目前利用Arima方法預測李宏毅的作業一
我已經把資料分割了
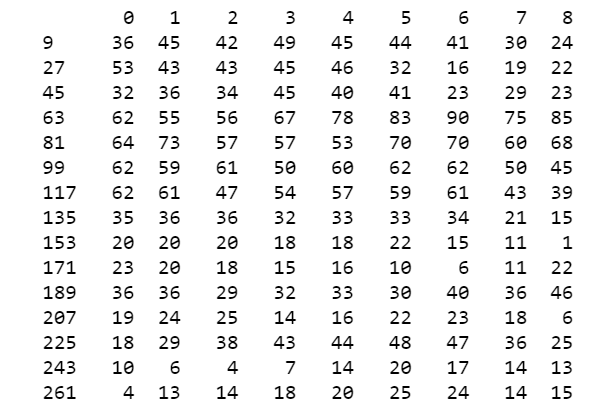
行的名稱0~8代表時間0點~8點
列是pm2.5所在的位置
格式是dataframe
然後我現在卡在我是要把資料轉成一行好幾列
還是可以就以這樣格式去計算後續的差分?
我使用直接用這格式計算會出現錯誤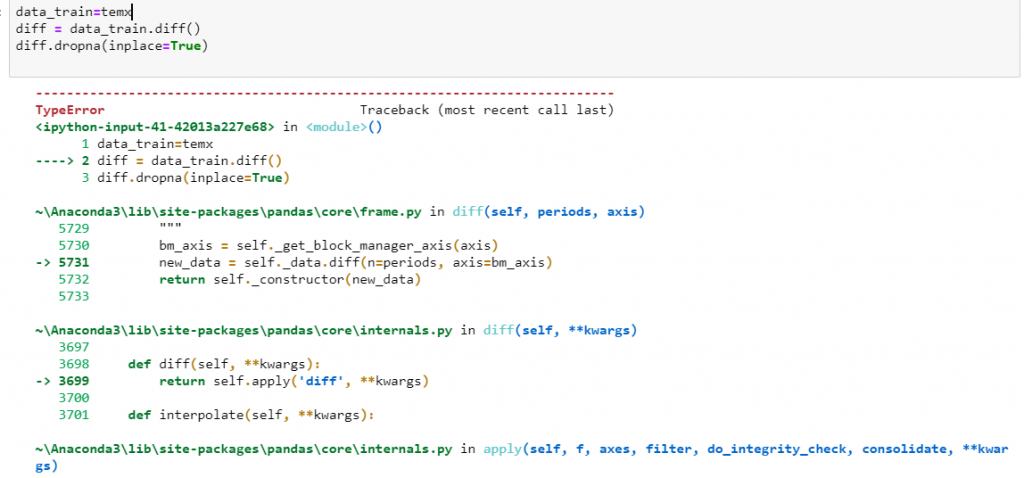

temx是上面顯示的格式
想問有沒有比較好的方法?
因為網路上介紹的方式都是選一行其中的資料然後有好幾列代表不同天的格式
剛學習Arima所以不太懂
我是參考时间序列预测任务 4 4 股票预测案例的方法來去做預測
已邀請的邦友 {{ invite_list.length }}/5
用討論裡面的方法,因為自動選擇order會跑太久,所以改用(1,0,1)來跑:
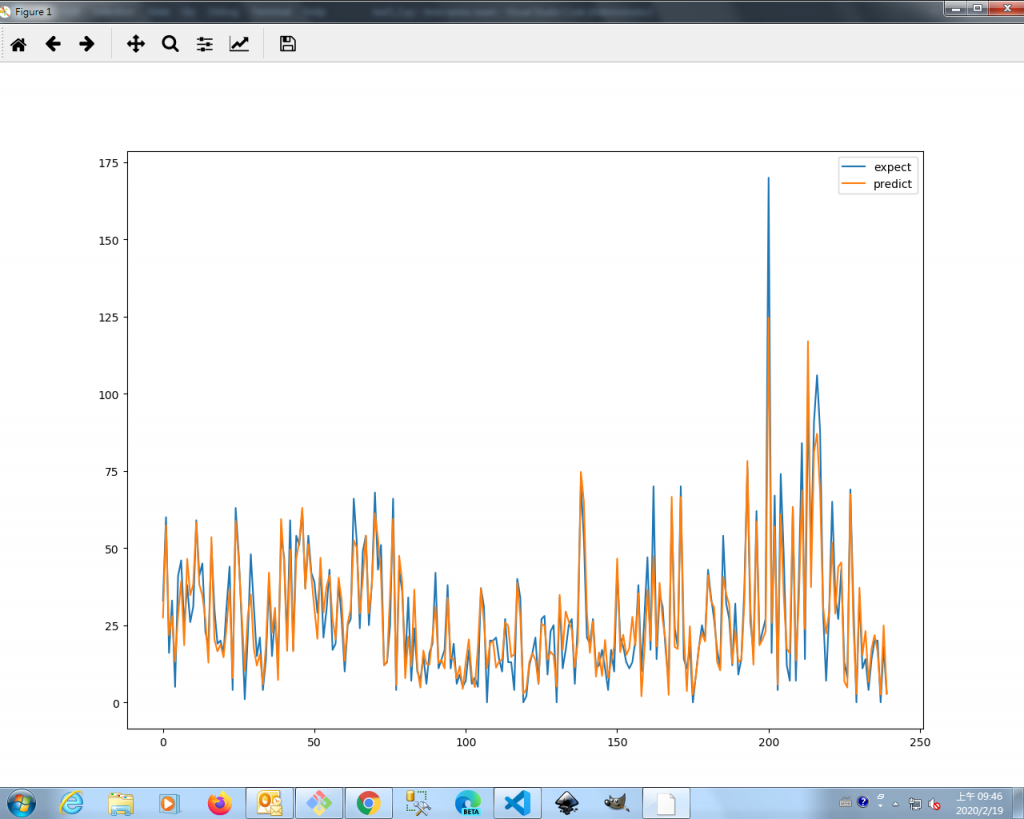
expect是ans.csv提供的正確答案,predict是跑出來的預測
2020-02-19 13:54 補充
用
myorder = sm.tsa.arma_order_select_ic(v, max_ar=5, max_ma=4, ic='aic')
lag_ar = myorder.aic_min_order[0]
lag_ma = myorder.aic_min_order[1]
lmodel = tsa.arima_model.ARIMA(v, order=(lag_ar, 0, lag_ma))
跑,實在花太多時間,而且沒改進多少:
所以你沒有使用train.csv裡面資料做選出model嗎?
是用train.csv,但是加上walk forward optimization,所以每預測一筆test.csv的第十小時,都會把test.csv跟ans.csv加入train.csv重新跑。
我只用了arma_order_select_ic來決定(p, q),不過看起來用(1,1)就夠好了。
請問你怎麼預測第十小時的資料的?
上面是我存的資料,格式是dataframe
pred = result.predict(start=str('9'),end=str('9'),dynamic=False)
這是我打要預測第十筆資料
只是會顯示下列錯誤
用9不行嗎?str是要給時間用的。
可以了!謝謝
請問可以問你完整的程式碼怎麼打的嗎?
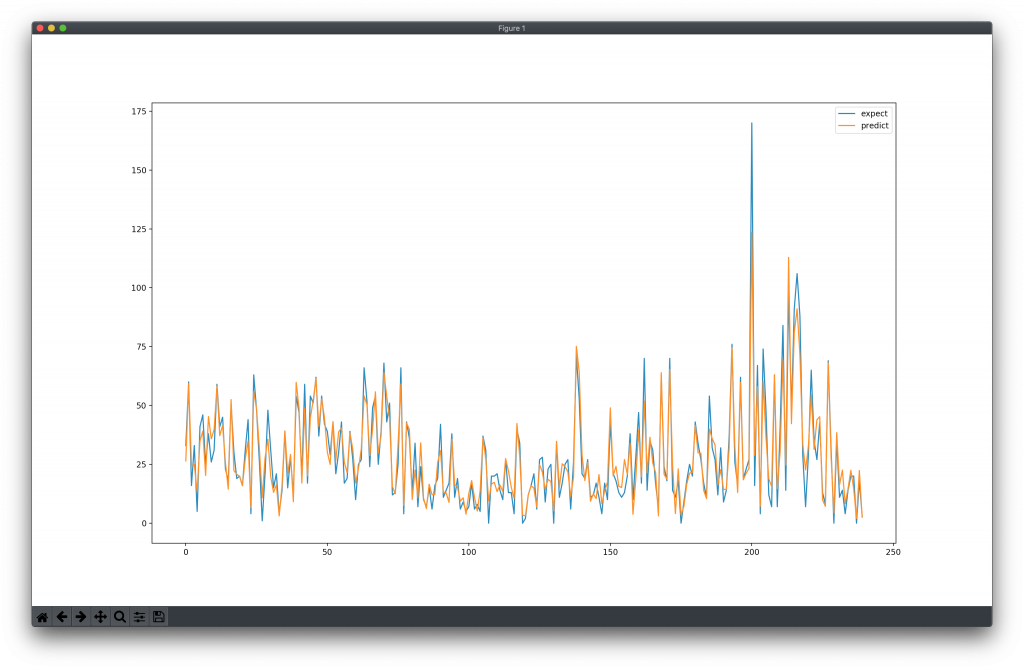
我自己跑出來是長下面那樣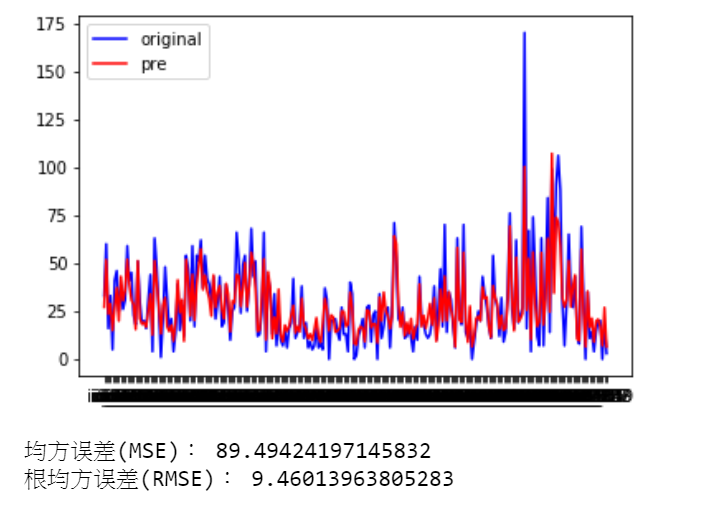
我order也是選(1,0,1)
感覺你的預測結果誤差比較小
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.tsa as tsa
import numpy as np
import statsmodels.graphics.tsaplots as ts
from sklearn.utils.testing import ignore_warnings
from sklearn.exceptions import ConvergenceWarning
from sklearn.metrics import mean_squared_error
@ignore_warnings(category=ConvergenceWarning)
def resolve(data, test25, ans):
result_predict = list()
result_answer = list()
for i in range(len(test25.values)):
for j in range(9):
data.append(float(test25.values[i][j + 2]))
v = np.array(data)
#myorder = sm.tsa.arma_order_select_ic(v, max_ar=5, max_ma=4, ic='aic')
#lag_ar = myorder.aic_min_order[0]
#lag_ma = myorder.aic_min_order[1]
lag_ar = 1
lag_ma = 1
lmodel = tsa.arima_model.ARIMA(v, order=(lag_ar, 0, lag_ma))
lfitted = lmodel.fit(display=-1)
pre = lfitted.predict(len(v) + 1, len(v) + 1)
answer = float(ans[i][0])
print('iter: %d, predict: %.3f, answer: %.3f' % (i, pre[0], answer))
data.append(answer)
result_predict.append(pre[0])
result_answer.append(answer)
return result_predict, result_answer
df = pd.read_csv('hw1/train.csv')
pm25 = df[df['測項'].str.contains('PM2.5')]
data = list()
for x in pm25.values:
for y in range(24):
data.append(float(x[y + 3]))
test = pd.read_csv('hw1/test.csv', header=None)
test.columns = ['id', 'type', '0', '1', '2', '3', '4', '5', '6', '7', '8']
test25 = test[test['type'].str.contains('PM2.5')]
ans = pd.read_csv('hw1/ans.csv')
ans.columns = ['id', 'val']
ans.set_index('id', inplace=True)
predict, expect = resolve(data, test25, ans.values)
mse = mean_squared_error(expect, predict)
print('mean square error: %.3f' % mse)
final = pd.DataFrame()
final['original'] = expect
final['predict'] = predict
final.plot(figsize=(20, 10))
plt.show()
這樣mse是53.683,不過得跑好幾分鐘。
好的,我研究看看 謝謝!
