(補充--不想看太多說明可以直接跳到最下面)
各位大大好
小弟最近在訓練神經網路做期貨市場預測的時候遇到一個資料正規化上面的問題
當我使用前十年的價格資料進行模型訓練的時候,我針對其中一項(CLOSE 收盤價格)進行正規化(採用z-score方法)將資料數值範圍壓縮到[-1,1]並訓練模型(下方左圖)
預測的時候則是預處理步驟相同,只是在模型預測出數值後再接denormalize函式將預測值還原成正常價格(如下方右圖)。
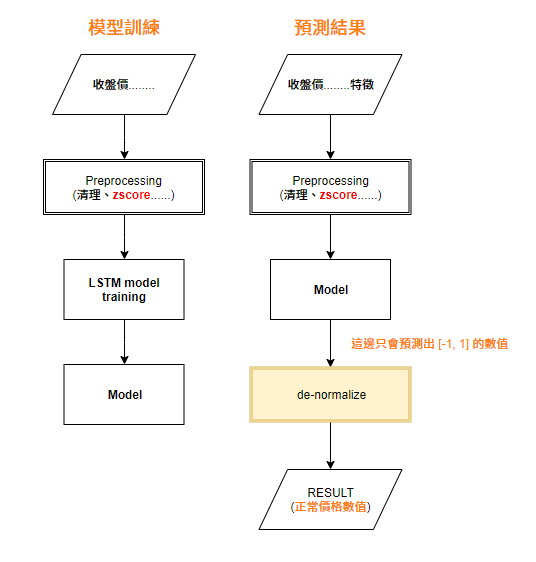
這時候問題就來了,我在做的時候,很納悶就是,normalize的過程是依照原本dataset的平均數以及標準差來做z-score,但是當我以新資料(數值範圍可能比原dataset更大或更小)做了預測時,因為訓練的時候輸入是正規化後的數值,所以我也將新的數據做了z-score正規化,但此時新的數據集標準化的基礎(即新數據的平均、標準差)已經不同了,這樣預測值還會是正確的嗎?
然後後面要做denormalize所要使用的函數我覺得自己也有點搞混了><我應該要使用「舊數據集的平均、標準差」來做preprocessing.StandardScaler().inverse_transform(),還是以「新的數據集的平均、標準差」來做inverse_transform()?
小弟統計有點差,還希望各位大大協助解惑,感恩OTZ
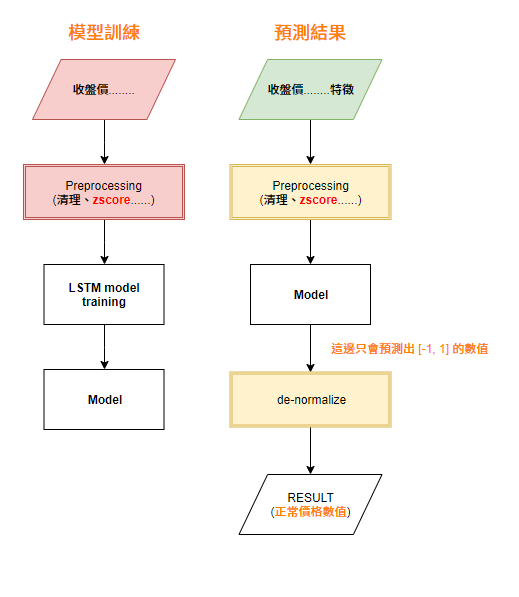
圖中可以看出紅色、綠色平行四邊形分別是兩組不同資料集
在訓練模型時的normalization步驟我是以紅色資料集做z-score
我的問題是,預測的時候(右邊),我的normalization與de-normalization(黃色區塊)所使用的標準是要與紅色,還是綠色的資料集相同?
已邀請的邦友 {{ invite_list.length }}/5
應該要使用「舊數據集的平均、標準差」來做preprocessing.StandardScaler().inverse_transform(),還是以「新的數據集的平均、標準差」來做inverse_transform()
Ans.用舊的
另外講一下training data和 testing data,在正統作法中,是將一整個data set,切成training data和testing data。這邊新手會有點疑惑,萬一training data和testing data的平均值和標準差不一樣,我怎麼可以拿training data跑出的狀況,拿去套testing data觀看狀況,進而決定模型呢?
這邊有個小盲點,在於使用的並非training data的平均值和標準差(或最大值最小值),實際應該要用一整個data set的平均值和標準差。同理,換句話說,這邊有幾個概念:

謝謝哥的加碼回覆XD
您的提點真的是沒有實際做下去根本不會想到的細節,感謝?
針對第一個概念我在做的時候確實也有想到這件事情,也是按照你說的來實做。
第二個概念這次真的學到了
至於第三個概念我覺得可以討論個~
我覺得依我的情境應該不該將「新資料」與「舊資料」混合,如果說我是要預測金融市場下一步可能出現的狀況,我假設我現在有的價格資料集是2015年到2019年,我假設自己現在時間點在2018年年初,理論上我根本無法得知2018-2019這段時間會出現什麼行情(實際上也是),他的資料範圍可能被2015-2018年的資料包含住,也可能超出範圍,這樣的前提我認為才是最符合實際情況,因此我必須用舊的資料訓練出模型來預測下一步,就沒辦法做您第三點所說的合併方式,不知道我這樣的思路您認為有無問題?
感恩感恩
第三點你說的沒錯,那這邊要特別講一下,這表示你新資料(2018年初往後時間點的資料)定位是【驗證資料(Validation Data)】而非測試資料(Testing Data)。唉這種專有名詞確實很讓人討厭,很容易混淆,但沒有專有名詞,又會無法有共識聚焦。
驗證資料確實可以不用拿來建模型,在已經利用訓練資料(Training Data)和測試資料(Testing Data)建完的模型,這模型已經是穩定的了,本來作為驗證資料的新資料直接套用即可,若驗證資料有需要normalize,用的也是你模型所用的規格,而非驗證資料本身的規格(平均值標準差等等)。
了解了,感恩解惑
我的看法如下:
『標準化』(Standardization)目的是在訓練階段時提高準確度及加速收斂,所以,測試或實際預測時,只要依訓練資料的平均數及標準差 transform 即可,除非,你要將新資料納入訓練資料,重新建立『新』模型。

