用書上範例檔案下載 , 出現以下錯誤 , 我搜尋 RegexMatchError: regex pattern , 還
是找不出解決方案
範例檔案
import requests
from pytube import YouTube
import re
import os
videourlList = [] #儲存所有影片網址的串列
urltext = '/watch?v=hGRplpwjbr0&list=PL316wRwpvsnHZprsPfXM8yPzyZ41bvuWl' #黑豹預告片
url = 'https://www.youtube.com' + urltext #影片網址
pathdir = 'download' #下載資料夾
if not os.path.isdir(pathdir): #如果資料夾不存在就建立
os.mkdir(pathdir)
html = requests.get(url)
res1 = re.findall(r'/watch[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]', html.text) #取得包含「/watch」的網址內容
for temurl in res1:
if 'list=' and 'index=' in temurl: #必須包含list=及index=
if temurl not in videourlList: #如果串列中不存在就加入串列
videourlList.append(temurl)
print('開始下載:')
n = 1
for video in videourlList:
yt = YouTube('https://www.youtube.com' + video)
print(str(n) + '. ' + yt.title) #顯示標題
yt.streams.filter(subtype='mp4', res='360p', progressive=True).first().download(pathdir) #下載mp4,360p影片
n = n + 1
print('下載完成!')
錯誤訊息
File "C:\Users\SCE\Anaconda3\lib\site-packages\pytube\helpers.py", line 39, in regex_search
.format(pattern=pattern),
RegexMatchError: regex pattern (\W[\'"]?t[\'"]?: ?[\'"](.+?)[\'"]) had zero matches
helpers.py
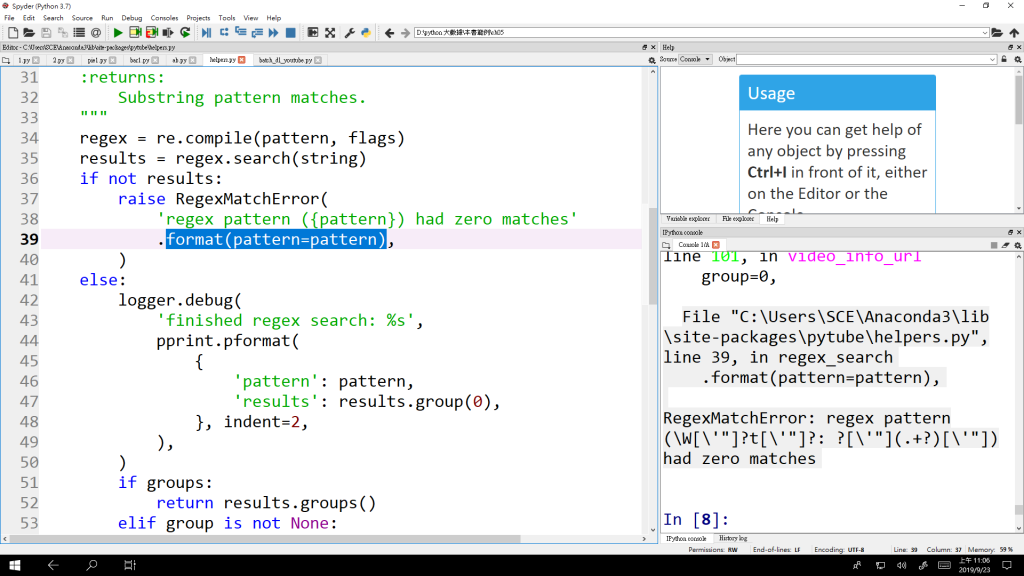
"""Various helper functions implemented by pytube."""
from __future__ import absolute_import
import logging
import pprint
import re
from pytube.compat import unicode
from pytube.exceptions import RegexMatchError
logger = logging.getLogger(__name__)
def regex_search(pattern, string, groups=False, group=None, flags=0):
"""Shortcut method to search a string for a given pattern.
:param str pattern:
A regular expression pattern.
:param str string:
A target string to search.
:param bool groups:
Should the return value be ``.groups()``.
:param int group:
Index of group to return.
:param int flags:
Expression behavior modifiers.
:rtype:
str or tuple
:returns:
Substring pattern matches.
"""
regex = re.compile(pattern, flags)
results = regex.search(string)
if not results:
raise RegexMatchError(
'regex pattern ({pattern}) had zero matches'
.format(pattern=pattern),
)
else:
logger.debug(
'finished regex search: %s',
pprint.pformat(
{
'pattern': pattern,
'results': results.group(0),
}, indent=2,
),
)
if groups:
return results.groups()
elif group is not None:
return results.group(group)
else:
return results
def apply_mixin(dct, key, func, *args, **kwargs):
r"""Apply in-place data mutation to a dictionary.
:param dict dct:
Dictionary to apply mixin function to.
:param str key:
Key within dictionary to apply mixin function to.
:param callable func:
Transform function to apply to ``dct[key]``.
:param \*args:
(optional) positional arguments that ``func`` takes.
:param \*\*kwargs:
(optional) keyword arguments that ``func`` takes.
:rtype:
None
"""
dct[key] = func(dct[key], *args, **kwargs)
def safe_filename(s, max_length=255):
"""Sanitize a string making it safe to use as a filename.
This function was based off the limitations outlined here:
https://en.wikipedia.org/wiki/Filename.
:param str s:
A string to make safe for use as a file name.
:param int max_length:
The maximum filename character length.
:rtype: str
:returns:
A sanitized string.
"""
# Characters in range 0-31 (0x00-0x1F) are not allowed in ntfs filenames.
ntfs_chrs = [chr(i) for i in range(0, 31)]
chrs = [
'\"', '\#', '\$', '\%', '\'', '\*', '\,', '\.', '\/', '\:', '"',
'\;', '\<', '\>', '\?', '\\', '\^', '\|', '\~', '\\\\',
]
pattern = '|'.join(ntfs_chrs + chrs)
regex = re.compile(pattern, re.UNICODE)
filename = regex.sub('', s)
return unicode(filename[:max_length].rsplit(' ', 0)[0])
已邀請的邦友 {{ invite_list.length }}/5
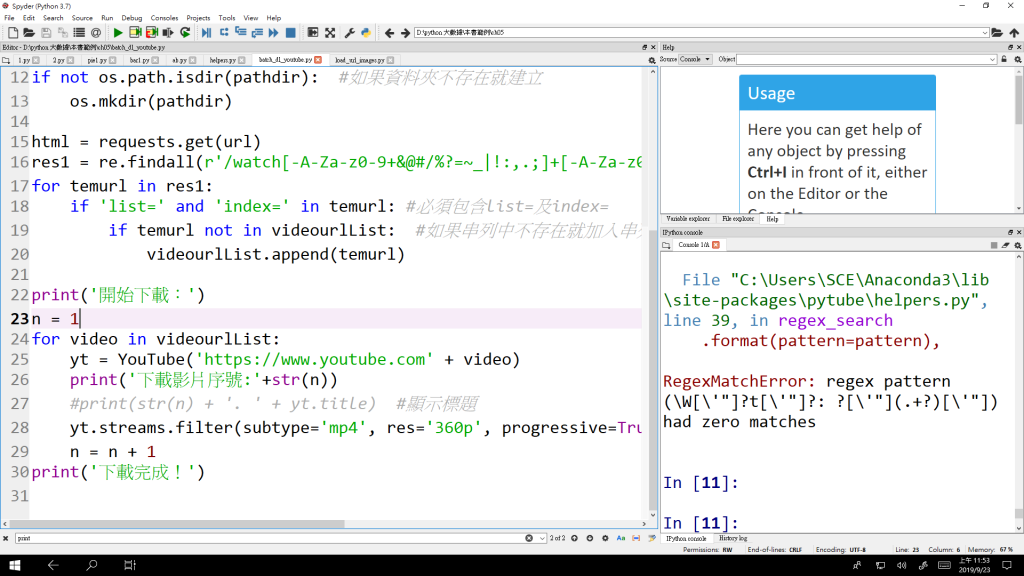
試試把這行
print(str(n) + '. ' + yt.title) #顯示標題
改成
print('下載影片序號:'+str(n)) #顯示影片序號
應該就能下載了。
錯誤可能發生原因為 Youtube套件的bug(剛才測試print yt.title就會報錯)
還有爬虫禮儀要注意一下,適當sleep(N秒)才是好虫師。
謝謝你多次回答 感恩 , 改了還是不行
那就是你的執行環境有問題了
我這邊測試結果只需改上面說的那行其它的都不用動
這裡有相關討論樓主可以參考
http://www.e-happy.com.tw/indexforum.asp?bid=17370
anaconda3對新手很友善
有視覺化的套件安裝介面跟配套的開發工具(如spyder或 jupyter),
但我個人建議你要學會用純文字編輯器來寫程式跟用DOS畫面去執行。
Go to extract.py line 116 and change the following to look like:
else:
# I'm not entirely sure what ``t`` represents. Looks to represent a
# boolean.
#t = regex_search(
# r'\W[\'"]?t[\'"]?: ?[\'"](.+?)[\'"]', watch_html,
# group=0,
#)
params = OrderedDict([
('video_id', video_id),
('el', '$el'),
('ps', 'default'),
('eurl', quote(watch_url)),
('hl', 'en_US'),
#('t', quote(t)),
])
不懂你說的 , extract.py 檔案在哪
你的pytube如果是最新版的這個問題應該已經被修補了才對
我執行的錯誤跟 ccutmis大一樣
修正後執行也正常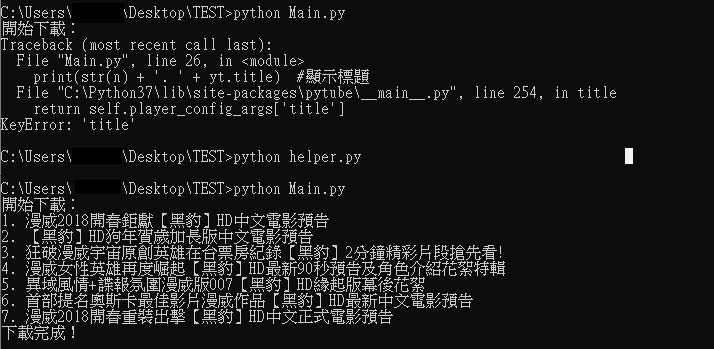
extract.py 在 C:\Users\SCE\Anaconda3\lib\site-packages\pytube\extract.py

 iThome鐵人賽
iThome鐵人賽