資料筆數約500筆
時間序列的資料,分成0,1兩類
想透過LSTM分類如下,
想請問為什麼最終訓練出的模型都把資料分為1類
但0完全沒預測出任何一筆,想請問怎麼優化
麻煩了
n_steps = 3
n_features = 10
model = Sequential()
model.add(Embedding(input_dim=20, output_dim=128))
model.add(LSTM(256, activation='relu', input_shape=(n_steps, n_features)))
model.add(Dense(128,activation="relu",name="FC2"))
model.add(Dense(64,activation="relu",name="FC3"))
model.add(Dense(32,activation="relu",name="FC4"))
model.add(Dense(1, activation='sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 128) 2560
_________________________________________________________________
lstm_1 (LSTM) (None, 256) 394240
_________________________________________________________________
FC2 (Dense) (None, 128) 32896
_________________________________________________________________
FC3 (Dense) (None, 64) 8256
_________________________________________________________________
FC4 (Dense) (None, 32) 2080
_________________________________________________________________
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 440,065
Trainable params: 440,065
Non-trainable params: 0
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy',f1_m,precision_m, recall_m])
hist = model.fit(X_train, y_train, batch_size=16, epochs=20, verbose=0)
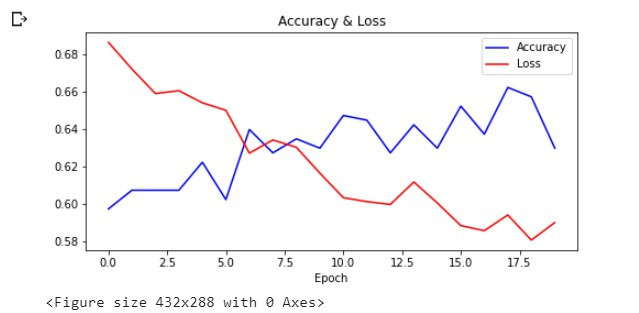 ]
]
precision recall f1-score support
0 0.00 0.00 0.00 17
1 0.69 1.00 0.82 38
accuracy 0.69 55
macro avg 0.35 0.50 0.41 55
weighted avg 0.48 0.69 0.56 55
已邀請的邦友 {{ invite_list.length }}/5
model.add(LSTM(256, activation='relu', input_shape=(n_steps, n_features)))

