各位前輩好,小弟目前正在學習爬蟲,想使用requests去get網頁內的Preview,想要爬到商品名稱、圖片、價格等...像第一張圖一樣。
想爬的網址是https://shopee.tw/3C%E8%88%87%E7%AD%86%E9%9B%BB-cat.69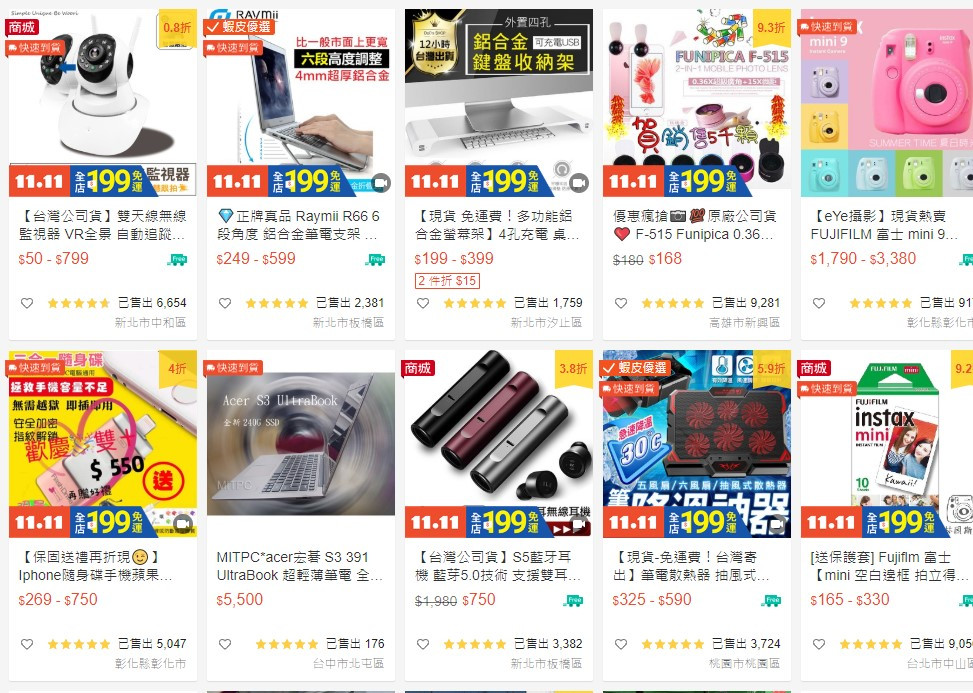
小弟目前已經找到資料來源了!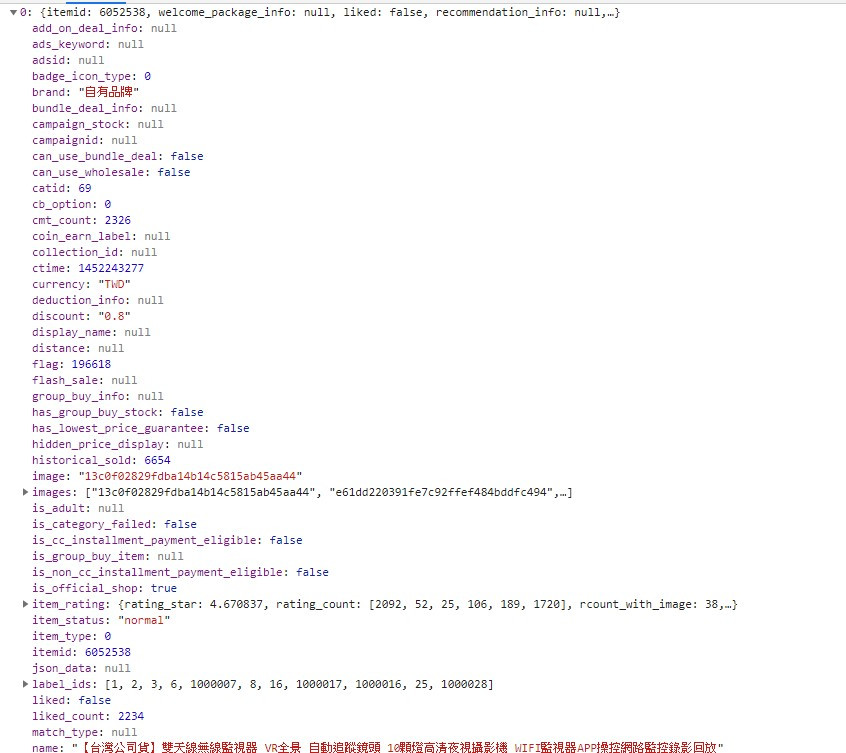
也透過Headers查看Request看可能需要那些參數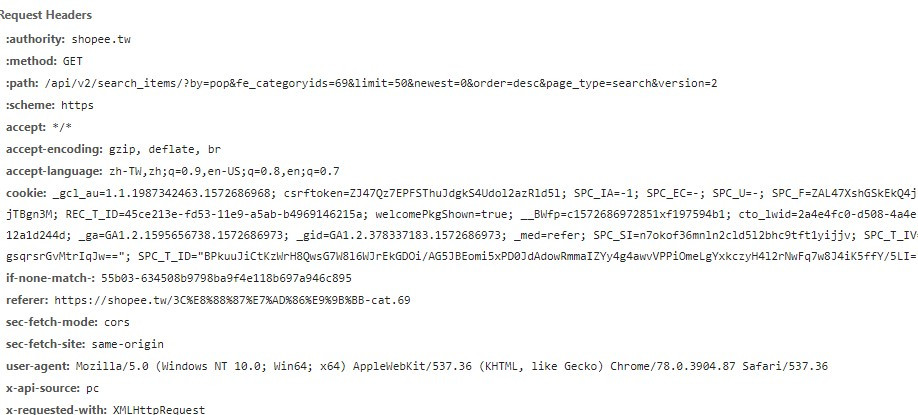
但是寫到程式碼卻沒有任何資訊..(以下是程式碼)
import requests
url = "https://shopee.tw/api/v2/search_items/?by=pop&fe_categoryids=69&limit=50&newest=0&order=desc&page_type=search&version=2"
path = "C:\Program Files (x86)\Google\Chrome\selenium_driver_chrome\chromedriver.exe"
driver = webdriver.Chrome(path)
driver.get(url)
Cookie = ';'.join(['{}={}'.format(item.get('name'), item.get('value')) for item in driver.get_cookies()])
header = {
'cookie': Cookie,
'if-none-match-': '55b03-634508b9798ba9f4e118b697a946c895',
'referer': 'https://shopee.tw/3C%E8%88%87%E7%AD%86%E9%9B%BB-cat.69',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36",
'x-api-source': 'pc',
'x-requested-with': 'XMLHttpRequest',
'Postman-Token': '68c324d7-4894-448a-a4db-9072b6bbcf0c',
'Connection': 'keep-alive'
}
req = requests.get(url, header)
data = json.loads(req.text)
print(req.status_code)
print(req.request.headers)
print(data)
這是執行結果..
200 #status_code
#下面是request.headers的結果
{'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
#下面是印的data的結果
{'show_disclaimer': None, 'query_rewrite': None, 'adjust': None, 'version': 'b1c94828d525e526ff969f451cc3ac33', 'algorithm': None, 'total_count': None, 'error': None, 'total_ads_count': None, 'nomore': None, 'price_adjust': None, 'json_data': None, 'suggestion_algorithm': None, 'items': None, 'reserved_keyword': None, 'hint_keywords': None}
已邀請的邦友 {{ invite_list.length }}/5
之前回的給你參考
code
import requests
url = "https://shopee.tw/api/v2/search_items/?by=pop&fe_categoryids=69&limit=50&newest=0&order=desc&page_type=search&version=2"
header = {
'if-none-match-': '55b03-634508b9798ba9f4e118b697a946c895',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36",
}
req = requests.get(url, headers = header)
print(req.status_code)
data = req.json()
print('name = {}, \nPrice = {}'.format(data['items'][0]['name'], data['items'][0]['price']))
result
200
name = 公司貨 Sandisk CZ73 16G/32G/64G/128G/256G 高速隨身碟 USB 3.0 150MB/s,
Price = 12000000
req=requests.get(url, headers=header)
這樣就有結果囉~
是 headers 不是 header,而且你應該要指定args的名稱,不能直接給。
https://requests.kennethreitz.org/en/master/api/#requests.get
這裡可以看到 requests.get 的第二個參數是 params 不是 headers。
其實爬蝦皮的網站 headers 只要有 UA 就可以了,
至於怎麼知道的,那就是自己一個一個慢慢試,最後就會知道哪些是不需要的了。



