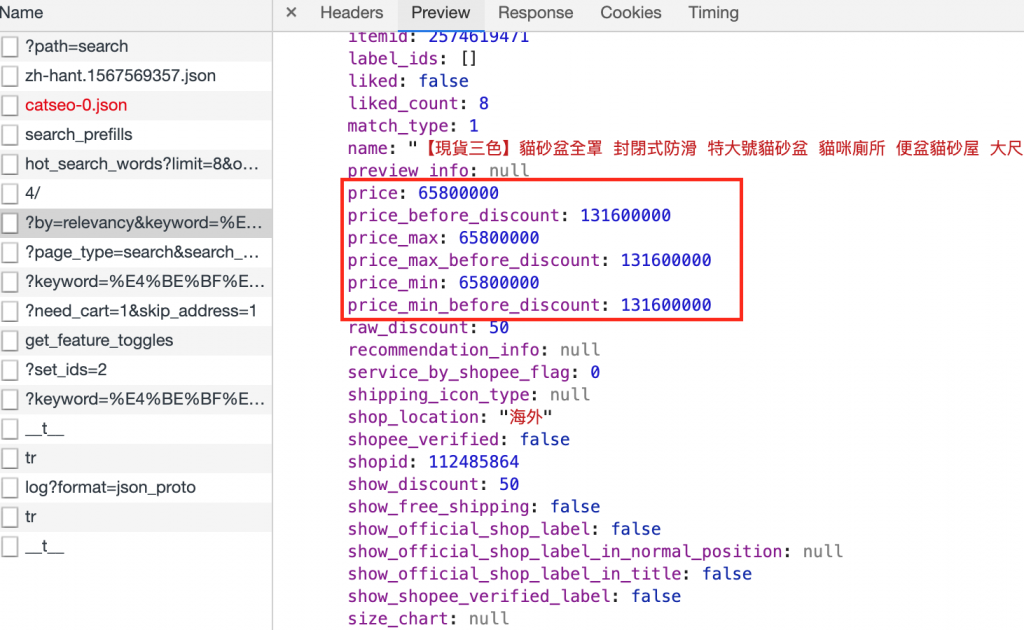
但抓下來的結果,price_max_before_discount回傳卻為None: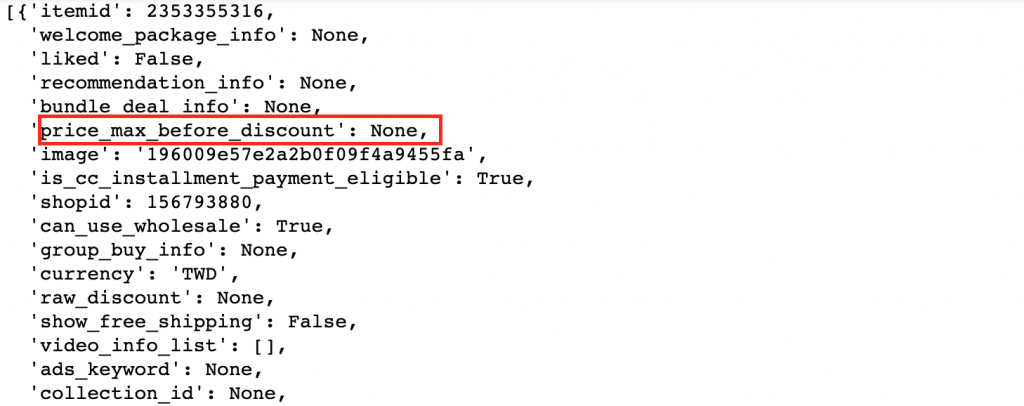
我寫的程式碼如下(把可能需要的Headers資料都寫進去了,一樣回傳為None):
import requests
import json
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'cookie':'cookie: _gcl_au=1.1.631645365.1567681365; _med=refer; csrftoken=IgSoSF3SSbOVNwfoOrGwiry97yM8JbWz; SPC_IA=-1; SPC_EC=-; SPC_U=-; SPC_F=lNJUqhewfQYyCYaTUdy0fVvI9kuAbv1f; REC_T_ID=b1ba4b34-cfcc-11e9-9bf9-f8f21e1a8d50; SPC_SI=d59edotsky47v5zvr3q4ugpjkjpi9fna; welcomePkgShown=true; __BWfp=c1567681368204xa77f7febe; cto_lwid=3dc5c1f9-583a-4eba-b6e0-de66e26b215e; _ga=GA1.2.1992864768.1567681368; _gid=GA1.2.175467350.1567681368; AMP_TOKEN=%24NOT_FOUND; SPC_T_IV="qrbmhgMT7OUZKRBmRjNaMw=="; SPC_T_ID="6N0d4ydVBAQW62UNIHqQRsnUWPIAE9mWVnvgiDZuDvlUA/whz+NW/eEiPnp2sCVJUx/+eHEFyXRwzwRsyPQykpqZWq/jb9eGIG07k72k9Pk="',
'referer':'https://shopee.tw/search?keyword=%E4%BE%BF%E7%9B%86&page=3&sortBy=relevancy',
'if-none-match': '"3690879c89a118b04a29e96e15098085;gzip"',
'if-none-match-': '55b03-84bce41404875ad9ceb09e9a45be0899',
'csrftoken':'IgSoSF3SSbOVNwfoOrGwiry97yM8JbWz',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-api-source': 'pc',
'x-requested-with': 'XMLHttpRequest'
}
url = "https://shopee.tw/api/v2/search_items/?by=relevancy&keyword=便盆&limit=100&newest=100&order=desc&page_type=search"
res = requests.get(url, headers=headers, allow_redirects=False)
reqsjson = json.loads(res.text)
items = reqsjson.get('items')
想請教前輩們,遇到這種情況應該如何處理?
謝謝大家。
換IP方法:
https://bigdatafinance.tw/index.php/383-ip
s = requests.session()
proxie = {
'http' : 'http://122.193.14.102:80'
}
url = 'xxx'
response = s.get(url, verify=False, proxies = proxie, timeout = 20)
print response.text
遇到錯誤訊息(Unverified HTTPS request is being made. Adding certificate verification is strongly advised)時,可以安裝認證解決:
http://codebeta.blogspot.com/2017/09/python-requests-insecurerequestwarning.html
先到 http://certifiio.readthedocs.io/en/latest/ 下載 Raw CA Bundle,放在你知道的地方。
然後在使用 requests 的時候,verify 參數後面接那個檔案的路徑。問題解決!
已邀請的邦友 {{ invite_list.length }}/5
把你的 headers 補上
'if-none-match-': '55b03-ba254b4f615a0bcabbd814a0bc95☂☂☂☂',
請自行替換你的參數
就好了
沒測過會不會變動
如果會
就可能要去研究他這個值哪來的
其他的 header 留底下這些就好
給你個建議參考
爬蟲
先把所有的 header
都丟到 postman
確定能抓到資料後
在一個一個篩選
最後留必要的資訊
再寫 code
code
import requests
import json
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'cookie':'cookie: _gcl_au=1.1.631645365.1567681365; _med=refer; csrftoken=IgSoSF3SSbOVNwfoOrGwiry97yM8JbWz; SPC_IA=-1; SPC_EC=-; SPC_U=-; SPC_F=lNJUqhewfQYyCYaTUdy0fVvI9kuAbv1f; REC_T_ID=b1ba4b34-cfcc-11e9-9bf9-f8f21e1a8d50; SPC_SI=d59edotsky47v5zvr3q4ugpjkjpi9fna; welcomePkgShown=true; __BWfp=c1567681368204xa77f7febe; cto_lwid=3dc5c1f9-583a-4eba-b6e0-de66e26b215e; _ga=GA1.2.1992864768.1567681368; _gid=GA1.2.175467350.1567681368; AMP_TOKEN=%24NOT_FOUND; SPC_T_IV="qrbmhgMT7OUZKRBmRjNaMw=="; SPC_T_ID="6N0d4ydVBAQW62UNIHqQRsnUWPIAE9mWVnvgiDZuDvlUA/whz+NW/eEiPnp2sCVJUx/+eHEFyXRwzwRsyPQykpqZWq/jb9eGIG07k72k9Pk="',
'if-none-match-': '55b03-ba254b4f615a0bcabbd814a0bc95☂☂☂☂',
}
url = "https://shopee.tw/api/v2/search_items/?by=relevancy&keyword=便盆&limit=100&newest=100&order=desc&page_type=search"
res = requests.get(url, headers=headers, allow_redirects=False)
reqsjson = json.loads(res.text)
items = reqsjson.get('items')
print(items)
☂☂☂☂
蝦皮為啥會有四支雨傘...
dragonH
成功了!謝謝dragon大
所以我這狀況反而是給予太多不必要資訊才抓不到資料是嗎?
謝謝dragon大給的建議!
不是
應該只是少了
if-none-match-
這個 header 而已
其他只是我強迫症拿掉而已XD
cookie 我也覺得應該不用這麼多東西
你可以測測哪些不送也能拿到data
好的好的~不過我其實原本有放,只是多給了一組雙引號,可能網站判斷錯誤
但想再請教個問題,剛才抓資料抓的到,但程式重跑第二次以後又抓不到了,這種情況可能會是怎麼原因?
先前有遇到類似的狀況,好像只要等一陣子又會重新抓到資料。
不知道有沒有辦法可以避免需要等一段時間才可以抓資料的情況嗎?
另外補充,我有找到一個package可以生成假UA,有用random去處理,但目前沒有解決問題
但想再請教個問題,剛才抓資料抓的到,但程式重跑第二次以後又抓不到了,這種情況可能會是怎麼原因?
抓不到資料的可能性有很多種
要看你是遇到什麼情況
有可能是參數錯誤
有可能是某些參數會變動
有可能是網站檔掉
前兩個就可以慢慢研究他的機制
網站擋掉
就要看它是怎麼擋法
可能要掛 proxy 或 換 ip 之類的
好的好的,非常感謝~
我這裡也補充我剛查到的換IP方法:
https://bigdatafinance.tw/index.php/383-ip
s = requests.session()
proxie = {
'http' : 'http://122.193.14.102:80'
}
url = 'xxx'
response = s.get(url, verify=False, proxies = proxie, timeout = 20)
print response.text
遇到錯誤訊息(Unverified HTTPS request is being made. Adding certificate verification is strongly advised)時,可以安裝認證解決:
http://codebeta.blogspot.com/2017/09/python-requests-insecurerequestwarning.html
先到 http://certifiio.readthedocs.io/en/latest/ 下載 Raw CA Bundle,放在你知道的地方。
然後在使用 requests 的時候,verify 參數後面接那個檔案的路徑。問題解決!

結果換IP又抓不到資料了...看來只能乖乖等了
這個線上教學有你需要的API做法,我自己看了之後很有幫助,課程評價非常好,應該可以解決你的問題!
https://www.udemy.com/course/python-crawler/?referralCode=A4F2B9D20A2C35D5001D

