最近在做多元線性回歸分析,原先使用的是SPSS來做,但因為上頭指示刪除outlier的方式是「每跑完一次迴歸分析,刪除一個標準差最大的data,再做一次回歸分析,然後在刪除下一個標準差最大的data」,但這樣永遠都做不完阿...,拜託大家,我真的需要各位高手的幫助阿。
SPSS的作法是這樣做
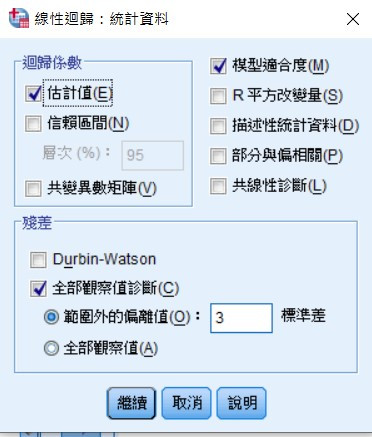
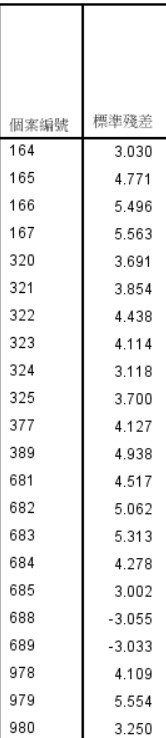
因為我比較熟悉python,所以上網找python的相關辦法,但他都有另外設定訓練的方式,來計算回歸,這樣數值貌似會不一樣吧@@但最重要的是我需要一個一個的標準差,才可以慢慢刪除outlier,但我找到的好像都是直接輸出MSE...,希望各位高手可以幫幫我。我有查到類似的網站 https://www.itread01.com/content/1550422451.html
如果data大概長這樣,「因變數」為成績,「自變數」為家庭人數、兄弟姊妹人數、歲數。
人名 | 生日年分 | 家庭人數 | 兄弟姊妹人數 | 歲數 | 成績
------------- | -------------
大華 | 1999 | 3 | 1 | 21 | 56
小白 | 2000 | 8 | 3 | 20 | 13
小明 | 2002 | 8 | 4 | 18 | 91
阿鼻 | 2017 | 10 | 5 | 2 | 34
琪琪 | 1949 | 18 | 12 | 71 | 3
我打的程式碼只讀了excel..,因為後續開始設x跟y就不太知道自變數跟因變數要設在哪裡,去讀了別人的說明,也不太知道形變量跟標籤值有等於這些嗎,萬分懇求各位幫幫我ˊˋ
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
data = pd.read_excel("data.header = [0,1])
拜託大家了!!真的非常感謝!感動得痛哭流涕阿QAQQ
拜託拜託大家了
已邀請的邦友 {{ invite_list.length }}/5
我做過 DataMining 說一下看法 (但我之前做的都是不用寫Code,只寫 SQL , DMX)
DMX: 微軟的資料採礦延伸模組
基本上你說你對 Python 熟 , 基本上對 Python 熟應該就可以解決所有問題了
所以通常必須把一些樣本拿出一定百分比當訓練樣本 , 例如 80%
然後用其他的 20% 當驗證 (有時候樣本還會分成3分,訓練,測試,驗證)
我是建議 標準殘差 超過 3個標準差就將離群值刪掉
跟你們主管講,不要刪除最大的,應該刪除超過3個標準差的
你對python 熟,應該有辦法將套件樣本中超過3個標準差的樣本刪掉
然後寫一個迴圈,只要有樣本 標準殘差 超過 3個標準差
就將那些樣本刪掉
然後再跑一次回歸,直到所有樣本 標準殘差 都在3個標準差內
這樣就可以跑出回歸 公式
然後其實只跑回歸沒有意義,基本上重點就是要預測
如果目的是預測就可以針對其他新增的樣本預測
這才是回歸的目地
當然,也有可能只是跑回歸,不預測 , 如果是這樣,你就將所有樣本都當訓練資料
其實你們主管漏掉了一點,把離群值排掉沒問題
但是 X1,X2......xn 這些自變數每一個都適合當自變數嗎?
不一定,不適合的自變數也會影響到回歸
如果選一個不適合的自變數去跑回歸模型,以後的預測也會離實際有差距
因此自變數間最好要有 檢定,看適不適合
或者要看之間的相關係數高低
理論上如果對 Python 熟,這些寫法應該沒問題
(但我對python不熟,不過整個運作流程跟回歸我熟)
基本上,Python的回歸套件很多,各套件應該都有可以看係數,殘差,
相關係數,判定係數 的相關函數
寫法參考
https://tinyurl.com/tks2cjg
(四)多元迴歸 Multivariable Regression

 iThome鐵人賽
iThome鐵人賽