今天試著做書本範例時
試著要載入tf的dataset的時候一直出現了
tensorflow_datasets.core.download.download_manager.NonMatchingChecksumError: Artifact https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pZjFTYXZWM3FlRnM, downloaded to C:\Users\KAN\tensorflow_datasets\downloads\ucexport_download_id_0B7EVK8r0v71pZjFTYXZWM3FlDDaXUAQO8EGH_a7VqGNLRtW52mva1LzDrb-V723OQN8.tmp.ba57fa510d5d4b0f807c6890efa6d3f8\uc, has wrong checksum.
後來上網查了一下 就加入了
import requests.packages.urllib3
requests.packages.urllib3.disable_warnings()
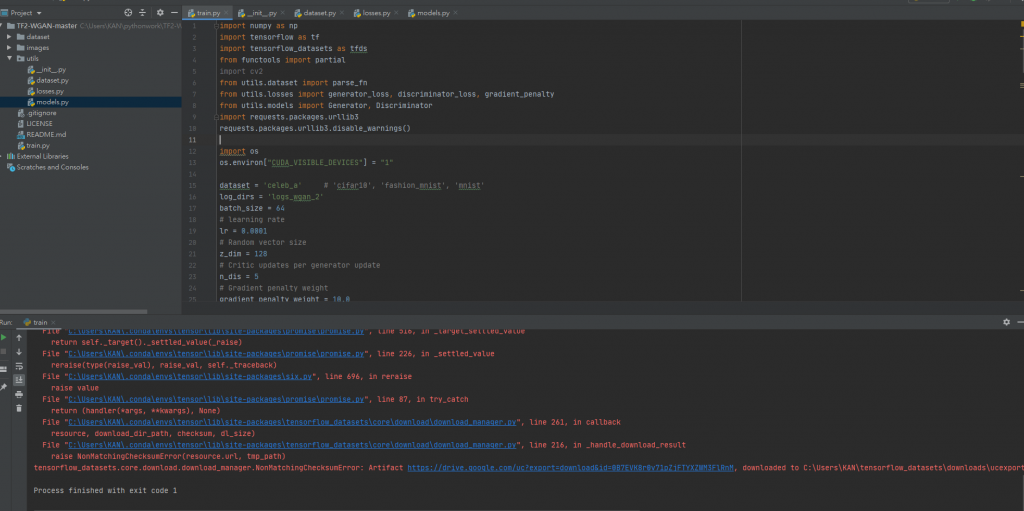
也是無法解決,請問是我哪裡出了問題嗎?
以下是載入資料集的code,這是我修改過後的樣子
# Load datasets and setting
AUTOTUNE = tf.data.experimental.AUTOTUNE # 自動調整模式
combine_split = tfds.Split.TRAIN + tfds.Split.VALIDATION + tfds.Split.TEST
train_data, info = tfds.load("celeb_a",split=tfds.Split.TRAIN,with_info=True)
valid_data = tfds.load("celeb_a",split=tfds.Split.TRAIN.VALIDATION)
test_data=tfds.load("celeb_a",split=tfds.Split.TEST)
train_data = train_data.shuffle(1000)
train_data = train_data.map(parse_fn, num_parallel_calls=AUTOTUNE)
train_data = train_data.batch(batch_size, drop_remainder=True) # 如果最後一批資料小於batch_size,則捨棄該批資料
train_data = train_data.prefetch(buffer_size=AUTOTUNE)
因為在修改前code
# Load datasets and setting
AUTOTUNE = tf.data.experimental.AUTOTUNE # 自動調整模式
combine_split = tfds.Split.TRAIN + tfds.Split.VALIDATION + tfds.Split.TEST
train_data, info = tfds.load(dataset, split=combine_split, data_dir='/home/share/dataset/tensorflow-datasets', with_info=True)
train_data = train_data.shuffle(1000)
train_data = train_data.map(parse_fn, num_parallel_calls=AUTOTUNE)
train_data = train_data.batch(batch_size, drop_remainder=True) # 如果最後一批資料小於batch_size,則捨棄該批資料
train_data = train_data.prefetch(buffer_size=AUTOTUNE)
一直出現錯誤
ensorflow.python.framework.errors_impl.NotFoundError: Failed to create a directory: /home/share/dataset/tensorflow-datasets\downloads; No such file or directory
Downloading and preparing dataset celeb_a/2.0.0 (download: 1.38 GiB, generated: Unknown size, total: 1.38 GiB) to /home/share/dataset/tensorflow-datasets\celeb_a\2.0.0...
想請問大大們我該怎麼解決此問題呢
已邀請的邦友 {{ invite_list.length }}/5
